爬取了《默杀》48240条豆瓣影评,真的有这么烂吗?!

爬取了《默杀》48240条豆瓣影评,真的有这么烂吗?!

老表
发布于 2024-07-31 19:33:12
发布于 2024-07-31 19:33:12
爬取了《默杀》54240条豆瓣影评,真的有这么烂吗?

大家好,我是老表。最近几周《默杀》很火,在各种短视频平台经常刷到宣传片,看着那种校园霸凌咬牙切齿,看到最后反转又喜笑颜开,准备周末去电影院看看,犒劳犒劳帮我上了一周班的身体和大脑,而且我看猫眼上评分也很高,票房也不错,更感兴趣了。
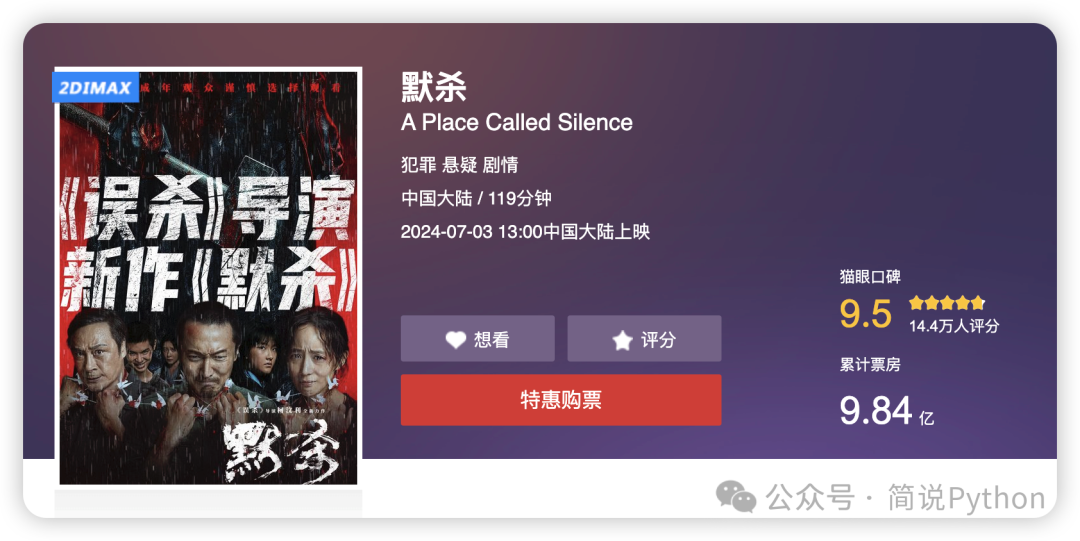
结果,我前天看了眼豆瓣评分6.4,瞬间打了退堂鼓,潜意识下。

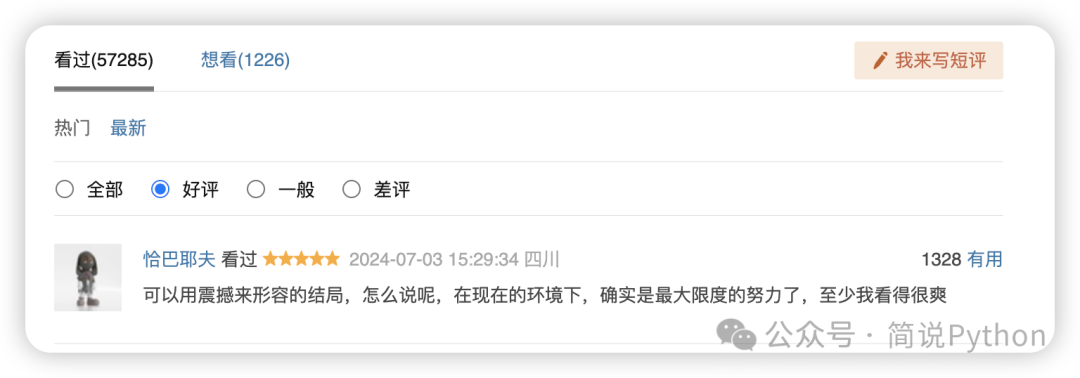
又看了下豆瓣影评,好评最热门是这条 1328 个有用,
差评最热门是这条 5115 个 有用。
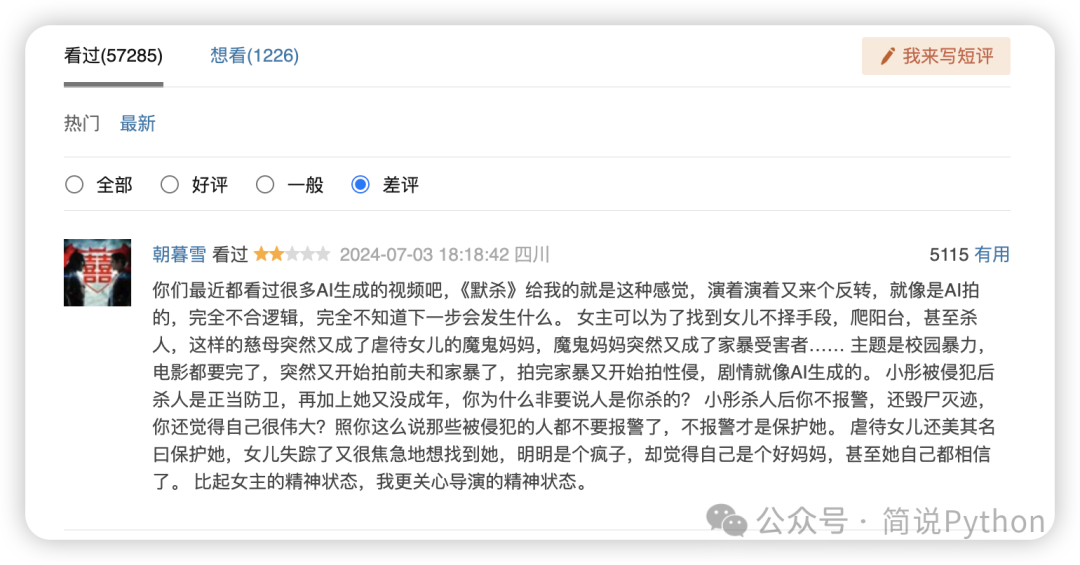
都看到数据了,那就来分析分析吧,《默杀》真的有这么烂吗?
