YOLO11 全新发布!(原理介绍+代码详见+结构框图)
原创
YOLO11 全新发布!(原理介绍+代码详见+结构框图)
原创
AI小怪兽
发布于 2024-10-08 16:00:51
发布于 2024-10-08 16:00:51
1.YOLO11介绍
Ultralytics YOLO11是一款尖端的、最先进的模型,它在之前YOLO版本成功的基础上进行了构建,并引入了新功能和改进,以进一步提升性能和灵活性。YOLO11设计快速、准确且易于使用,使其成为各种物体检测和跟踪、实例分割、图像分类以及姿态估计任务的绝佳选择。
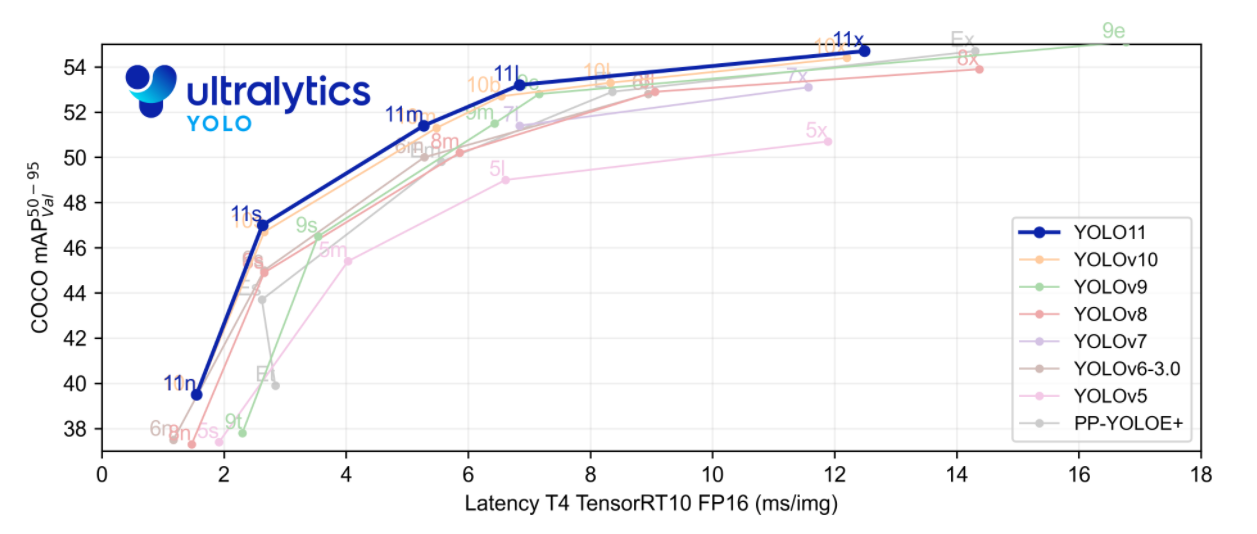

目标检测性能
