高效使用Java Logging日志,优秀的程序员都这么做

高效使用Java Logging日志,优秀的程序员都这么做

MaxKey单点登录开源官方
发布于 2024-11-18 20:26:28
发布于 2024-11-18 20:26:28
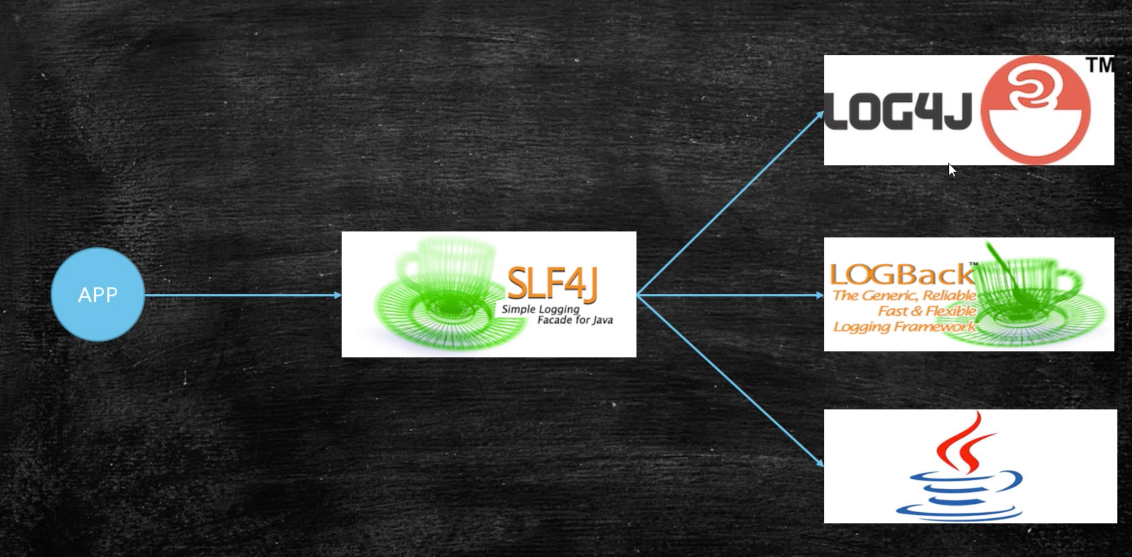
高效的日志记录是任何 Java 应用程序的一个重要方面,它提供了对其运行状态的洞察。它在生产环境中尤其重要,因为它有助于调试、监控和事件响应。在本综合指南中,我们将探讨使用 SLF4J 和 Logback 的有效实践,确保可靠性和可维护的日志记录策略。
通过遵循这些最佳实践,开发人员和运营团队可以利用 SLF4J 和 Logback 将日志转化为应用程序管理和事件解决的战略资源。遵循这些准则将提高可观察性、加快故障排除并更深入地了解系统行为,为应用程序的可靠性和性能奠定坚实的基础。
高效日志优势
- 提高可观察性: 日志提供应用程序行为的详细记录,使您更容易了解系统的运行情况并识别潜在问题。
- 快速故障排除: 良好结构且信息丰富的日志使开发人员能够快速定位问题的根本原因并有效地解决问题。
- 增强事件响应: 日志在事件响应期间非常有价值,它按时间顺序记录了问题发生前和发生期间的事件。
- 合规性和安全性: 日志可以作为遵守合规的证据,并有助于识别安全漏洞或可疑活动。
选择 SLF4J 和 Logback
SLF4J(Java 的简单日志外观)是一种流行的日志外观,它为跨不同日志框架的日志记录提供了一致的 API。Logback 是一种广泛使用的日志框架,它提供了一组丰富的功能和自定义选项。通过将 SLF4J 与 Logback 结合使用,您可以受益于这两种工具的灵活性和强大功能。
在本指南中,我们将介绍在 Java 应用程序中高效使用 SLF4J 和 Logback 的 14 个基本最佳实践。这些实践将帮助您实现可靠、可维护且信息丰富的日志记录,以满足应用程序的运营需求。
1. 使用 SLF4J 作为日志记录外观
🟢 最佳实践:
选择 SLF4J 作为应用程序的日志外观,以将日志架构与底层日志库实现分离。这种抽象允许您在不同的日志框架之间切换,而无需进行重大代码更改。
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class MyClass {
private static final Logger logger = LoggerFactory.getLogger(MyClass.class);
// ...