一、技术搞事情(爬一爬)
注意: 本教程仅做编程学习分享使用,分析内容由于数据不完整,会有一定偏差,请勿根据本文分析数据盖棺定论。
注意: 本教程仅做编程学习分享使用,分析内容由于数据不完整,会有一定偏差,请勿根据本文分析数据盖棺定论。
注意: 本教程仅做编程学习分享使用,分析内容由于数据不完整,会有一定偏差,请勿根据本文分析数据盖棺定论。

网页分析方法及具体步骤可以看我之前写的这篇文章,介绍很详细爬取《悲伤逆流成河》猫眼信息 | 郭敬明五年电影最动人之作
豆瓣影评 web 端接口返回的是一个json,其中 html 字段表示页面内容,如果要从这个接口获取数据,可以使用 requests+lxml+xpath 来从 html 中解析出评论数据。
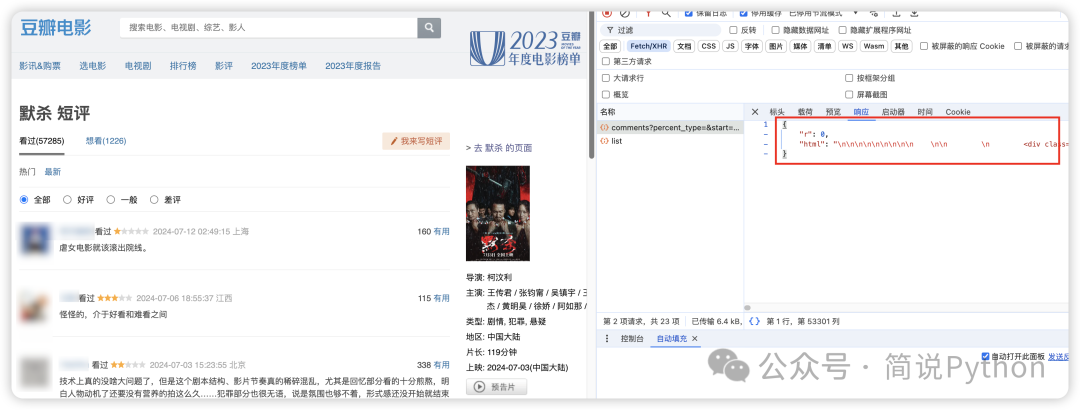
翻页规律也比较好分析,多点击几次下一页,从加载的数据接口链接可以看出页面主要由start 控制,比如第2页,对应 start=20。
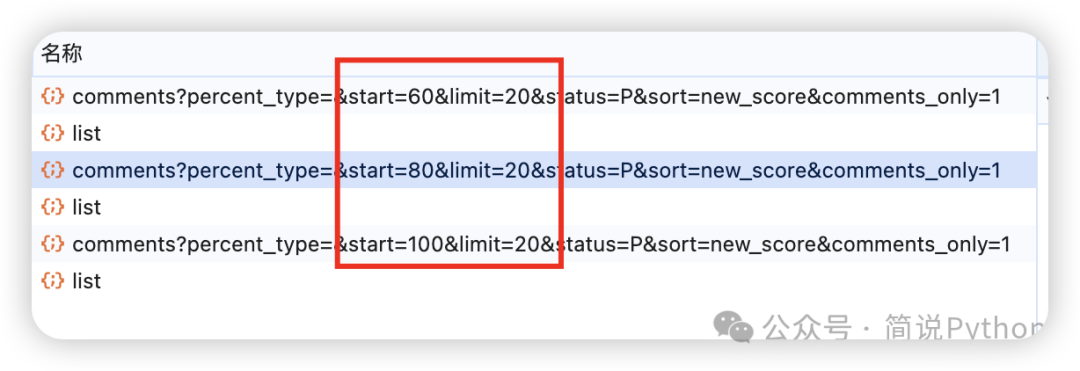
实测网页端限制不登录的情况下最多可以查看 200条记录。
我发现豆瓣 app 端接口数据限制会小很多(感谢给热爱学习的人留点口),最后总共获取了 条数据。
APP 豆瓣影评数据接口:m.douban.com/xxxxxxx/movie/36877322/interests
数据爬取方案:
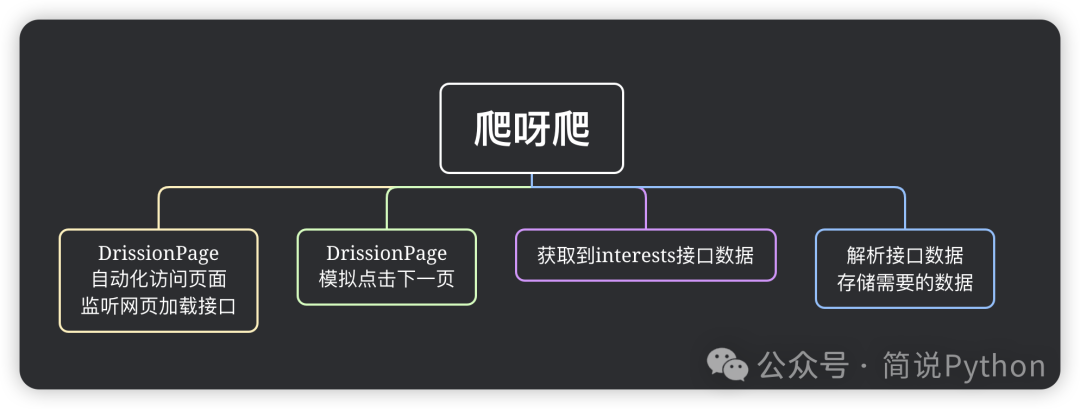
存储字段说明:
字段名 | 数据类型 | 含义描述 |
|---|---|---|
comment | 字符串 | 评论内容 |
rating_value | 数值 | 用户评分,最高5星,最低0星 |
vote_count | 数值 | 评论有用数(点赞数),数值越大说明越多人认可 |
create_time | 日期时间 | 评论创建时间 |
user_loc_name | 字符串 | 用户位置 |
user_reg_time | 日期时间 | 用户注册时间 |
user_gender | 字符串 | 用户性别,F表示女性,M表示男性,U表示用户没填写 |
user_in_blacklist | 布尔值 | 用户是否被拉黑了,True表示被拉黑,False表示未被拉黑 |
ip_location | 字符串 | 用户评论IP地址的地理位置 |
- • comment: 该字段存储用户的评论内容,类型为字符串。
- • rating_value: 该字段存储评论的打分情况,最高5星,最低0星,类型为数值。
- • vote_count: 该字段存储评论的有用数或点赞数,数值越大说明越多人认可,类型为数值。
- • create_time: 该字段存储评论的创建时间,类型为日期时间。
- • user_loc_name: 该字段存储用户的地理位置(城市),类型为字符串。
- • user_reg_time: 该字段存储评论用户的注册时间,类型为日期时间。
- • user_gender: 该字段存储评论用户的性别,F表示女性,M表示男性,U表示用户没填写,类型为字符串。
- • user_in_blacklist: 该字段存储用户是否被拉黑的信息,True表示用户被拉黑,False表示用户未被拉黑,类型为布尔值。
- • ip_location: 该字段存储用户评论IP地址的地理位置,类型为字符串。
代码有点多,这里给大家放最核心的代码,需要完整代码可以文末获取。
for i inrange(0,55762//25):
n = i*25
print(f"第{i}页,第{n}开始")
a = page.ele("@class=button next")
a.scroll.to_see(center=True)
a.click(by_js=True)
lis = page.listen.wait()
data = lis.response.body["interests"]
ifnot data:
print("没数据了")
break
if data:
for entry in lis.response.body.get("interests"):
user_loc_name = entry.get('user').get('loc').get('name')if entry.get('user').get('loc')else""
row ={
'comment': entry.get('comment'),
'rating_value': entry.get('rating').get('value')if entry.get('rating')else"",
