【机器学习】过拟合与欠拟合——如何优化模型性能


【机器学习】过拟合与欠拟合——如何优化模型性能
1. 引言
在机器学习中,模型的表现不仅依赖于算法的选择,还依赖于模型对数据的拟合情况。过拟合(Overfitting)和欠拟合(Underfitting)是模型训练过程中常见的问题。过拟合意味着模型过于复杂,以至于“记住”了训练数据中的噪声,而欠拟合则意味着模型过于简单,无法捕捉到数据的主要特征。本文将深入探讨过拟合与欠拟合的定义、表现、原因及常见的解决方案,帮助你优化模型性能。

2. 什么是过拟合?
2.1 定义
过拟合是指模型在训练集上表现得非常好,但在测试集或新数据上表现较差。这是因为模型在训练数据上过于复杂,捕捉了数据中的噪声和异常值,而这些并不代表数据的实际分布。
2.2 过拟合的表现:
- 训练集上的误差极低:模型在训练集上表现完美。
- 测试集上的误差较高:模型无法泛化到未见的数据。
- 高方差:模型对训练数据敏感,对测试数据不够鲁棒。
2.3 过拟合的原因:
- 模型过于复杂:参数过多,导致模型能够记住每一个训练数据点。
- 训练数据量过少:数据不足以代表真实情况。
- 特征过多且无正则化:大量不相关的特征增加了模型复杂度。
示例:决策树模型过拟合
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 加载数据
iris = load_iris()
X = iris.data
y = iris.target
# 拆分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 训练复杂的决策树模型
model = DecisionTreeClassifier(max_depth=None) # 不限制深度,可能导致过拟合
model.fit(X_train, y_train)
# 评估模型
train_accuracy = accuracy_score(y_train, model.predict(X_train))
test_accuracy = accuracy_score(y_test, model.predict(X_test))
print(f"训练集准确率: {train_accuracy}")
print(f"测试集准确率: {test_accuracy}")3. 什么是欠拟合?
3.1 定义
欠拟合是指模型过于简单,无法捕捉到训练数据中的模式。这种情况下,模型的训练误差和测试误差都较高,说明模型既没有学好训练数据,也无法在测试集上表现良好。
3.2 欠拟合的表现:
- 训练集和测试集误差都较高:模型对训练数据和测试数据都不能很好地拟合。
- 高偏差:模型对数据的基本结构理解不到位,表现为过于简化。
3.3 欠拟合的原因:
- 模型过于简单:模型结构无法捕捉数据中的复杂关系。
- 训练时间不足:模型还没有充分学习到数据中的模式。
- 特征不足:输入特征太少,导致模型无法充分学习。
示例:线性回归模型欠拟合
from sklearn.datasets import load_boston
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# 加载数据
X, y = load_boston(return_X_y=True)
# 拆分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 训练简单的线性回归模型
model = LinearRegression()
model.fit(X_train, y_train)
# 评估模型
train_error = mean_squared_error(y_train, model.predict(X_train))
test_error = mean_squared_error(y_test, model.predict(X_test))
print(f"训练集均方误差: {train_error}")
print(f"测试集均方误差: {test_error}")
4. 如何避免过拟合?
4.1 减少模型复杂度
通过限制模型的复杂度,可以减少模型过拟合的风险。例如,决策树的深度越大,模型越容易过拟合。
示例:限制决策树深度
model = DecisionTreeClassifier(max_depth=3) # 限制树的最大深度
model.fit(X_train, y_train)4.2 使用正则化
正则化是在损失函数中添加惩罚项,限制模型的复杂度,从而避免过拟合。常见的正则化方法有 L1 正则化(Lasso)和 L2 正则化(Ridge)。
示例:使用 Ridge 回归进行正则化
from sklearn.linear_model import Ridge
# 使用 Ridge 回归
model = Ridge(alpha=1.0)
model.fit(X_train, y_train)4.3 数据扩充
如果训练数据不足,可以通过数据扩充来增加数据量,从而减少过拟合的风险。对于图像数据,数据扩充的方法包括翻转、旋转、缩放等。
4.4 使用交叉验证
交叉验证通过将数据集划分为多个子集来验证模型的性能,避免模型在特定数据上过拟合。
示例:K 折交叉验证
from sklearn.model_selection import cross_val_score
# 使用 5 折交叉验证
scores = cross_val_score(model, X, y, cv=5)
print(f"交叉验证得分: {scores}")
5. 如何避免欠拟合?