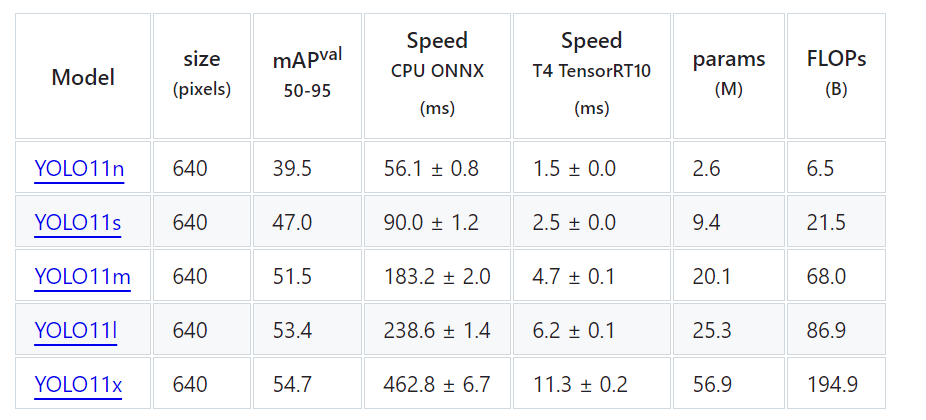
语义分割性能
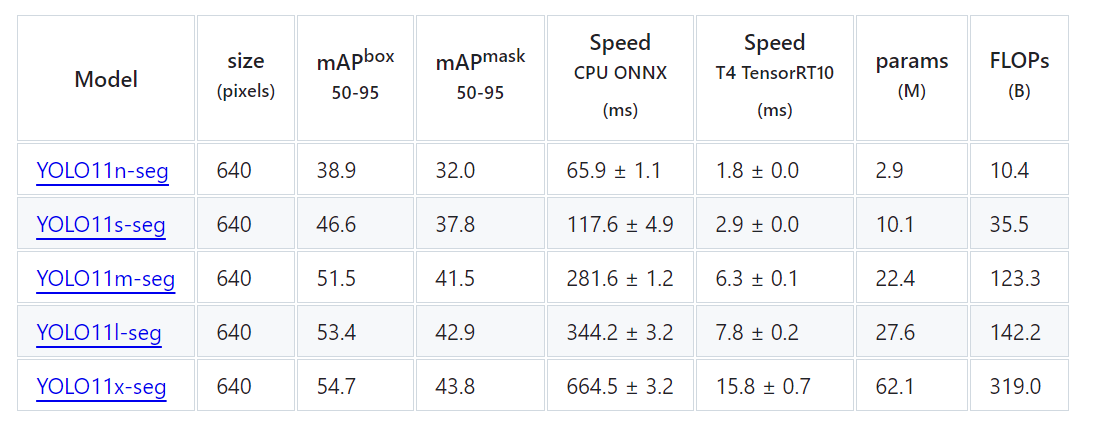
Pose关键点检测性能
结构图如下:
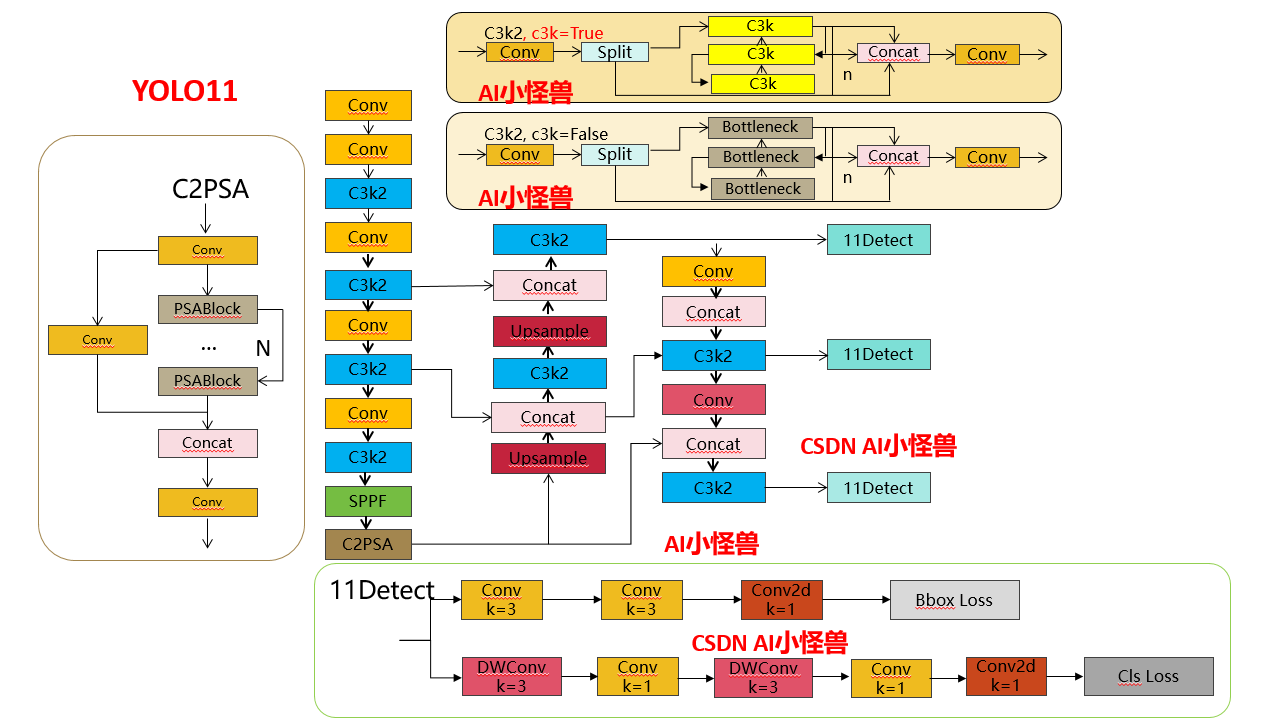
1.1 C3k2
C3k2,结构图如下

C3k2,继承自类C2f,其中通过c3k设置False或者Ture来决定选择使用C3k还是Bottleneck

实现代码ultralytics/nn/modules/block.py
class C3k2(C2f):
"""Faster Implementation of CSP Bottleneck with 2 convolutions."""