}🔴 避免实现:
在应用程序代码中对特定的日志框架实现进行硬编码可能会在需要切换库时导致困难。
import org.apache.log4j.Logger;
public class MyClass {
private static final Logger logger = Logger.getLogger(MyClass.class);
// ...
}2. 配置Logback以实现高效日志记录
🟢 最佳实践:
外部化您的 Logback 配置并使用PatternLayout以提高性能和灵活性。为开发、模拟和生产环境定义不同的配置,以更好地管理日志的详细程度和细节。
<configuration>
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
<root level="debug">
<appender-ref ref="STDOUT" />
</root>
</configuration>🔴 避免实现:
使用过时或性能不佳的布局类和代码中的硬编码配置设置可能会难以适应不同的环境。
<configuration>
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<layout class="ch.qos.logback.classic.PatternLayout">
<!-- Non-recommended layout configuration -->
</layout>
</appender>
<!-- ... -->
</configuration>3. 用适当的日志级别
🟢 最佳实践:
以正确的级别记录,以传达消息的重要性和意图。INFO用于一般事件、DEBUG开发过程中的详细信息以及ERROR需要注意的严重问题。
logger.info("应用程序已启动.");
logger.debug("X 的值是 {}", x);
logger.error("无法处理请求.", e);🔴 避免实现:
以相同的级别记录所有内容,可能会使日志文件充满混乱,并且很难发现关键问题。
logger.error("应用程序已启动."); // 错误使用日志级别
logger.error("X 无法处理请求 " + x); // 低效串接
// ...4. 记录有意义的消息
🟢 最佳实践:
在日志消息中包含相关信息(例如事务或关联 ID)以提供上下文。这在分布式系统中跟踪跨服务的请求时特别有用。
logger.info("订单 {} 已处理成功.", orderId);🔴 避免实现:
模糊或通用的日志消息没有提供足够的信息来理解事件或问题。
logger.info("处理成功."); // 无有用信息提供5. 使用占位符来显示动态内容
🟢 最佳实践:
利用占位符来🔴避免实践:在日志级别禁用时不必要的字符串连接,从而节省内存和 CPU 开销。
logger.debug("用户 {} 登录时间是 {}", username, LocalDateTime.now());🔴 避免实现:
在日志语句使用+连接字符串效率较低。
logger.debug("用户 " + username + " 登录时间是 " + LocalDateTime.now());6. 使用堆栈跟踪记录异常
🟢 最佳实践:
始终记录完整的异常,包括堆栈跟踪,以提供用于诊断问题的最大信息。
try {
// 一些可能引发异常的代码
} catch (Exception e) {
logger.error("发生意外错误", e);
}🔴 避免实现:
仅记录异常消息而不记录堆栈跟踪可能会遗漏关键的诊断信息。
try {
// 一些可能引发异常的代码
} catch (Exception e) {
logger.error("发生意外错误: " + e.getMessage());
}7. 使用异步日志记录来提高性能
🟢 最佳实践:
通过将日志记录活动转移到单独的线程来实现异步日志记录,以提高应用程序性能。
<configuration>
<appender name="ASYNC" class="ch.qos.logback.classic.AsyncAppender">
<appender-ref ref="FILE" />
</appender>
<appender name="FILE" class="ch.qos.logback.core.FileAppender">
<file>application.log</file>
<encoder>
<pattern>%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
<root level="INFO">
<appender-ref ref="ASYNC" />
</root>
</configuration>🔴 避免实现:
在性能关键路径中进行同步日志记录,而不考虑与日志相关的延迟的可能性。
logger.info("一个时间敏感的操作已经完成.");8. 以适当的粒度记录日志
🟢 最佳实践:
您应该在记录过多和过少之间取得平衡。根据应用程序的具体要求以适当的粒度进行记录。避免记录过多的日志,因为过多的日志会使日志变得杂乱,难以识别重要信息。
public void processOrder(Order order) {
logger.info("正在处理订单: {}", order.getId());
// 以更精细的粒度日志记录以进行调试
logger.debug("订单详情: {}", order);
// 处理订单
orderService.save(order);
logger.info("订单处理成功");
}🔴 避免实现:
在生产中以高粒度进行过多的日志记录,可能会导致性能问题和日志泛滥。
public void processOrder(Order order) {
logger.trace("进入 processOrder 方法");
logger.debug("查询订单: {}", order);
logger.info("处理订单: {}", order.getId());
// 记录每一步处理过程
logger.debug("步骤 1: 验证订单");
// ...