'vote_count': entry.get('vote_count'),
'create_time': entry.get('create_time'),
'user_loc_name': user_loc_name,
'user_reg_time': entry.get('user').get('reg_time'),
'user_gender': entry.get('user').get('gender'),
'user_in_blacklist': entry.get('user').get('in_blacklist'),
'ip_location': entry.get('ip_location'),
}
# if compare_dates(entry.get('create_time'), ""
data_for_csv.append(row)
# 温柔一点
time.sleep(random.randint(3,8))
# 存储数据
df = pd.DataFrame(data_for_csv)
file_path ='./mx_comments.xlsx'
df.to_excel(file_path, index=False, encoding='utf-8-sig')获取到 1980 页后就没法继续获取了,差不多 3.9w 条数据。
我从按有用数和评论时间排序爬取合并数据,数据清理前,总数据条数:39049 条 48723条。
二、技术搞事情(数据清理)
读取数据,读取的时候使用drop_duplicates函数去除重复行,规定:comment、user_reg_time都一样就为重复行。
import pandas as pd
file_path = "./mx_comments.xlsx"
data = pd.read_excel(file_path).drop_duplicates(subset=['comment', 'user_reg_time'])
print(data.info())
data.head()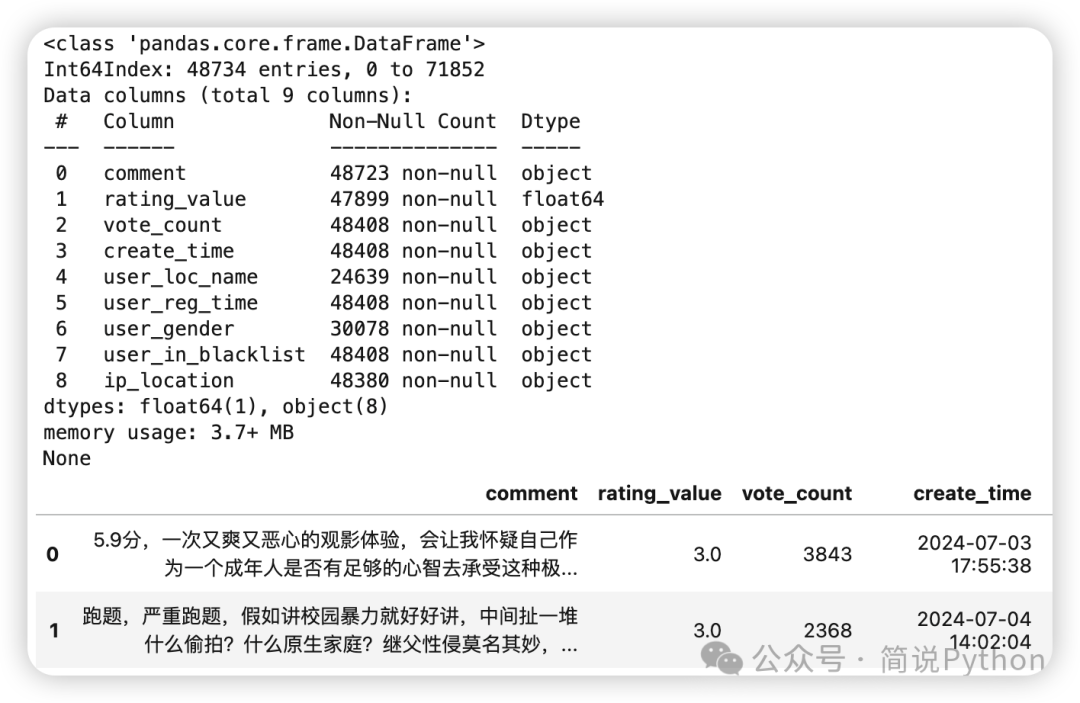
# 1. 删除 comment 为 NaN 的行
data = data.dropna(subset=['comment'])数据清理,在将 create_time 转为日期类型的时候发现异常值,可能前面爬取存储的时候有部分数据有问题。
# 2.0 发现异常值
data[data['create_time'] == '西安']
直接删除异常数据行,思路:找到 create_time 中不为日期的行,然后删除。
# 将 create_time 和 user_reg_time 设置为日期类型
# 首先尝试将 create_time 转换为日期,如果失败则标记为 NaN
data['create_time_converted'] = pd.to_datetime(data['create_time'], errors='coerce')
# 筛选出 create_time 无法转换为日期的行
invalid_create_time_rows = data[data['create_time_converted'].isna()]
# 打印出 create_time 列不是日期的行(可选步骤)
print(invalid_create_time_rows)
# 删除 create_time 列不是日期的行
data = data[data['create_time_converted'].notna()]
# 删除辅助列 create_time_converted
data = data.drop(columns=['create_time_converted'])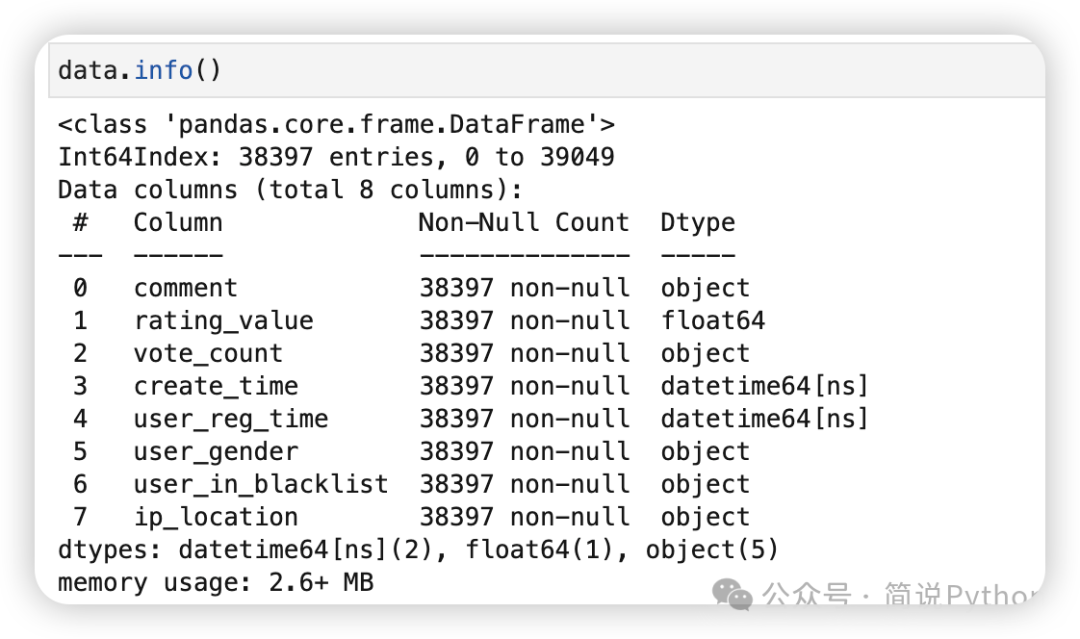
进一步进行数据清理:
# 2.1 将 create_time 和 user_reg_time 设置为日期类型
data['create_time']= pd.to_datetime(data['create_time'])
data['user_reg_time']= pd.to_datetime(data['user_reg_time'])
# 3.1 将 rating_value 中的 NaN 值替换为平均值
rating_mean = data['rating_value'].mean()
data['rating_value']= data['rating_value'].fillna(rating_mean)