def __init__(self, c1, c2, n=1, c3k=False, e=0.5, g=1, shortcut=True):
"""Initializes the C3k2 module, a faster CSP Bottleneck with 2 convolutions and optional C3k blocks."""
super().__init__(c1, c2, n, shortcut, g, e)
self.m = nn.ModuleList(
C3k(self.c, self.c, 2, shortcut, g) if c3k else Bottleneck(self.c, self.c, shortcut, g) for _ in range(n)
)
class C3k(C3):
"""C3k is a CSP bottleneck module with customizable kernel sizes for feature extraction in neural networks."""
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5, k=3):
"""Initializes the C3k module with specified channels, number of layers, and configurations."""
super().__init__(c1, c2, n, shortcut, g, e)
c_ = int(c2 * e) # hidden channels
# self.m = nn.Sequential(*(RepBottleneck(c_, c_, shortcut, g, k=(k, k), e=1.0) for _ in range(n)))
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, k=(k, k), e=1.0) for _ in range(n)))
1.2 C2PSA介绍
借鉴V10 PSA结构,实现了C2PSA和C2fPSA,最终选择了基于C2的C2PSA(可能涨点更好?)
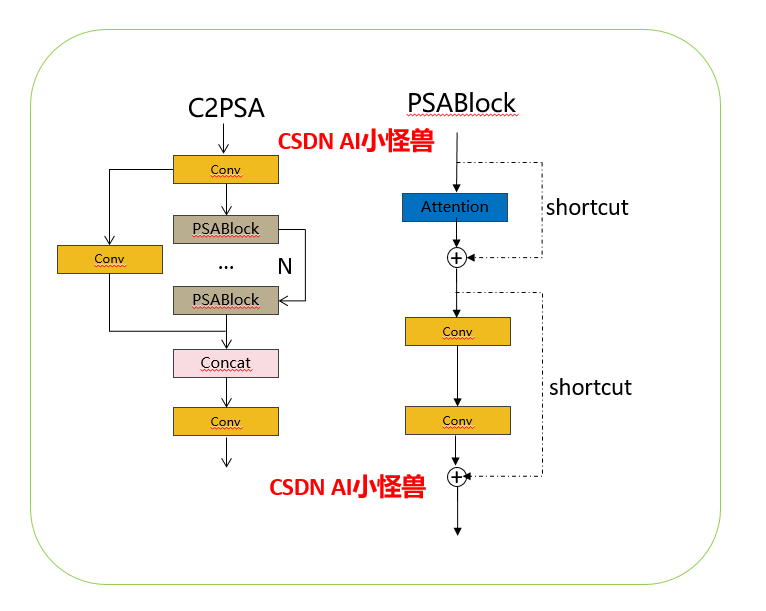
实现代码ultralytics/nn/modules/block.py
class PSABlock(nn.Module):
"""
PSABlock class implementing a Position-Sensitive Attention block for neural networks.
