【C++深度探索】二叉搜索树的全面解析与高效实现

1.二叉搜索树
二叉搜索树(BST,Binary Search Tree)又称二叉排序树,是一种特殊的二叉树,它或者是一棵空树,或者是具有以下性质的二叉树:
- 若它的左子树不为空,则左子树上所有节点的值都小于根节点的值
- 若它的右子树不为空,则右子树上所有节点的值都大于根节点的值
- 它的左右子树也分别为二叉搜索树
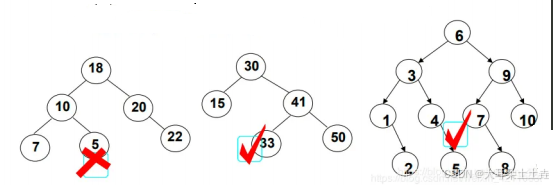
二叉搜索树(Binary Search Tree)的每个节点的左子树中的所有节点都比该节点小,右子树中的所有节点都比该节点大。这个特性使得二叉搜索树可以用来实现非常高效的查找、插入和删除操作。
2.二叉搜索树的功能
二叉搜索树是一种特殊的二叉树,它具有以下功能:
- 插入节点:可以将一个新节点插入到二叉搜索树中。
void TestBSTree()
{
//插入节点
BSTree<string, string> dict;
dict.Insert("insert", "插入");
dict.Insert("erase", "删除");
dict.Insert("select", "查找");
dict.Insert("sort", "排序");
}这里实现的二叉搜索树每次插入的是两个值,模拟键值对,二叉搜索树的节点除了左右子节点指针也不再只存储一个值,而是两个。也就是说当我们知道一个值时,就可以利用它来查找另外一个值。
键值对(key-value pair)是指在计算机科学中用来存储和表示数据的一种结构。它由两部分组成:键(key)和值(value)。键是一个唯一的标识符,用来定位和访问值;值是与键相关联的数据。例如,一个简单的键值对可以表示一个人的姓名和年龄:键是“姓名”,值是“张三”;键是“年龄”,值是“25”。
- 删除节点:可以删除二叉搜索树中的一个节点。
void TestBSTree()
{
BSTree<string, string> dict;
dict.Insert("insert", "插入");
dict.Insert("erase", "删除");
dict.Insert("select", "查找");
dict.Insert("sort", "排序");
//删除节点
dict.Erase("insert");
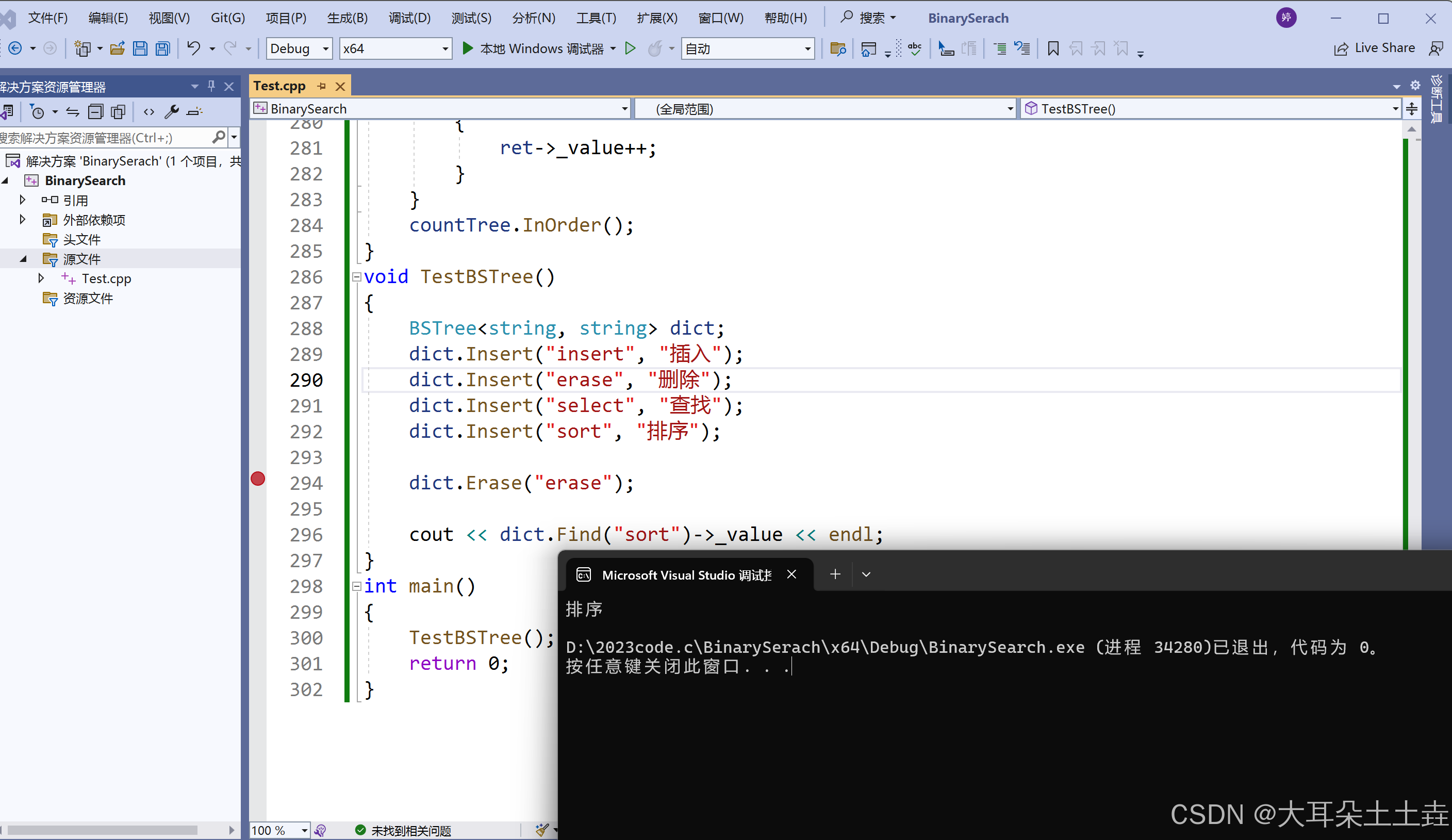
}- 查找节点:可以根据给定的值,在二叉搜索树中查找对应的节点。
void TestBSTree()
{
BSTree<string, string> dict;
dict.Insert("insert", "插入");
