【源头活水】ICML2024:如何突破Transformer上下文学习中的瓶颈?

【源头活水】ICML2024:如何突破Transformer上下文学习中的瓶颈?

马上科普尚尚
发布于 2024-07-30 14:08:26
发布于 2024-07-30 14:08:26
简介
上下文学习,即从上下文示例中学习,是Transformer一项令人印象深刻的能力。然而,由于学习瓶颈的出现——在训练过程中模型的上下文学习能力几乎没有或没有提升的时期——训练Transformer具备这种上下文学习技能是计算密集型的。为了研究学习瓶颈背后的机制,我们在概念上将模型内部表征中一个完全受模型权重影响的组件分离出来,称之为“权重组件”,其余部分被识别为“上下文组件”。通过在合成任务上的精细和受控实验,我们注意到学习瓶颈的持久性与权重组件功能受损相关。认识到权重组件性能受损是推动学习瓶颈的基本行为,我们开发了三种策略来加速Transformer的学习。这些策略的有效性在自然语言处理任务中得到了进一步确认。总之,我们的研究表明,在AI系统中以环保方式培养强大的上下文学习能力是可行的。
论文地址:https://arxiv.org/pdf/2309.06054
AITIME
01、In-context Learning
上下文学习(in-context learning),即在提供一些上下文示例的情况下,期望网络模型能够通过这些示例学到相关信息,并应用于下游任务的预测。具体来说,在给定上下文示例和一个提示的前提下,希望模型能够准确地预测相应的结果。
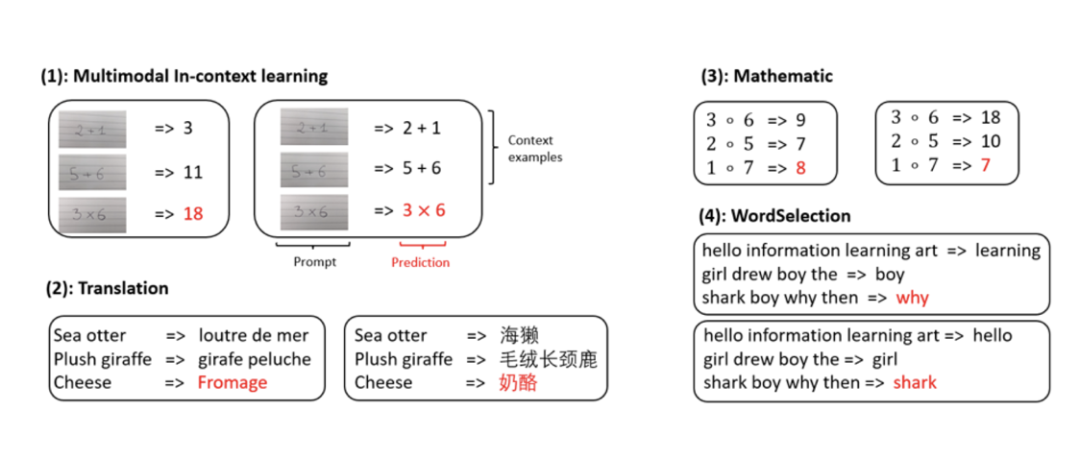
作者通过几个实例来展示这种能力:对于同一张输入图片,在不同的上下文示例下,模型的应对方式会自适应地有所不同。例如图(1),左侧的图片展示了计算结果,而右侧的图片则仅用于光学字符识别(OCR)。在文本翻译任务中,相同的文本在不同的上下文示例下,可以实现从英语到法语或从英语到中文的翻译。因而,上下文学习的核心在于期望模型能够通过提供的上下文示例,自适应地学习并调整其对给定输入的预测。
AITIME
02、Learning Plateaus
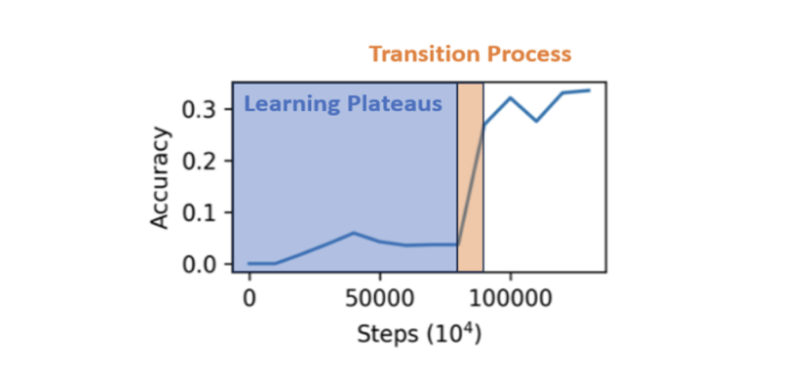
