机器学习入门(四):距离度量方法 归一化和标准化


1. 距离的度量方法
1.1 机器学习中为什么要度量距离?
机器学习算法中,经常需要 判断两个样本之间是否相似 ,比如KNN,K-means,推荐算法中的协同过滤等等,常用的套路是 将相似的判断转换成距离的计算 ,距离近的样本相似程度高,距离远的相似程度低。所以度量距离是很多算法中的关键步骤。
KNN算法中要求数据的所有特征都用数值表示。若在数据特征中存在非数值类型,必须采用手段将其进行量化为数值。
- 比如样本特征中包含有颜色(红、绿、蓝)一项,颜色之间没有距离可言,可通过将颜色转化为 灰度值来实现距离计算 。
- 每个特征都用数值表示,样本之间就可以计算出彼此的距离来
接下来介绍几种距离度量方法
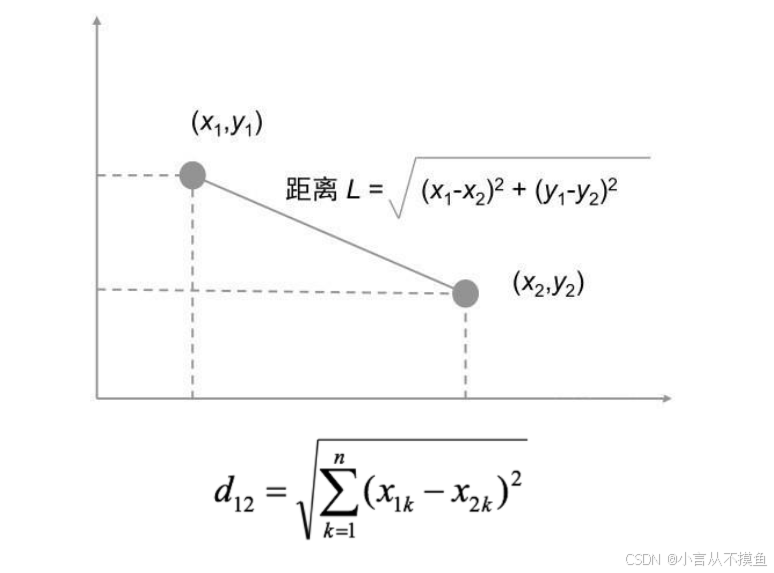
1.2 欧式距离
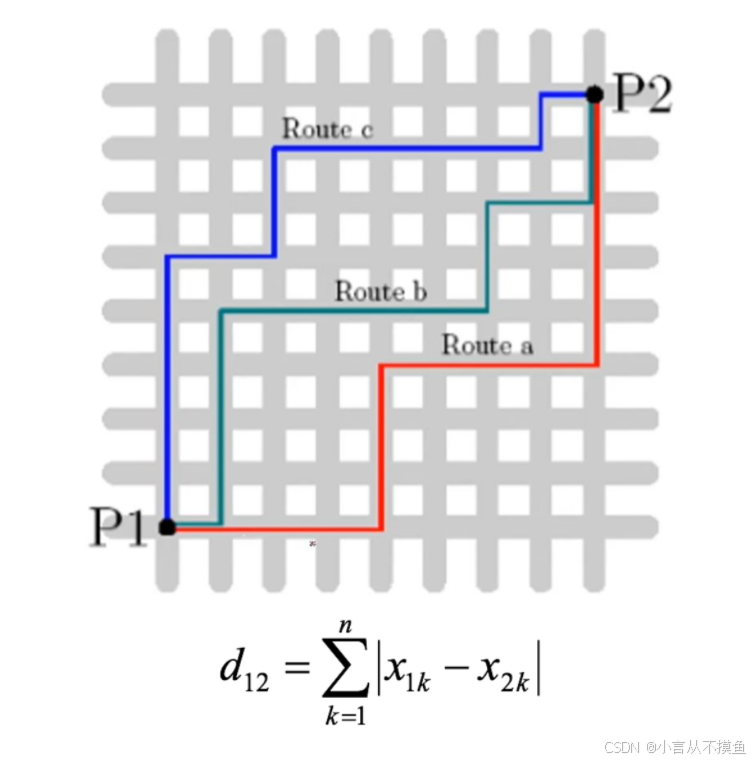
1.3 曼哈顿距离
1.4 切比雪夫距离(了解)
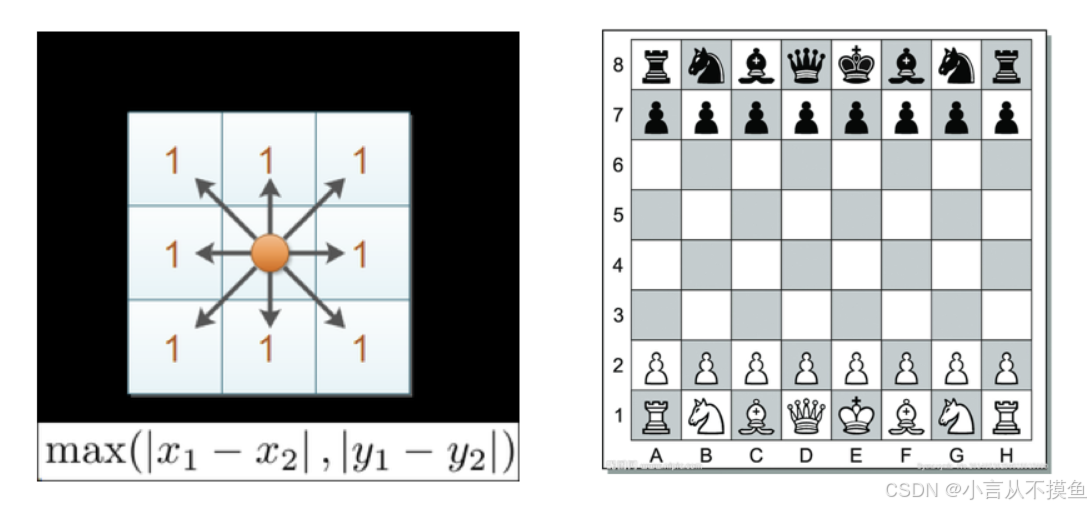
国际象棋棋盘上二个位置间的切比雪夫距离是指王要从一个位置移至另一个位置需要走的步数。(王可以往斜前或斜后方向移动一格)

1.5 闵式距离
闵氏距离不是一种距离,而是一组距离的定义,是对多个距离度量公式的概括性的表述。
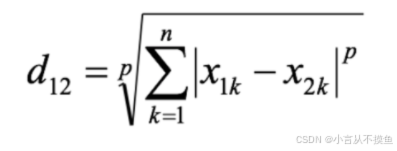
其中p是一个变参数:
- 当 p=1 时,就是曼哈顿距离;
- 当 p=2 时,就是欧氏距离;