dict.Insert("erase", "删除");
dict.Insert("select", "查找");
dict.Insert("sort", "排序");
dict.Erase("insert");
//查找节点
cout<< dict.Find("sort")->_value << endl;
}结果如下:
- 中序遍历的结果是有序的:中序遍历二叉搜索树可以得到一个有序序列。
void TestBSTree()
{
BSTree<string, string> dict;
dict.Insert("insert", "插入");
dict.Insert("erase", "删除");
dict.Insert("select", "查找");
dict.Insert("sort", "排序");
//中序遍历
dict.InOrder();
}结果如下:
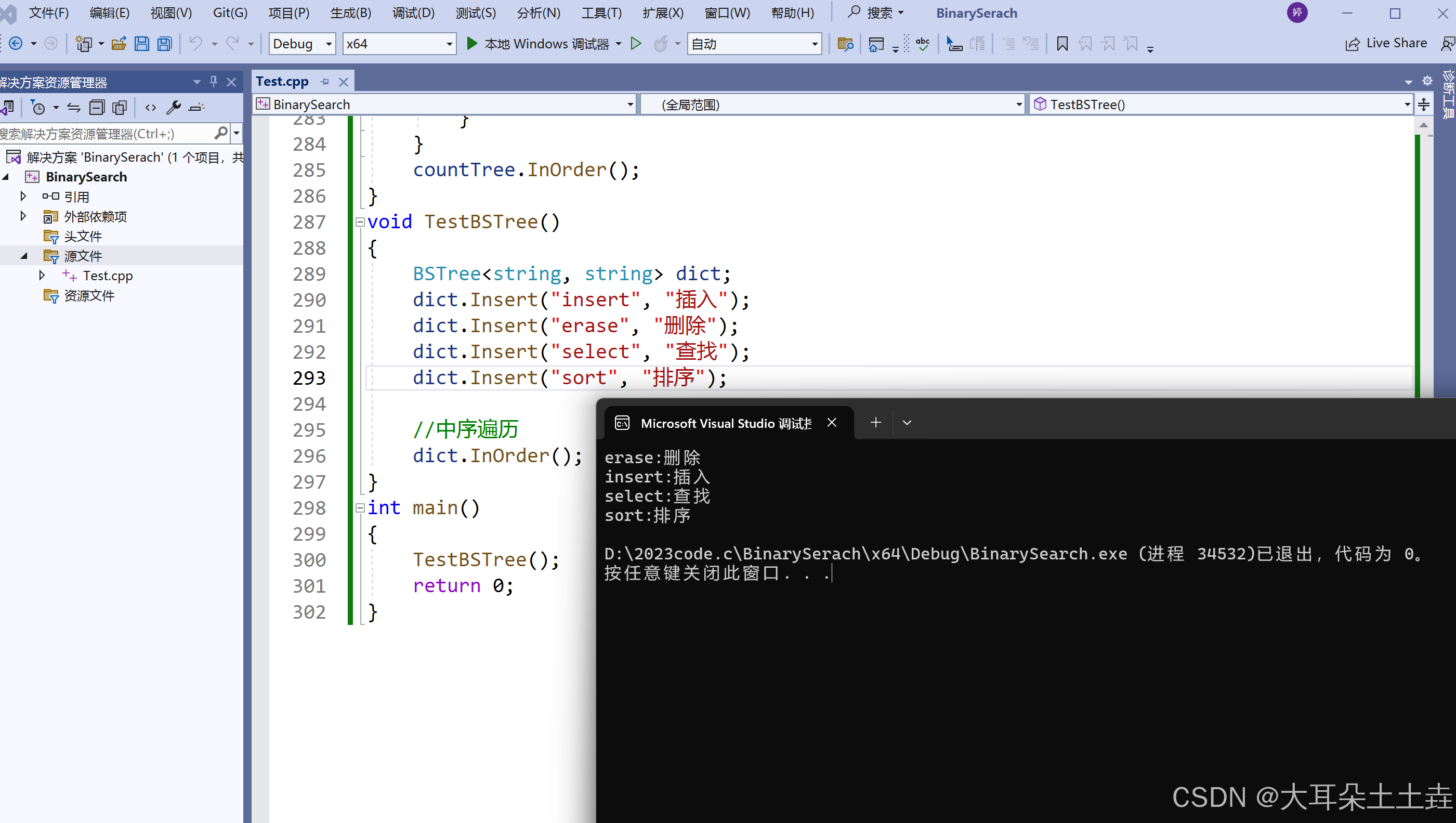
中序遍历的结果按照字符串大小比较的顺序排列。
这些是二叉搜索树的一些基本功能。通过这些功能,可以实现对二叉搜索树的插入、删除、查找等操作,以及对二叉搜索树的遍历和查询。
3.二叉搜索树的实现
二叉搜索树的实现首先需要一个节点类包含节点的键值、左子节点和右子节点三个属性,来存放一个一个的节点:
//节点类
template<class K, class V>
struct BSTreeNode
{
//键值对
K _key;
V _value;
//左右子节点
struct BSTreeNode* _left;
struct BSTreeNode* _right;
//默认构造
BSTreeNode(const K& key = K(), const V& value = V())
:_key(key)
,_value(value)
,_left(nullptr)
,_right(nullptr)
{}
};✨二叉搜索树的结构
template<class K, class V>
class BSTree
{
typedef BSTreeNode<K, V> Node;
public:
bool Insert(const K& key, const V& value);//插入
Node* Find(const K& key);//查找
bool Erase(const K& key);//删除
void InOrder();//中序遍历
~BSTree();//析构
private:
void _InOrder(Node* root);
Node* _root = nullptr;
};测试代码如下:
//测试代码
void TestBSTree()