5.1 增加模型复杂度
通过增加模型的复杂度,可以帮助模型更好地拟合数据。例如,在神经网络中增加隐藏层或神经元的数量。
示例:增加决策树的深度
model = DecisionTreeClassifier(max_depth=10) # 增加树的深度
model.fit(X_train, y_train)5.2 训练更长时间
在深度学习中,欠拟合通常意味着模型还没有充分学习。可以通过增加训练的轮数来改善欠拟合。
5.3 增加特征
通过引入更多有意义的特征,可以帮助模型更好地学习数据中的模式。例如,特征工程中的特征生成步骤可以生成多项式或交互特征。
示例:生成多项式特征
from sklearn.preprocessing import PolynomialFeatures
# 生成二次多项式特征
poly = PolynomialFeatures(degree=2)
X_poly = poly.fit_transform(X_train)
model.fit(X_poly, y_train)5.4 使用非线性模型
如果数据存在复杂的非线性关系,线性模型容易欠拟合。可以选择非线性模型(如随机森林、支持向量机)来提升模型表现。
6. 过拟合与欠拟合的权衡
6.1 偏差-方差权衡
优化模型性能的过程中,我们通常要在**偏差(bias)和方差(variance)**之间找到平衡。偏差过高意味着欠拟合,方差过高则意味着过拟合。通过选择合适的模型复杂度,可以在偏差和方差之间取得良好的权衡。
6.2 学习曲线
通过绘制学习曲线,可以帮助我们观察模型是否出现了过拟合或欠拟合。训练误差和验证误差趋于一致且较低时,说明模型表现良好。

7. 案例:避免房价预测中的过拟合与欠拟合
数据清洗与预处理
# 假设数据已经加载到 data 中
X = data.drop('price', axis=1)
y = data['price']