- 当 p→∞ 时,就是切比雪夫距离。
根据 p 的不同,闵氏距离可以表示某一类/种的距离。
1.6 小结
- 欧式距离、曼哈顿距离、切比雪夫距离是最常用的距离
- 闵式距离是一组距离的度量,当 p = 1 时代表曼哈顿距离,当 p = 2 时代表欧式距离,当 p = ∞ 时代表切比雪夫距离
2. 归一化和标准化
2.1 为什么做归一化和标准化
样本中有多个特征,每一个特征都有自己的定义域和取值范围,他们对距离计算也是不同的,如取值较大的影响力会盖过取值较小的参数。因此,为了公平,样本参数必须做一些归一化处理,将不同的特征都缩放到相同的区间或者分布内。
2.2 归一化
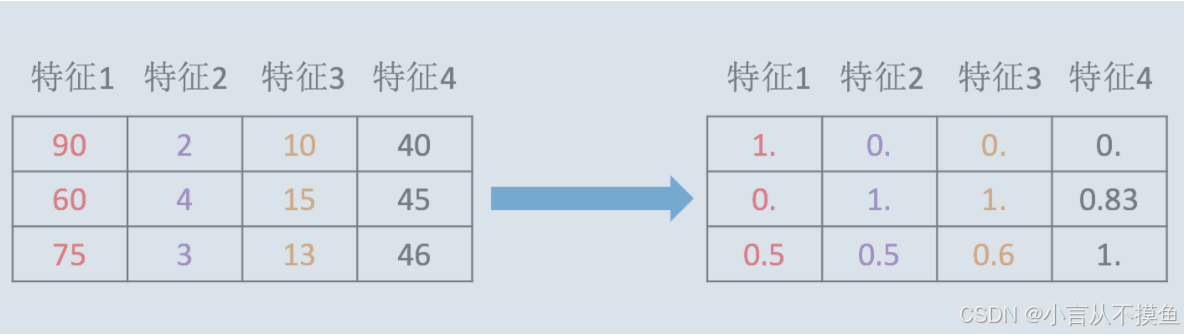
通过对原始数据进行变换,把数据映射到(默认为[0,1])之间。
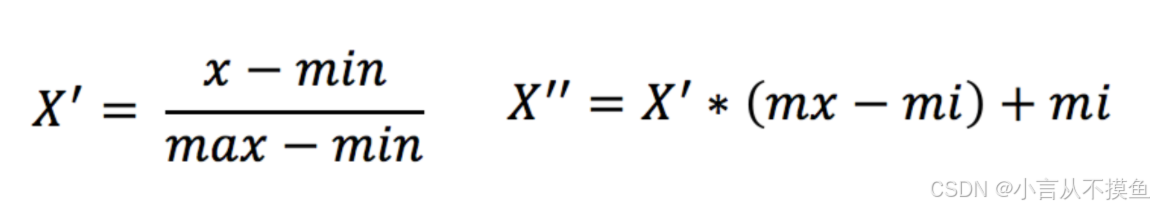
scikit-learn 中实现归一化的 API:
from sklearn.preprocessing import MinMaxScaler
def test():
# 1. 准备数据
data = [[90, 2, 10, 40],
[60, 4, 15, 45],
[75, 3, 13, 46]]
# 2. 初始化归一化对象
transformer = MinMaxScaler()
# 3. 对原始特征进行变换
data = transformer.fit_transform(data)
# 4. 打印归一化后的结果
print(data)归一化受到最大值与最小值的影响,这种方法容易受到异常数据的影响, 鲁棒性较差,适合传统精确小数据场景