This class encapsulates the functionality for applying multi-head attention and feed-forward neural network layers
with optional shortcut connections.
Attributes:
attn (Attention): Multi-head attention module.
ffn (nn.Sequential): Feed-forward neural network module.
add (bool): Flag indicating whether to add shortcut connections.
Methods:
forward: Performs a forward pass through the PSABlock, applying attention and feed-forward layers.
Examples:
Create a PSABlock and perform a forward pass
>>> psablock = PSABlock(c=128, attn_ratio=0.5, num_heads=4, shortcut=True)
>>> input_tensor = torch.randn(1, 128, 32, 32)
>>> output_tensor = psablock(input_tensor)
"""
def __init__(self, c, attn_ratio=0.5, num_heads=4, shortcut=True) -> None:
"""Initializes the PSABlock with attention and feed-forward layers for enhanced feature extraction."""
super().__init__()
self.attn = Attention(c, attn_ratio=attn_ratio, num_heads=num_heads)
self.ffn = nn.Sequential(Conv(c, c * 2, 1), Conv(c * 2, c, 1, act=False))
self.add = shortcut
def forward(self, x):
"""Executes a forward pass through PSABlock, applying attention and feed-forward layers to the input tensor."""
x = x + self.attn(x) if self.add else self.attn(x)
x = x + self.ffn(x) if self.add else self.ffn(x)
return x
class C2PSA(nn.Module):
"""
C2PSA module with attention mechanism for enhanced feature extraction and processing.
This module implements a convolutional block with attention mechanisms to enhance feature extraction and processing
capabilities. It includes a series of PSABlock modules for self-attention and feed-forward operations.
Attributes:
c (int): Number of hidden channels.
cv1 (Conv): 1x1 convolution layer to reduce the number of input channels to 2*c.
cv2 (Conv): 1x1 convolution layer to reduce the number of output channels to c.
m (nn.Sequential): Sequential container of PSABlock modules for attention and feed-forward operations.
Methods:
forward: Performs a forward pass through the C2PSA module, applying attention and feed-forward operations.
Notes:
This module essentially is the same as PSA module, but refactored to allow stacking more PSABlock modules.
Examples:
>>> c2psa = C2PSA(c1=256, c2=256, n=3, e=0.5)
>>> input_tensor = torch.randn(1, 256, 64, 64)
>>> output_tensor = c2psa(input_tensor)
"""
def __init__(self, c1, c2, n=1, e=0.5):
"""Initializes the C2PSA module with specified input/output channels, number of layers, and expansion ratio."""
super().__init__()
assert c1 == c2
self.c = int(c1 * e)
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv(2 * self.c, c1, 1)
self.m = nn.Sequential(*(PSABlock(self.c, attn_ratio=0.5, num_heads=self.c // 64) for _ in range(n)))
def forward(self, x):
"""Processes the input tensor 'x' through a series of PSA blocks and returns the transformed tensor."""
a, b = self.cv1(x).split((self.c, self.c), dim=1)
b = self.m(b)
return self.cv2(torch.cat((a, b), 1))
class C2fPSA(C2f):
"""
C2fPSA module with enhanced feature extraction using PSA blocks.
This class extends the C2f module by incorporating PSA blocks for improved attention mechanisms and feature extraction.
Attributes:
c (int): Number of hidden channels.
cv1 (Conv): 1x1 convolution layer to reduce the number of input channels to 2*c.
cv2 (Conv): 1x1 convolution layer to reduce the number of output channels to c.
m (nn.ModuleList): List of PSA blocks for feature extraction.
Methods:
forward: Performs a forward pass through the C2fPSA module.
forward_split: Performs a forward pass using split() instead of chunk().