在研究了Pythia 13B模型的训练过程后,作者发现其学习准确性呈现出一种模式:在训练初期,模型的损失和性能基本不变,这段时期被称为“学习瓶颈期”(Learning Plateaus)。随后,模型性能会快速提升,这称为“过渡过程”(Transition Process)。本文的研究目标是探究导致学习平台期的因素,以及寻找可能的方法来缩短这段延迟期。
AITIME
03、Weights component and context component


AITIME
04、Synthetic Task
基于上述思路,作者设计了一个合成数据集来进行实验。由于在真实数据上分析非常困难,影响因素众多且难以控制,我们在可控环境下观察模型的表现。
具体而言,先为每张图片生成嵌入,并根据对应的标签进行预测。例如,在第一组数据中,希望模型预测物体的颜色;在第二组数据中,希望模型预测物体的形状。这样,当给定新数据时,模型应能自动调整其输出,例如预测出绿色或方形。
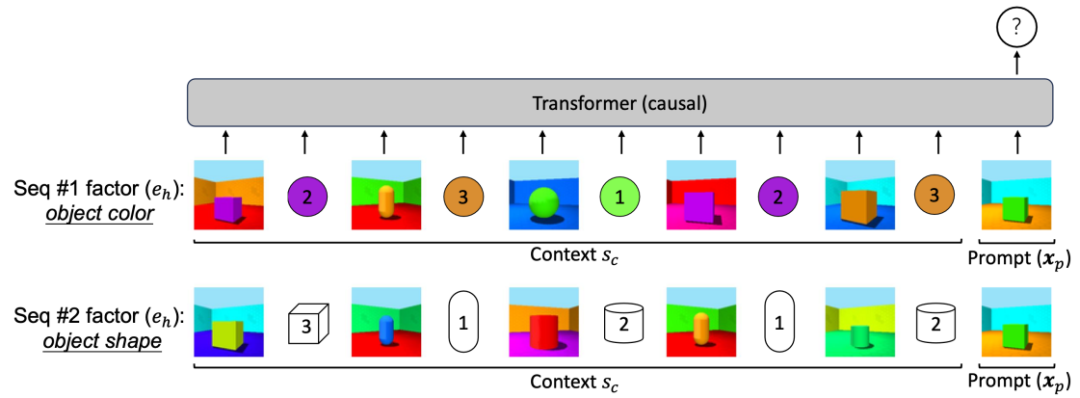
实验结果显示,这种合成任务能够完美复现之前在Pythia 13B中观察到的现象,包括学习平台期和性能提升的过渡期。通过这种方法,可以更清楚地理解和优化上下文学习过程中不同因素的影响。
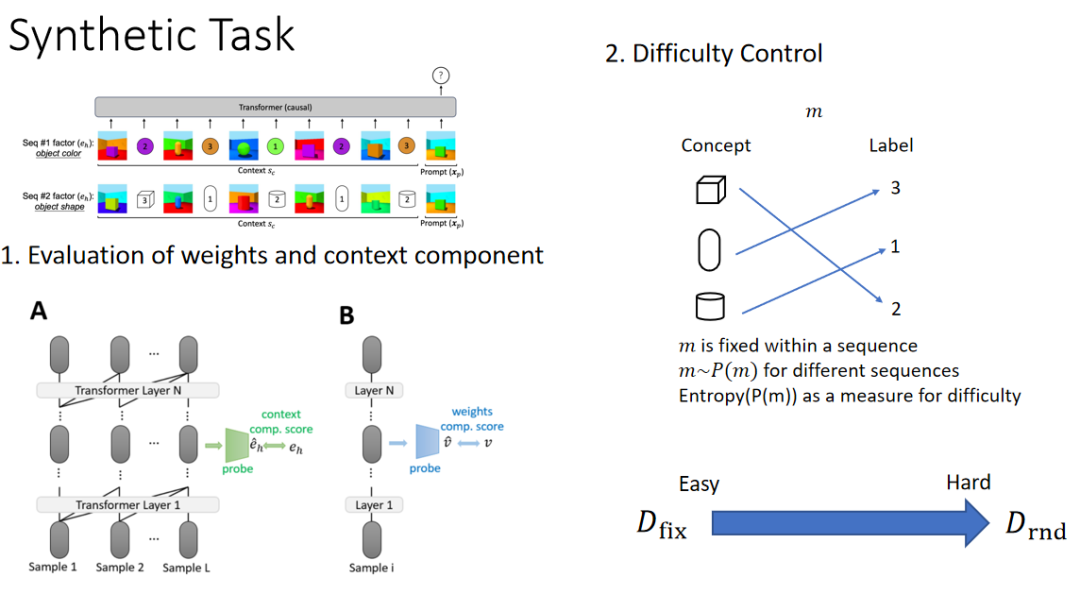
之前的研究仅从概念上对上下文学习过程的两个关键部分分解,但并未在物理上中实现。本文采用探测方法,通过观察中间表征来分析这两个部分。
对于“weights component”部分,不提供上下文示例,因为只期望观察在没有上下文示例情况下性能受影响的部分如何表现。通过不提供上下文示例进行探测,检查其中特征是否包含足够的语义信息,例如是否能预测形状、颜色等。
对于“context component”部分,预测它是否能够学习并识别当前任务是颜色分类还是形状分类。


AITIME
05、Mechanism behind Learning Plateaus
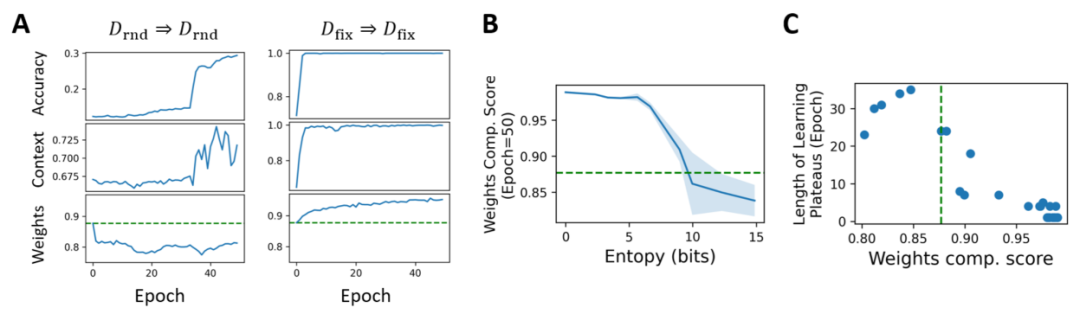