{
BSTree<string, string> dict;
dict.Insert("insert", "插入");
dict.Insert("erase", "删除");
dict.Insert("select", "查找");
dict.Insert("sort", "排序");
string str;
while (cin>>str)
{
auto ret = dict.Find(str);
if (ret)
{
cout << str << ":" << ret->_value << endl;
}
else
{
cout << "单词拼写错误" << endl;
}
}
string strs[] = { "苹果", "西瓜", "苹果", "樱桃", "苹果", "樱桃", "苹果", "樱桃", "苹果" };
// 统计水果出现的次
BSTree<string, int> countTree;
for (auto str : strs)
{
auto ret = countTree.Find(str);
if (ret == NULL)
{
countTree.Insert(str, 1);
}
else
{
ret->_value++;
}
}
countTree.InOrder();
}✨插入函数Insert()
插入新节点时我们首先需要借助节点的类来构建新节点,然后判断插入二叉搜索树的位置,因为二叉树的左子树的节点总是小于根节点,右子树总是大于根节点,所以不能随便插入,确定好插入位置后将新节点插入到二叉搜索树中。
bool Insert(const K& key, const V& value)
{
//创建新节点
Node* newnode = new Node(key, value);
//当二叉搜索树为空时
if (_root == nullptr)
{
_root = newnode;
return true;
}
//二叉搜索树不为空
Node* cur= _root;
Node* parent = _root;//记录父节点
//遍历节点找到插入位置
while (cur!= nullptr)
{
if (cur->_key > key)
{
parent = cur;
cur= cur->_left;
}
else if (key > cur->_key)
{
parent = cur;
cur= cur->_right;
}
else
{
//相等时,插入失败
return false;
}
}
//判断是插入parent节点的左节点还是右节点
if(key>parent->_key)
{
parent->_right = newnode;
}
else