Examples:
>>> import torch
>>> from ultralytics.models.common import C2fPSA
>>> model = C2fPSA(c1=64, c2=64, n=3, e=0.5)
>>> x = torch.randn(1, 64, 128, 128)
>>> output = model(x)
>>> print(output.shape)
"""
def __init__(self, c1, c2, n=1, e=0.5):
"""Initializes the C2fPSA module, a variant of C2f with PSA blocks for enhanced feature extraction."""
assert c1 == c2
super().__init__(c1, c2, n=n, e=e)
self.m = nn.ModuleList(PSABlock(self.c, attn_ratio=0.5, num_heads=self.c // 64) for _ in range(n))
1.3 11 Detect介绍
分类检测头引入了DWConv(更加轻量级,为后续二次创新提供了改进点),结构图如下(和V8的区别):
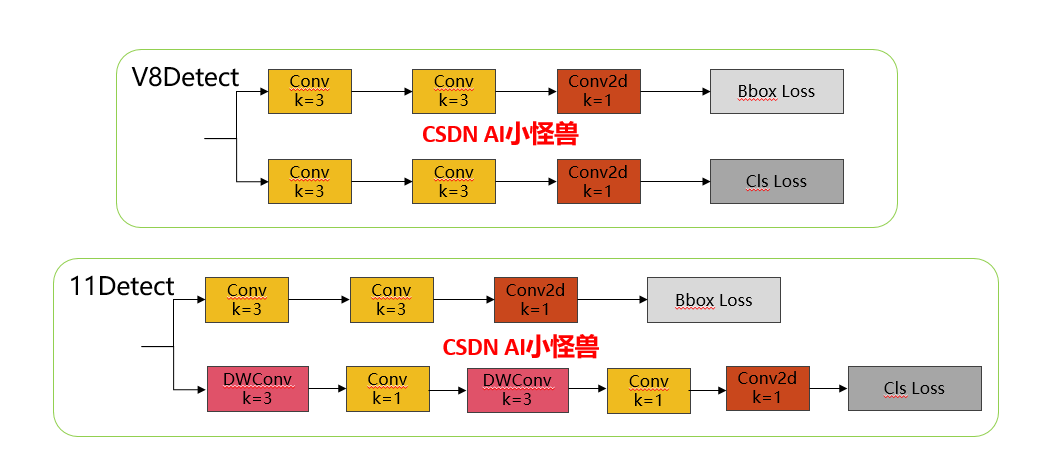
实现代码ultralytics/nn/modules/head.py
self.cv2 = nn.ModuleList(
nn.Sequential(Conv(x, c2, 3), Conv(c2, c2, 3), nn.Conv2d(c2, 4 * self.reg_max, 1)) for x in ch
)
self.cv3 = nn.ModuleList(
nn.Sequential(
nn.Sequential(DWConv(x, x, 3), Conv(x, c3, 1)),
nn.Sequential(DWConv(c3, c3, 3), Conv(c3, c3, 1)),
nn.Conv2d(c3, self.nc, 1),
)
for x in ch
)
1.4 YOLO11和 YOLOv8的区别
------------------------------- YOLO11 ----------------------------------
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs
s: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs
l: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs
x: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs
------------------------------- YOLOv8 ----------------------------------
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
2.如何训练YOLO11模型
2.1 如何训练NEU-DET数据集
2.1.1 数据集介绍
直接搬运v8的就能使用
2.1.2 超参数修改
位置如下default.yaml
2.2.3 如何训练
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO('ultralytics/cfg/models/11/yolo11-EMA_attention.yaml')
#model.load('yolov8n.pt') # loading pretrain weights
model.train(data='data/NEU-DET.yaml',
cache=False,
imgsz=640,
epochs=200,
batch=8,
close_mosaic=10,
device='0',
optimizer='SGD', # using SGD
project='runs/train',
name='exp',
)
2.2.4训练结果可视化结果
YOLO11n summary (fused): 238 layers, 2,583,322 parameters, 0 gradients, 6.3 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 21/21 [00:07<00:00, 2.93it/s]
all 324 747 0.765 0.679 0.768 0.433
crazing 47 104 0.678 0.337 0.508 0.22
inclusion 71 190 0.775 0.705 0.79 0.398
patches 59 149 0.808 0.859 0.927 0.636
pitted_surface 61 93 0.81 0.667 0.779 0.483
rolled-in_scale 56 117 0.684 0.593 0.67 0.317
scratches 54 94 0.833 0.915 0.934 0.544
原文链接:
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号