# 拆分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)训练 Ridge 回归模型避免过拟合
from sklearn.linear_model import Ridge
# 使用正则化的 Ridge 回归
model = Ridge(alpha=1.0)
model.fit(X_train, y_train)
# 评估模型
train_error = mean_squared_error(y_train, model.predict(X_train))
test_error = mean_squared_error(y_test, model.predict(X_test))
print(f"训练集均方误差: {train_error}")
print(f"测试集均方误差: {test_error}")8. 总结
过拟合和欠拟合是机器学习模型中的常见问题。过拟合通常由模型过于复杂或数据不足引起,而欠拟合则是由于模型过于简单或数据特征不足。通过使用正则化、交叉验证、增加数据量和调整模型复杂度等方法,可以有效地优化模型性能。在实际应用中,找到适当的模型复杂度并在偏差和方差之间平衡,是提升机器学习模型性能的关键。
9. 参考资料
使用机器学习分析csdn热榜
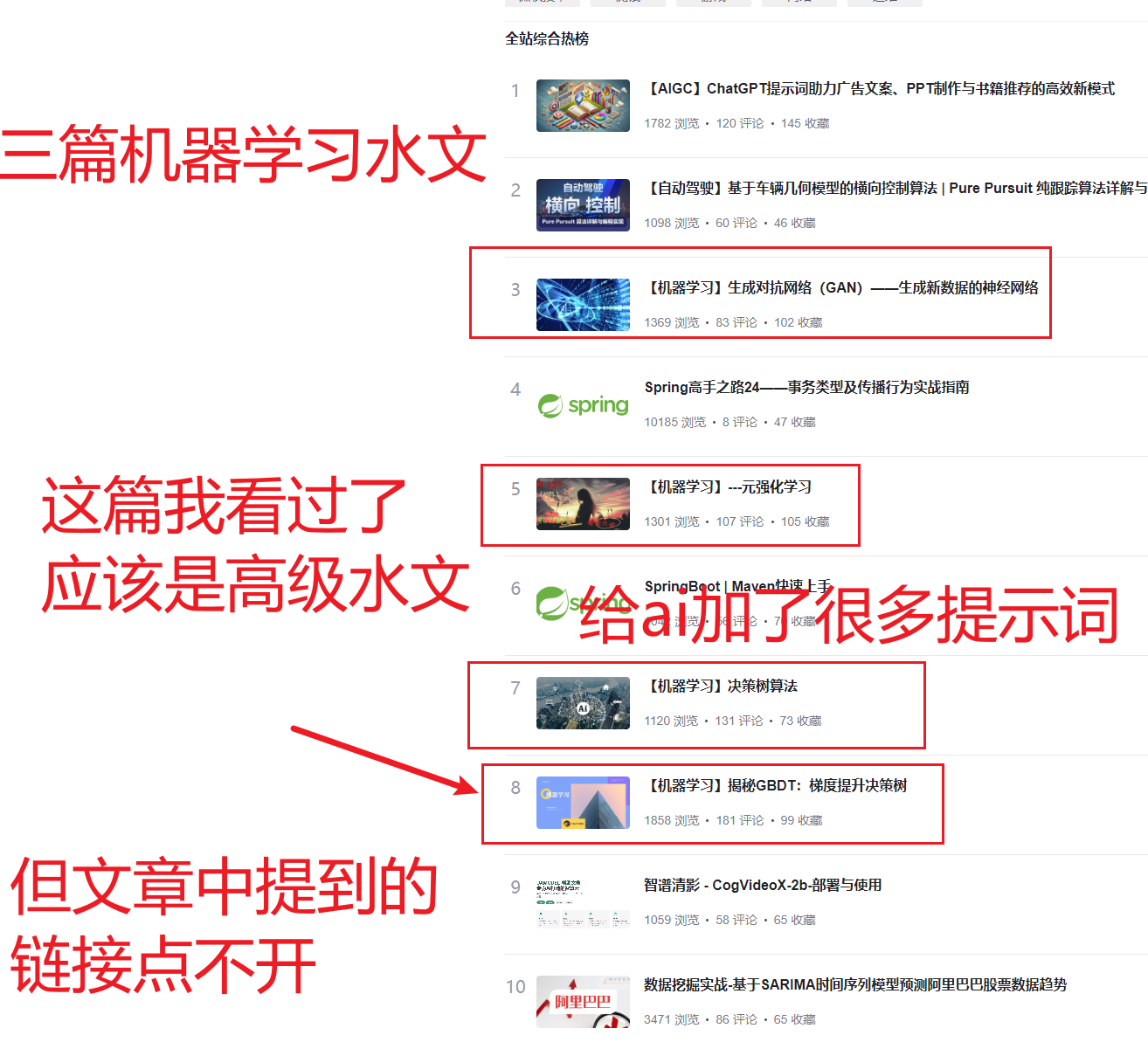
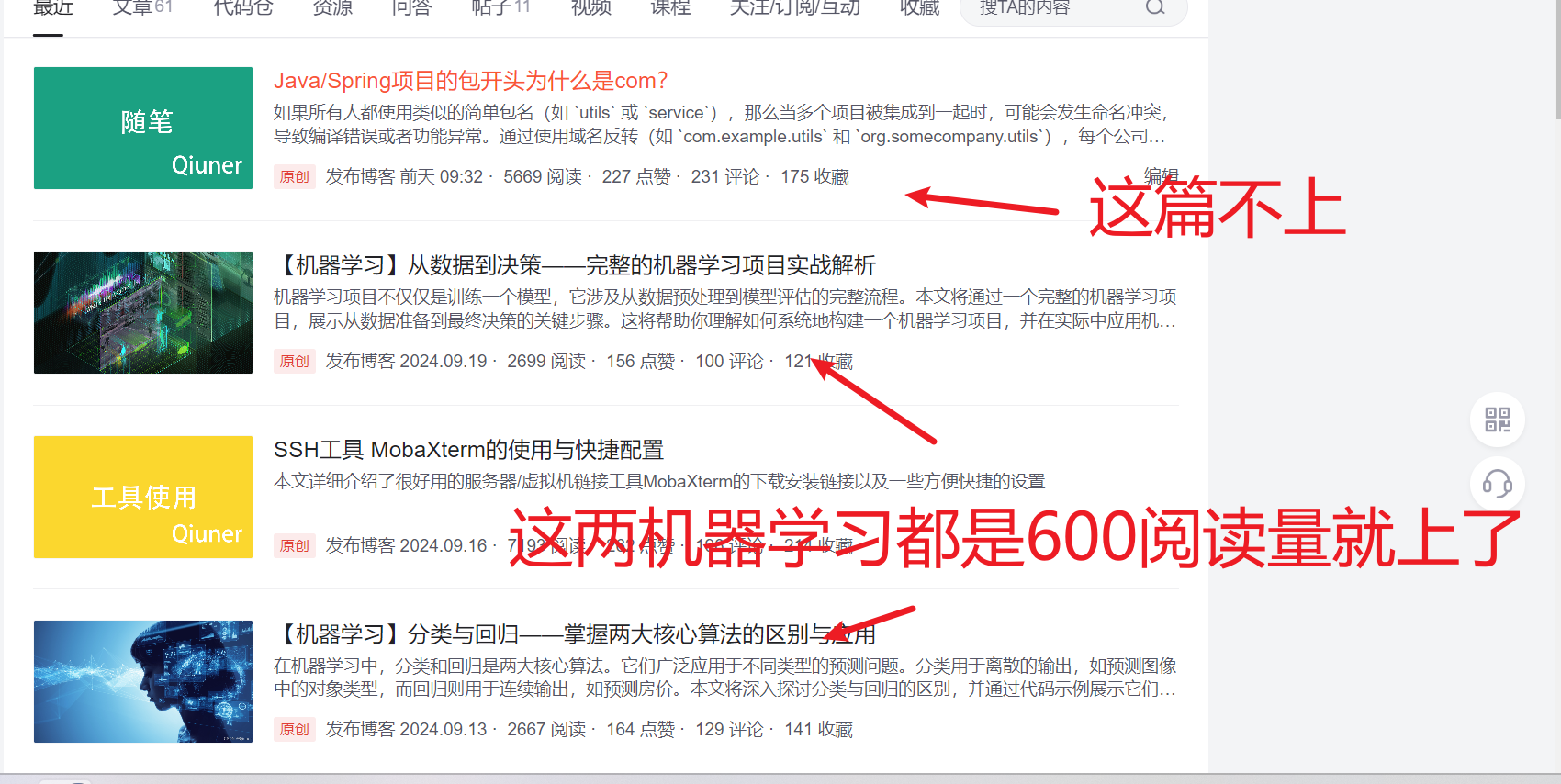
- 也不知道为什么这个热榜对机器学习这么看重,只要你的文章标题是机器学习那就很容易上热榜,但如果不是,那即使你文章流量啊、点赞、评论数上热榜的要求就像翻了倍一样…
- 机器学习和csdn热榜的爹一样
- 就像官方在鼓励你写机器学习水文一样
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-09-25,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号