{
parent->_left = newnode;
}
return true;
}因为二叉搜索树的性质,所以我们只需要比较节点的_key值即可,如果插入的节点的_key值比当前节点大就往当前节点的右子树寻找,反正就往左子树寻找合适的位置,如果相等就插入失败,返回false,因为这里的二叉搜索树不能存储相同的节点。
其次,找到合适位置后,我们还需要记录该位置的父节点,一遍将新节点与二叉搜索树链接在一起,有了插入位置的父节点,然后判断是插入左边还是右边即可完成插入,返回true。
✨查找函数Find()
查找函数其实在插入函数时确定新节点插入的位置就已经实现了类似的逻辑,不同的是如果插入时找到相同的节点则插入失败,而查找时找到相同的节点则查找成功,返回该节点的指针即可。
Node* Find(const K& key)
{
Node* cur= _root;
while (cur!= nullptr)
{
if (cur->_key > key)
{
cur= cur->_left;
}
else if (key > cur->_key)
{
cur= cur->_right;
}
else
{
//相等时,找到了
return cur;
}
}
//这里表示没找到
return nullptr;
}这里使用循环遍历二叉搜索树来查找,当root不为空并且还没有找到时就会一直查找,而当root为空并且还没有找到此时就可以返回空指针,表示当前二叉搜索树不存在要查找的节点。
✨删除函数Erase()
删除函数的逻辑较为复杂一些,首先要查找到删除的节点,没有找到就返回False,如果找到,那么我们需要根据该节点的位置,或者说该节点有几个子节点来实现不同的删除逻辑。
如果被删除的节点没有子节点或是只有一个子节点,都比较容易解决只有把父节点指向该节点的子节点即可,如果没有子节点,则让父节点指向空即可,所以一个节点和没有节点的情况可以综合起来考虑,上述代码为了逻辑清晰分开考虑了,大家也可以根据自己的想法选择。
如果有两个子节点,删除该节点,那他的两个孩子该怎么办呢😱,所以我们应该从其右子树所有节点中选择最小的那一个
minright节点替代被删除的节点root,这样替代后,左子树的所有节点依然小于minright,右子树的所有节点依然大于minright,满足二叉搜索树的性质。当然也可以选择左子树的最大节点maxleft来替代root。替代可以选择交换节点内部的键值也可以直接交换节点的指针,交换键值较容易一些,这里选择交换键值。
bool Erase(const K& key)
{
//没有节点
if (_root == nullptr)
{
return false;
}
//先找到,再删除释放