# 3.2 将 vote_count 转换为 float 类型
data['vote_count']= data['vote_count'].astype(float)
# 4. 将 ip_location 中的 NaN 值替换为对应 user_loc_name 的值
# 如果 user_loc_name 也是 NaN,则设置为 中国
data['ip_location']= data.apply(
lambda row:'中国'if pd.isna(row['ip_location'])and pd.isna(row['user_loc_name'])
else(row['user_loc_name']if pd.isna(row['ip_location'])else row['ip_location']),
axis=1
)
# 删除 user_loc_name
data = data.drop(columns=['user_loc_name'])
# 5. 将 user_gender 中的 NaN 值替换为 'U
data['user_gender']= data['user_gender'].fillna('U')清理完成后数据总共:48395 条,数据损耗:328 条。
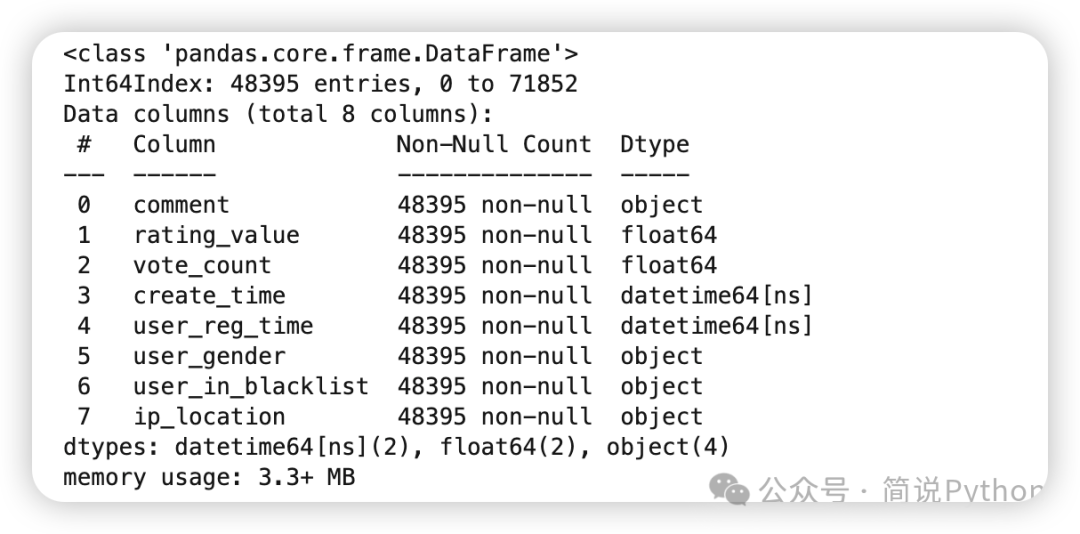
三、技术搞事情(数据可视化分析)
避免数据误操作,对数据进行浅拷贝:
# 浅拷贝
df = data.copy()可视化使用 pyecharts 模块,jupyterlab 里运行渲染需要先设置相关配置:
# 配置 jupyterlab 里渲染可视化
from pyecharts.globals import CurrentConfig, NotebookType
CurrentConfig.NOTEBOOK_TYPE = NotebookType.NTERACT1、评论者性别分布可视化
数据说明:user_gender 中F表示女性,M表示男性,Y表示没有获取到
可视化代码:
# 性别可视化
from pyecharts.charts importPie
from pyecharts import options as opts
# 字母转成汉字
df['user_gender']= df['user_gender'].replace({'F':'女','M':'男','U':'未知'})
# 计算 user_gender 每个类别的数目
gender_counts = df['user_gender'].value_counts()
gender_counts_list =[(gender, count)for gender, count in gender_counts.items()]
# 创建饼图对象
pie =Pie()
# 添加数据
pie.add(
series_name="性别",
data_pair=gender_counts_list,
radius="55%",
)
# 设置全局配置项
pie.set_global_opts(
title_opts=opts.TitleOpts(title="《默杀》影评用户性别分布"),
legend_opts=opts.LegendOpts(orient="vertical", pos_top="15%", pos_left="2%"),
)
# 在 Jupyter Notebook 中渲染图表
pie.render_notebook()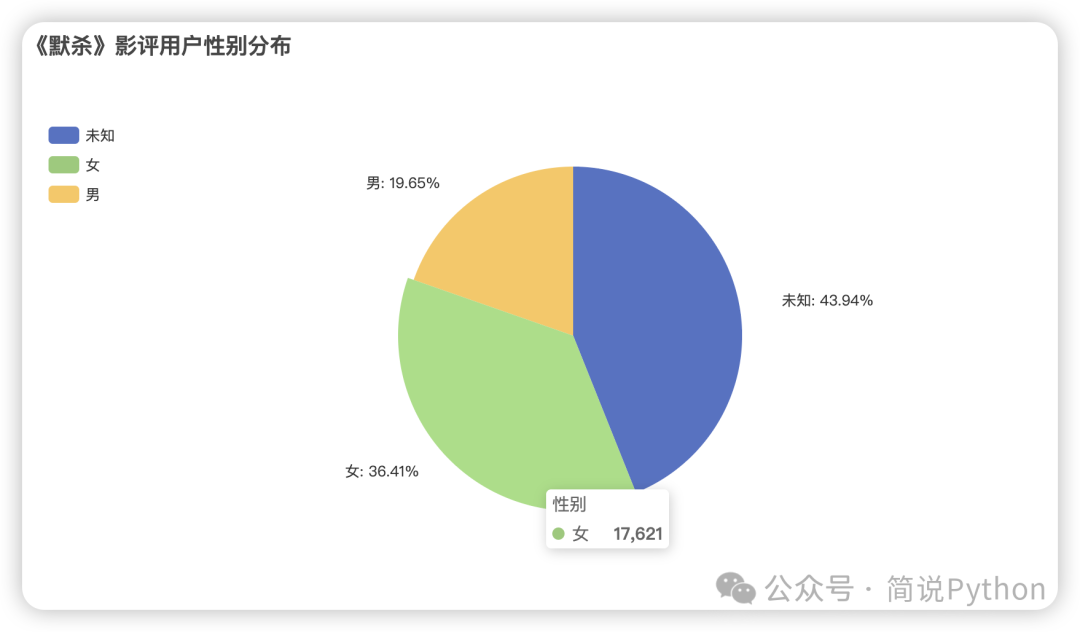
从可视化结果来看,评论中大部分用户都没有设置性别属性,其他有性别属性中的用户,女性 17621 人,男性 9509 人。
2、评论者所在城市分布可视化
数据说明: ip_location 字段。
# 评论者所在城市分布可视化
# 统计每个省份的评论数量
province_counts = df['ip_location'].value_counts()
# 定义中国省份列表,排名不分先后
china_provinces =[
"北京","天津","河北","山西","内蒙古","辽宁","吉林","黑龙江","上海","江苏",
"浙江","安徽","福建","江西","山东","河南","湖北","湖南","广东","广西",
"海南","重庆","四川","贵州","云南","西藏","陕西","甘肃","青海","宁夏",
"新疆","中国香港","中国澳门","中国台湾"
]