2.3 标准化
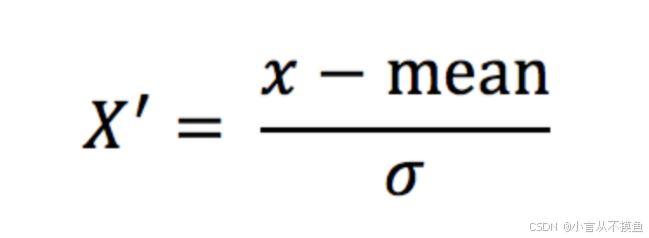
- mean 为特征的平均值
- σ 为特征的标准差
scikit-learn 中实现标准化的 API:
from sklearn.preprocessing import StandardScaler
def test():
# 1. 准备数据
data = [[90, 2, 10, 40],
[60, 4, 15, 45],
[75, 3, 13, 46]]
# 2. 初始化标准化对象
transformer = StandardScaler()
# 3. 对原始特征进行变换
data = transformer.fit_transform(data)
# 4. 打印归一化后的结果
print(data)对于标准化来说,如果出现异常点,由于具有一定数据量,少量的异常点对于平均值的影响并不大
2.4 小结
- 归一化和标准化都能够将量纲不同的数据集缩放到相同范围内
- 归一化受到最大值与最小值的影响,这种方法容易受到异常数据的影响, 鲁棒性较差,适合传统精确小数据场景
- 对于标准化来说,如果出现异常点,由于具有一定数据量,少量的异常点对于平均值的影响并不大,鲁棒性更好
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-08-13,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号