Node* cur = _root;
Node* parent = _root;//记录父节点
while (cur != nullptr)
{
if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
}
else if (key > cur->_key)
{
parent = cur;
cur = cur->_right;
}
else
{
//找到,判断要被删除的节点有几个子节点
//1.没有子节点
if (cur->_left == nullptr && cur->_right == nullptr)
{
//判断该节点是在父节点的左边还是右边
if (parent->_key > cur->_key)
{
//在左边
parent->_left = nullptr;
delete cur;
}
else if(cur->_key > parent->_key)
{
//在右边
parent->_right = nullptr;
delete cur;
}
else
{
//就是根节点
delete cur;
_root = nullptr;
}
}
//2.只有一个节点
else if (cur->_right == nullptr)
{
//先看只有左节点的情况
//判断该节点是在父节点的左边还是右边
if (parent->_key > cur->_key)
{
//在左边
parent->_left = cur->_left;
delete cur;
}
else if(cur->_key > parent->_key)
{
//在右边
parent->_right = cur->_left;
delete cur;
}
else
{
//根节点
_root = cur->_left;
delete cur;
}
}
//2.只有一个节点
else if (cur->_left == nullptr)
{
//只有右节点的情况
//判断该节点是在父节点的左边还是右边
if (parent->_key > cur->_key)
{
//在左边
parent->_left = cur->_right;
delete cur;
}
else if(cur->_key > parent->_key)
{
//在右边
parent->_right = cur->_right;
delete cur;
}
else
{
//根节点
_root = cur->_right;
delete cur;
}
}
//3.有两个节点的情况
else
{
//先找右边最小的值交换
Node* minright = cur->_right;