在实验中,作者发现了一个有趣的现象:在处理最简单任务时,weights component在训练过程中持续上升。然而,当任务难度增加时,weights component却开始下降。相较而言,context和accuracy等其他指标则整体呈现上升趋势,特别是在简单任务中上升更快。显然,weights component的趋势与其他指标不同,它在简单任务中上升,而在困难任务中下降。
基于这个发现,作者进一步研究了整个难度区间内的weights component变化情况。在50个epoch时,作者观察到,随着任务难度的增加,weights component逐渐下降。尤其是在任务难度达到一定程度后,weights component的值甚至低于初始值。文中将这一现象描述为weights component的“失能”(disfunction)。
此外,本文还研究了weights component与learning plateau长度之间的关系。发现当weights component低于初始值时,learning plateau长度显著增加,大约在20到30之间波动。而当weights component高于初始值时,learning plateau长度大多在10以内。这个发现非常有趣,表明weights component的变化对learning plateau长度有显著影响。
AITIME
06、Breaking through the learning plateaus
本文为探究weights component的存在及其与学习表现的关系设计了三种调整方法试图缓解在上的学习停滞现象。
第一种为使用任务去预热网络,让网络能够学到较好的weights components 之后再转移到上。在简单任务中,我们观察到weights component会上升。由于weights component与上下文无关,因此它在任务难度变化时是共享的,可以互相转移。我们实验结果发现在转换后会出现性能快速快速上升的现象。这个结果表明weights component不仅真实存在,还与学习表现密切相关。通过以上方法,实现对weights component更好的理解和控制,以优化学习过程并缩短learning plateau的长度。