# 统计每个省份的评论数量
province_counts = data['ip_location'].value_counts()
# 转换为指定的格式,并过滤非中国省份
province_data =[
(province, count)
for province, count in province_counts.items()
if province in china_provinces
]
province_data[:10]
可视化代码:
- • 热力地图可视化
from pyecharts import options as opts
from pyecharts.charts importGeo
from pyecharts.globalsimportChartType
# 创建 Geo 热力图对象
geo =(
Geo()
.add_schema(maptype="china")
.add(
"评论数量",
province_data,
type_=ChartType.HEATMAP,
)
.set_series_opts(
label_opts=opts.LabelOpts(is_show=False),# 隐藏标签
)
.set_global_opts(
visualmap_opts=opts.VisualMapOpts(),
title_opts=opts.TitleOpts(title="评论者所在省份分布"),
)
)
# 在 Jupyter Notebook 中渲染图表
print()
print()
geo.render_notebook()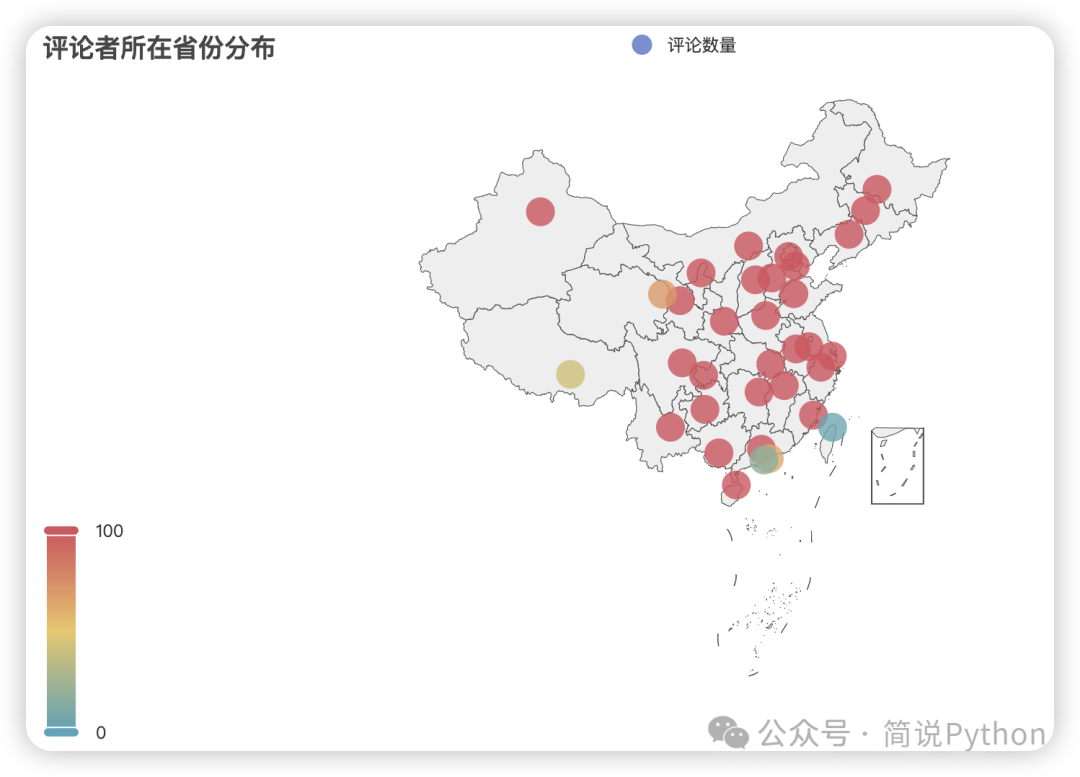
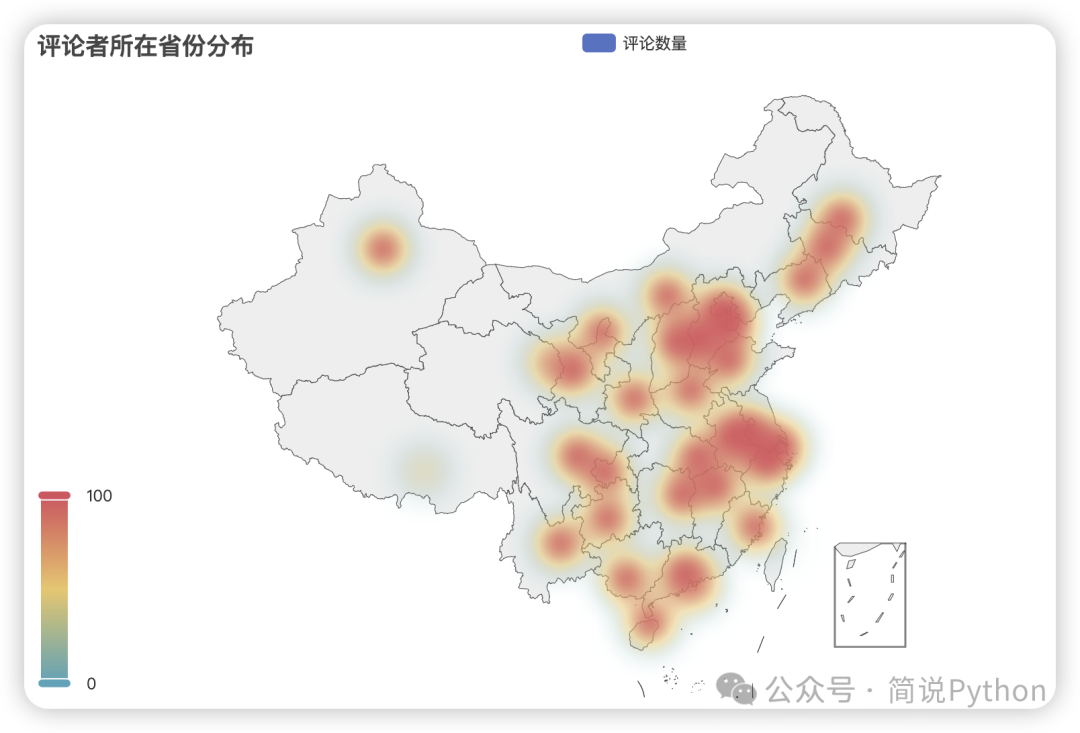
从热力图可以看出,评论用户主要集中在我国东部和中部地区。这些地区包括北京、上海、广东、江苏、浙江等省市,这些地区不仅人口密集,而且经济发展较为发达,人们的消费水平较高,对电影文化娱乐的需求也更强烈。
- • 柱状图排序可视化
from pyecharts import options as opts
from pyecharts.charts importBar
# 预定义一组颜色
colors =[
"#c23531","#2f4554","#61a0a8","#d48265","#91c7ae",
"#749f83","#ca8622","#bda29a","#6e7074","#546570",
"#c4ccd3","#f05b72","#ef5b9c","#f47920","#905a3d",
"#fab27b","#2a5caa","#444693","#726930","#b2d235",
"#6d8346","#ac6767","#1d953f","#6950a1","#918597",
"#f6f5ec","#dda0dd","#4682b4","#8a2be2","#dda0dd",
"#ff69b4","#cd5c5c"
]
# 创建 Bar 柱状图对象
bar =Bar()
bar.add_xaxis([item[0]for item in province_data])
# 添加数据和对应的颜色
y_data =[opts.BarItem(name=item[0], value=item[1], itemstyle_opts=opts.ItemStyleOpts(color=colors[i %len(colors)]))for i, item inenumerate(province_data)]
bar.add_yaxis("评论数量", y_data)
# 设置全局选项
bar.set_global_opts(
title_opts=opts.TitleOpts(title="评论者所在省份分布"),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=45)),
yaxis_opts=opts.AxisOpts(name="评论数量"),
datazoom_opts=opts.DataZoomOpts(),
)
# 在 Jupyter Notebook 中渲染图表
bar.render_notebook()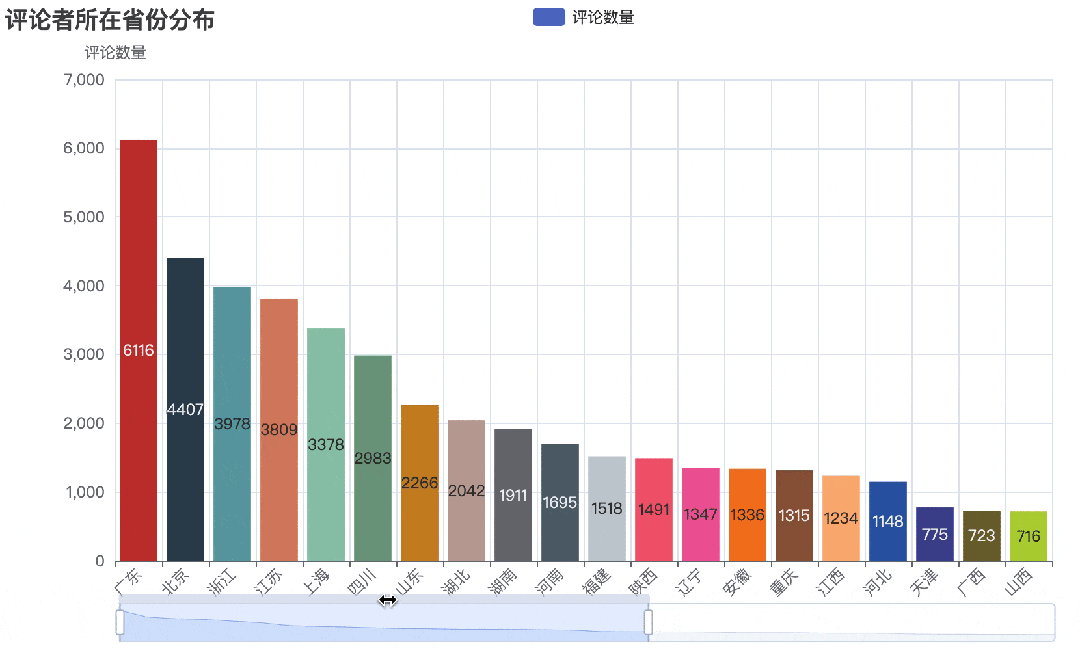
3、每日评论总数可视化
数据说明: create_time 字段。
import pandas as pd