Node* pminright = cur;//记录父节点
while (minright->_left)
{
Node* pminright = minright;//记录父节点
minright = minright->_left;
}
//找到后,将minright节点的位置删除
if (pminright->_right == minright)
{
pminright->_right = minright->_right;
}
else
{
pminright->_left = minright->_right;
}
//交换节点的值即可
cur->_key = minright->_key;
cur->_value = minright->_value;
delete minright;
}
return true;
}
}
//没找到,删除失败
return false;
}删除同样需要将删除的节点的父节点与子节点链接起来,所以需要一个parent指针来记录删除节点的父节点,当然如果父节点就是自己,那么表示删除的是根节点,这时我们又要另外考虑。
✨中序遍历InOrder()
中序遍历就可以使用我们学习二叉树时的递归来实现,非常简单。
void InOrder()
{
_InOrder(_root);
}
void _InOrder(Node* root)
{
if (root == nullptr)
{
return;
}
_InOrder(root->_left);
cout << root->_key << ":" << root->_value << endl;
_InOrder(root->_right);
}这里因为递归需要传递根节点的参数,而我们在使用时
_root是私有的,我们没办法直接传参,所以我们可以在类中嵌套一层函数,将需要传参的函数设为私有,这样对外我们就不需要再传参了。
✨析构函数
析构函数也直接使用递归删除节点即可,但是注意要使用后序遍历,最后释放根节点,如果先释放根节点会找不到子节点,会报错。
~BSTree()
{
_Order(_root);
}
private:
void _Order(Node* root)
{
if (root == nullptr)
{
return;
}
_Order(root->_left);
_Order(root->_right);
delete root;
}4.二叉搜索树的应用
- 比如英汉词典就是英文与中文的对应关系,通过英文可以快速找到与其对应的中文,英文单词与其对应的中文<word, chinese>就构成一种键值对;
void TestBSTree()
{
BSTree<string, string> dict;