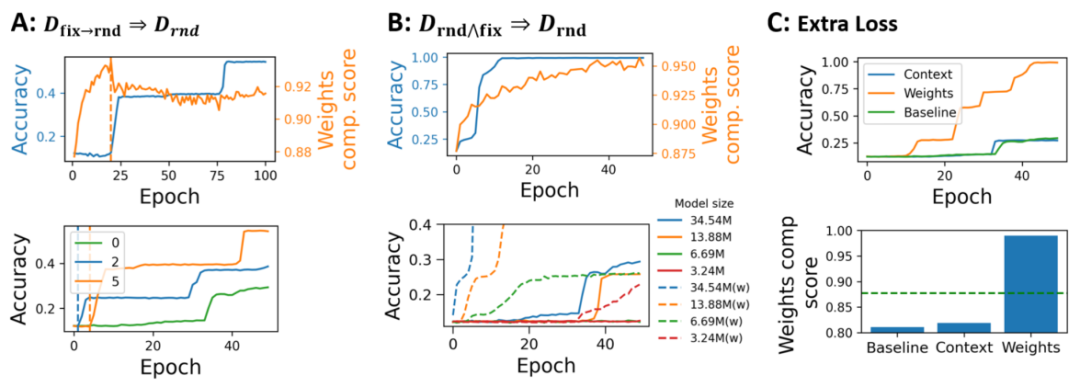
第二种方法采用讲不同难度的集合混合训练的方法。我们发现这样的混合训练策略显著缓解了Learning Plateaus的发生。
接下来,作者首先设计了分别针对weights component和context component的损失函数。发现当试图提升context component时,对学习停滞现象并无显著改善,weights component相对于基准线也没有显著提升。然而,当提升weights component时,它显著缓解了学习停滞的问题。
AITIME
07、Simple Function Task
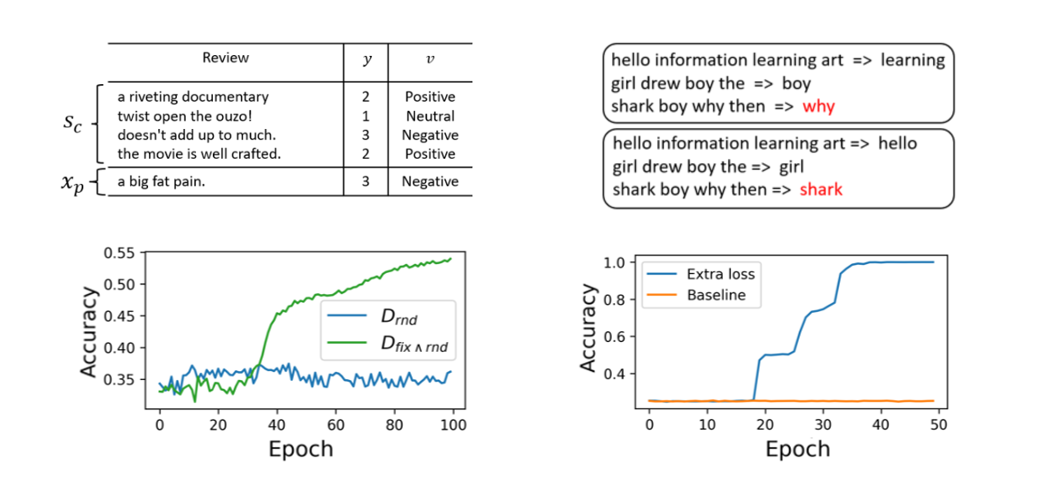
基于这一现象,作者将结论扩展至之前在标准任务中的常见现象,即Simple Function Task。该任务涉及对每个序列采样一个高斯分布的权重,然后采样一个x值,并根据线性函数生成其上下文示例。在训练过程中,先提供上下文示例,再给出一个新的查询,观察模型是否能准确预测对应的y值。

在评估weights component时,文中使用探针方法提取内部表征,观察它是否能回归输入本身。同样,在不提供上下文示例的情况下,观察其是否能自我回归。结果显示,weights component的值越低,表示性能越好。通过调整维度,作者发现当维度超过30时,weights component显著下降。
比较基线和使用实际损失的情况,发现当出现权重组件功能障碍时,额外的提升weights component的损失对准确率的提升非常显著;而在未出现权重组件功能障碍时,提升较为有限。这进一步证实了weights component与整体任务表现之间存在一定程度的因果关系。
AITIME
08、Extend to NLP tasks
在NLP数据集上进行的一系列实验验证了关于weights component和learning plateau的假设确实存在。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-07-29,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号