# 计算每天的评论数据条数
daily_comments = df.resample('D', on='create_time').size().reset_index(name='comment_count')
# 查看结果
print(daily_comments.head())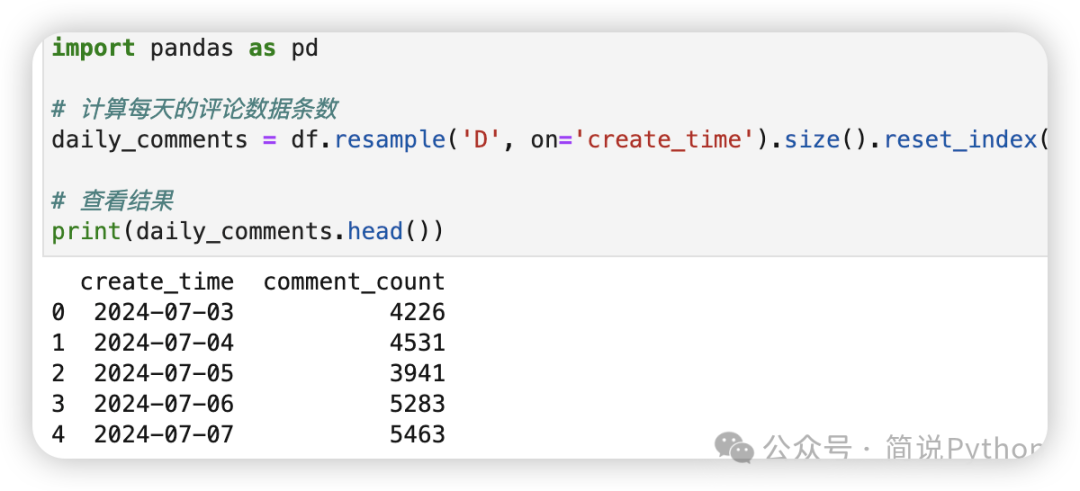
可视化代码:
- • 折线图走势可视化
from pyecharts.charts importLine
from pyecharts import options as opts
# 创建一个Line对象
line =Line()
# 使用to_datetime转换日期格式,并格式化为'年-月-日'
formatted_dates = daily_comments['create_time'].dt.strftime('%Y-%m-%d').tolist()
# 添加数据到折线图
line.add_xaxis(formatted_dates)# x轴数据
line.add_yaxis("评论数", daily_comments['comment_count'].tolist())# y轴数据
# 设置全局配置项
line.set_global_opts(
title_opts=opts.TitleOpts(title="每日评论总数"),# 图表标题
xaxis_opts=opts.AxisOpts(
axislabel_opts=opts.LabelOpts(
rotate=45,# x轴标签旋转45度
interval='auto',# 根据图表显示效果自动调整标签显示
formatter="{value}"# 使用默认的日期格式显示
)
),
yaxis_opts=opts.AxisOpts(name="评论数/条")# y轴名称
)
# 在Jupyter Notebook中显示
line.render_notebook()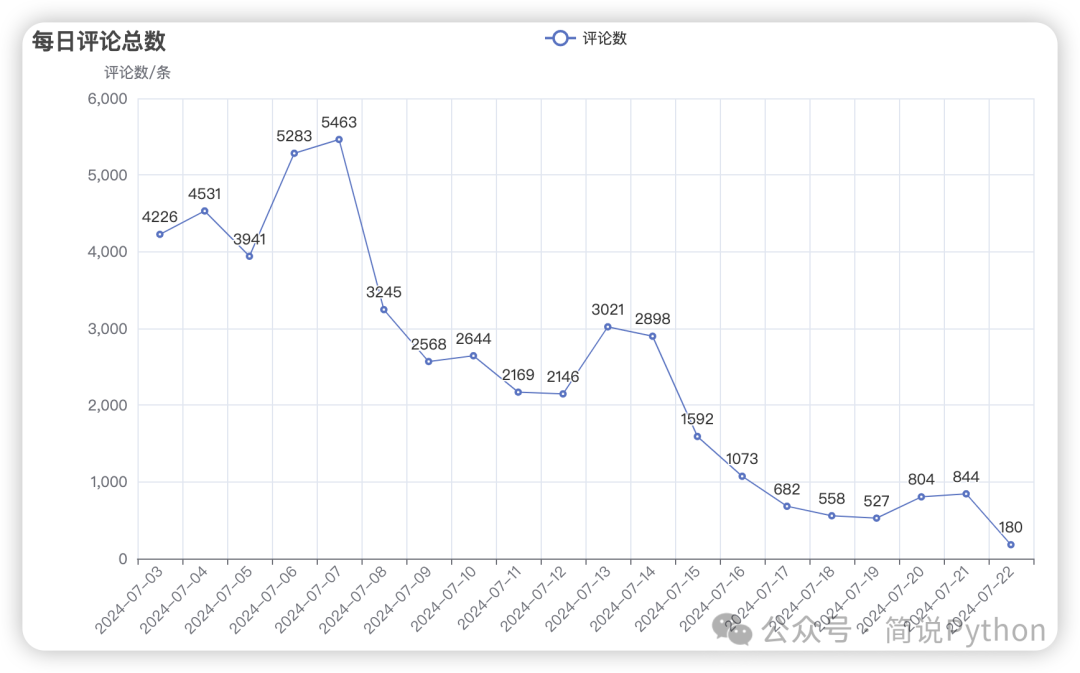
从折线图看《默杀》在上映后的第4、5天热度最高,7月6日 评论新增 5283 条,7月7日评论新增 5463 条,后续评论量就开始急剧下降了。(由于数据总量有限,不一定完整,分析内容仅供参考)
4、评论者注册时间和评论、点赞数关系可视化
数据说明: comment 字段计数用,rating_value 字段计算平均评分,vote_count字段计算评论获得点赞总数。
# 按半年分组
df['reg_period']= df["user_reg_time"].dt.to_period('1Y')
# 计算每个半年段的评分平均值和点赞总量
summary = df.groupby('reg_period').agg(
users=('comment','count'),# 计算条数
avg_rating=('rating_value',lambda x:round(x.mean(),1)),# 计算评分的平均值
total_votes=('vote_count','sum')# 计算点赞的总量
).reset_index()
# 查看结果
summary.head()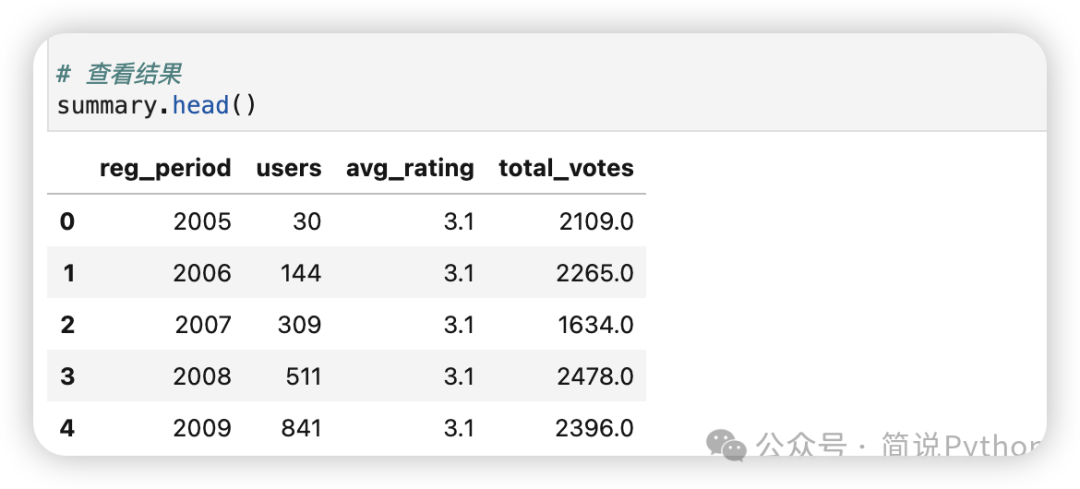
可视化代码:
- • 不同注册时间段用户评分和评论有用总数情况
from pyecharts.charts importLine
from pyecharts import options as opts
# 准备数据
periods = summary['reg_period'].astype(str).tolist()
avg_ratings = summary['avg_rating'].tolist()
total_votes = summary['total_votes'].tolist()
# 创建柱状图
line_chart =(
Line()
.add_xaxis(periods)
.add_yaxis("评分", avg_ratings, yaxis_index=0)
.add_yaxis("评论有用", total_votes, yaxis_index=1)
.extend_axis(
yaxis=opts.AxisOpts(
name="评论有用/个",
type_="value",
position="right"
)
)
.set_global_opts(
title_opts=opts.TitleOpts(title="不同注册时间段用户评分和评论有用数"),
# xaxis_opts=opts.AxisOpts(type="category"),
yaxis_opts=opts.AxisOpts(