dict.Insert("insert", "插入");
dict.Insert("erase", "删除");
dict.Insert("select", "查找");
dict.Insert("sort", "排序");
//dict.InOrder();
string str;
while (cin >> str)
{
auto ret = dict.Find(str);
if (ret)
{
cout << str << ":" << ret->_value << endl;
}
else
{
cout << "单词拼写错误" << endl;
}
}
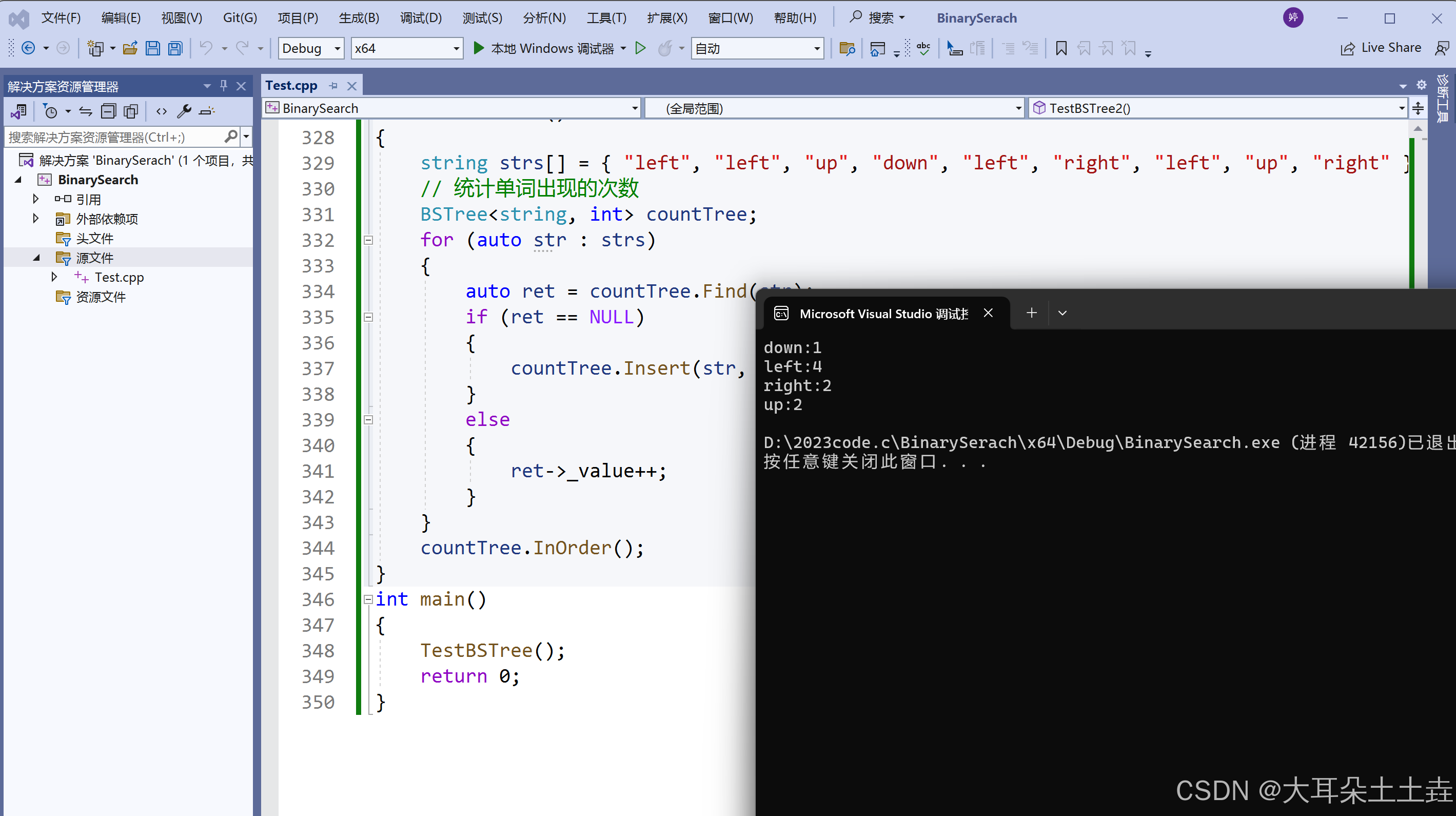
}- 再比如统计单词次数,统计成功后,给定单词就可快速找到其出现的次数,单词与其出现次数就是<word, count>就构成一种键值对
void TestBSTree()
{
string strs[] = { "left", "left", "up", "down", "left", "right", "left", "up", "right" };
// 统计单词出现的次数
BSTree<string, int> countTree;
for (auto str : strs)
{
auto ret = countTree.Find(str);
if (ret == NULL)
{
countTree.Insert(str, 1);
}
else
{
ret->_value++;
}
}
countTree.InOrder();
}结果如下:
5.二叉搜索树的性能分析
插入和删除操作都必须先查找,查找效率代表了二叉搜索树中各个操作的性能。 对有n个结点的二叉搜索树,若每个元素查找的概率相等,则二叉搜索树平均查找长度是结点在二 叉搜索树的深度的函数,即结点越深,则比较次数越多。 但对于同一个关键码集合,如果各关键码插入的次序不同,可能得到不同结构的二叉搜索树:
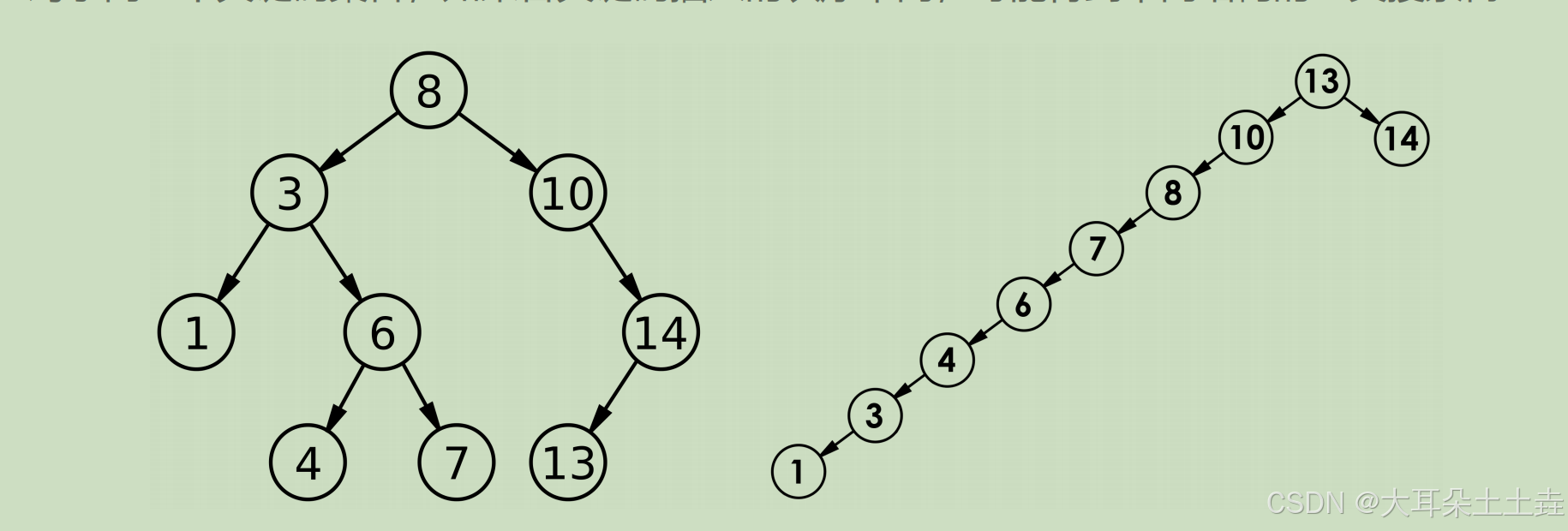
最优情况下,二叉搜索树为完全二叉树(或者接近完全二叉树),其平均比较次数为:
最差情况下,二叉搜索树退化为单支树(或者类似单支),其平均比较次数为:
6.结语
二叉搜索树可以帮助我们实现排序和去重,但是需要注意的是,二叉搜索树的性能取决于树的形状。如果树的形状接近于链表,性能可能会下降,最坏情况下时间复杂度可能达到O(n),其中n为树中的结点数。为了避免这种情况,可以采用平衡二叉搜索树(如AVL树、红黑树等),保持树的平衡性,从而提高操作的效率。以上就是今天所有的内容啦~ 完结撒花~ 🥳🎉🎉
腾讯云开发者