name="评分/分",
type_="value",
position="left"
),
tooltip_opts=opts.TooltipOpts(trigger="axis"),
datazoom_opts=opts.DataZoomOpts()
)
)
# 在Jupyter Notebook中显示
line_chart.render_notebook()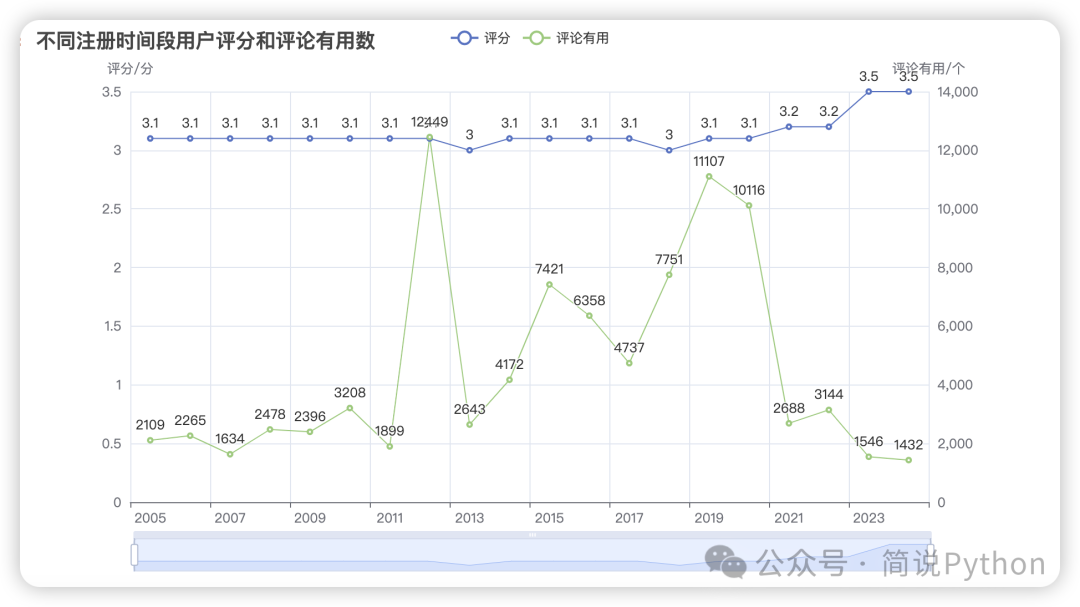
- • 不同注册时间段用户评分和人数情况
from pyecharts.charts importLine
from pyecharts import options as opts
# 准备数据
periods = summary['reg_period'].astype(str).tolist()
avg_ratings = summary['avg_rating'].tolist()
users = summary['users'].tolist()
# 创建柱状图
line_chart =(
Line()
.add_xaxis(periods)
.add_yaxis("评分", avg_ratings, yaxis_index=0)
.add_yaxis("评论人数", users, yaxis_index=1)
.extend_axis(
yaxis=opts.AxisOpts(
name="评论人数/人",
type_="value",
position="right"
)
)
.set_global_opts(
title_opts=opts.TitleOpts(title="不同注册时间段用户评分和评论有用数"),
yaxis_opts=opts.AxisOpts(
name="评分/分",
type_="value",
position="left"
),
tooltip_opts=opts.TooltipOpts(trigger="axis"),
datazoom_opts=opts.DataZoomOpts()
)
)
# 在Jupyter Notebook中显示
line_chart.render_notebook()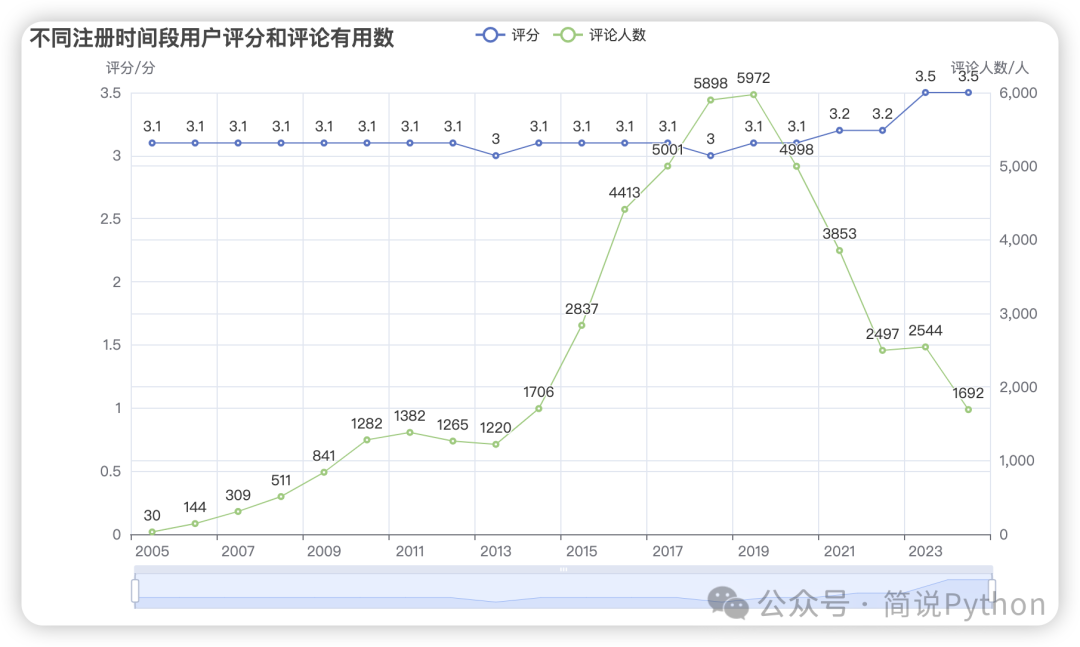
从评分看,每个注册时间段用户的评分平均值都差不多,评分折线图近乎一条直线,说明大家主观感受都差不多,其中 2012、2020年注册用户评论获得有用总数最多,分别为:12449、11107个,评论用户注册时间集中在 2016-2020年。
5、评分分布可视化
数据说明: rating_value 字段按分数段计数。
# 将 rating_value 分段,每2分一个等级
bins =[0,1,2,3,4,5]
labels =['0-1','1-2','2-3','3-4','4-5']
df['rating_level']= pd.cut(df['rating_value'], bins=bins, labels=labels, right=False)
# 计算每个评分等级的用户数及其占比
rating_summary = df['rating_level'].value_counts(normalize=True).reset_index()
rating_summary.columns =['rating_level','percentage']
rating_summary['percentage']=(rating_summary['percentage']*100).round(2)
# 查看结果
print(rating_summary)
可视化代码:
from pyecharts.charts importPie
from pyecharts import options as opts
# 准备数据
rating_levels = rating_summary['rating_level'].tolist()
percentages = rating_summary['percentage'].tolist()
# 创建环状饼图
pie_chart =(
Pie()
.add(
"",
[list(z)for z inzip(rating_levels, percentages)],
radius=["40%","70%"],
label_opts=opts.LabelOpts(
formatter="{b}: {c}%"
),
)
.set_global_opts(
title_opts=opts.TitleOpts(title="用户评分级别占比"),
legend_opts=opts.LegendOpts(orient="vertical", pos_top="15%", pos_left="2%")
)
)
# 在Jupyter Notebook中显示
pie_chart.render_notebook()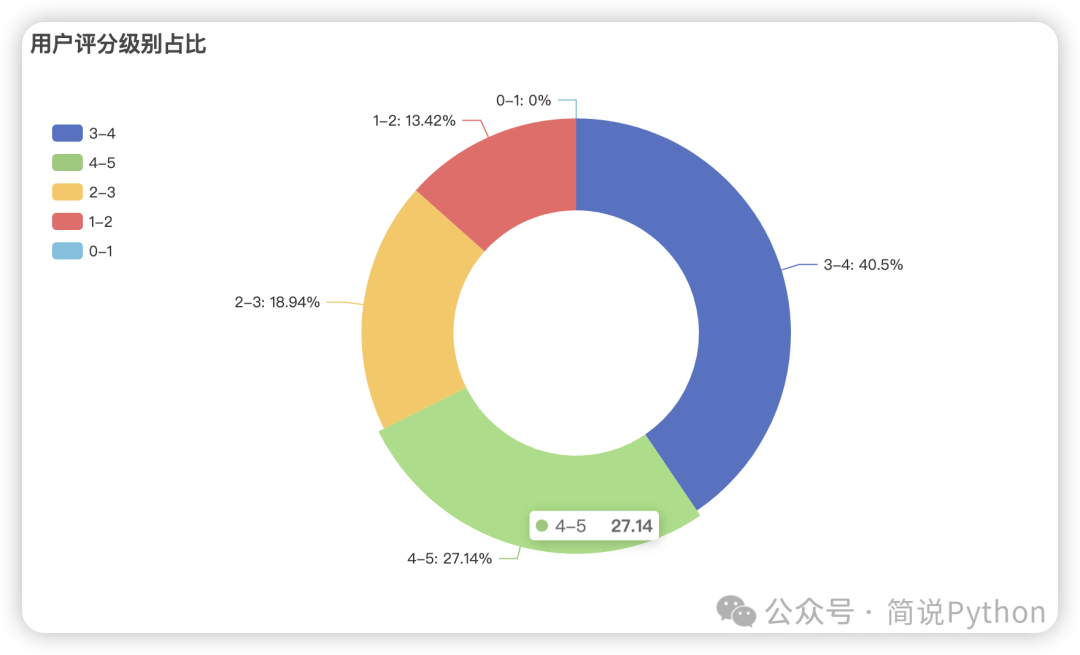
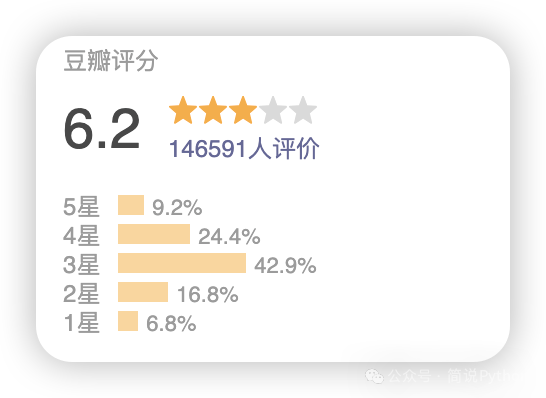
这个评分分段占比,和官网总数据占比,偏差不是很大。大部分用户给出了3星评价
6、评论内容词云可视化
首先对评论进行分词处理,这里使用 pkuseg 对 Excel 中的评论列进行多线程分词处理,并去除停用词,保存结果到 fc.txt 文件。
import pandas as pd
import pkuseg
from concurrent.futures importThreadPoolExecutor, as_completed
import re
from os import path
# 设置文件路径
d = path.dirname(__file__)# 获取当前文件的目录
stopwords_path ='./stopwords.txt'
excel_path ='merged_output.xlsx'# 请将此路径替换为实际的文件路径
output_path ='fc.txt'
# 读取停用词
withopen(stopwords_path, encoding='utf8')as f:
stopwords =set(f.read().split())
# 读取 Excel 文件中的评论数据
df = pd.read_excel(excel_path)
# 确保读取了评论数据
if'comment'notin df.columns:
raiseValueError("Excel 文件中没有 'comment' 列")
comments = df['comment'].astype(str).tolist()
# 初始化 PKUSEG 分词器
seg = pkuseg.pkuseg()
# 去除所有评论里多余的字符
defclean_text(content):
content = content.replace(" ",",")
content = content.replace(" ","、")
content = re.sub('[,,。. \r\n]','', content)
return content
# 定义分词函数,包含去除停用词的处理
defsegment_text(text):
text = clean_text(text)
words = seg.cut(text)
return' '.join(word for word in words if word notin stopwords andlen(word.strip())>1)
# 多线程分词
segmented_comments =[]
withThreadPoolExecutor(max_workers=8)as executor:# 调整 max_workers 来设置线程数量
futures ={executor.submit(segment_text, comment): comment for comment in comments}
for future in as_completed(futures):
segmented_comments.append(future.result())
# 将分词结果写入 fc.txt 文件
withopen(output_path,'w', encoding='utf-8')as f:
for line in segmented_comments:
f.write(line +'\n')
print(f"分词结果已保存至 {output_path}")进行词云可视化:
# 生成词云图
def make_wordcloud(text):
# 词云可视化部分涉及较多的图片处理代码
# 比较繁杂,需要完整源码可以看文末获取方法原图:

词云叠加:

有点丑,不如直接这样的哈哈哈哈~

总结:“校园霸凌剧情,不断反转。”
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-07-24,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号