logger.debug("步骤 2: 计算所有余额");
// ...
logger.debug("步骤 3: 更新库存");
// ...
logger.info("订单处理成功");
logger.trace("退出 processOrder 方法");
}9. 监控和轮换日志文件
🟢 最佳实践:
根据大小或时间配置日志文件轮换,以防止日志占用过多的磁盘空间。设置日志文件监控,以便在接近容量时触发警报。
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>logs/myapp-%d{yyyy-MM-dd}.%i.log</fileNamePattern>
<maxHistory>30</maxHistory>
<timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
<maxFileSize>100MB</maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>
</rollingPolicy>
<!-- ... -->
</appender>🔴 避免实现:
让日志文件无限增长,可能会导致磁盘空间耗尽和潜在的系统故障。
10. 保护敏感信息
🟢 最佳实践:
在日志框架中实现过滤器或自定义转换器,以便在敏感数据写入日志之前对其进行替换或哈希处理。
log.info("处理支付使用银行卡: {}", maskCreditCard(creditCardNumber));
public String maskCreditCard(String creditCardNumber) {
int length = creditCardNumber.length();
if (length < 4) return "卡号无效";
return "****-****-****-" + creditCardNumber.substring(length - 4);
}🔴 避免实现:
记录敏感信息,例如密码、API 密钥、信用卡或个人身份信息 (PII)。
log.info("处理支付使用银行卡: {}", creditCardNumber);11. Structured Logging 结构化日志
🟢 最佳实践:
采用结构化日志记录,以 JSON 等机器可读的格式输出日志,方便在日志管理系统中更好地搜索和索引。
<configuration>
<appender name="JSON_CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder">
<providers>
<timestamp>
<timeZone>UTC</timeZone>
</timestamp>
<version />
<logLevel />
<threadName />
<loggerName />
<message />
<context />
<stackTrace />
</providers>
</encoder>
</appender>
<root level="info">
<appender-ref ref="JSON_CONSOLE" />
</root>
</configuration>我们来看一个以 JSON 格式打印的示例日志消息:
logger.info("订单已经被处理");上述日志消息的输出将打印如下:
{"@timestamp":"2024-03-26T15:52:00.789Z","@version":"1","message":"Order has been processed","logger_name":"Application","thread_name":"main","level":"INFO"}🔴 避免实现:
使用难以通过编程解析和分析的非结构化日志格式。
12. 与监控工具集成
🟢 最佳实践:
将您的日志与监控和警报工具相链接,以自动检测异常并通知相关团队。
🔴 避免实现:
忽视日志与监控系统的集成可能会延迟问题的检测。
13. 日志聚合
🟢 最佳实践:
在分布式环境中,使用集中式日志聚合来收集来自多个服务的日志,简化事件的分析和关联。
🔴 避免实现:
允许日志分散在各个系统中,使得故障排除过程变得复杂。
14. 智能日志记录
使用 AOP 实现智能日志记录的内容。
References参考
总结
高效的日志记录不仅仅是捕获数据;它还涉及在正确的时间以正确的格式捕获正确的数据。通过实施这些最佳实践,开发和运营团队可以利用 SLF4J 和 Logback 将日志转化为应用程序管理和事件解决的战略资源。
遵循这些指导原则将提高可观察性、加快故障排除速度、更深入地了解系统行为,为应用程序的可靠性和性能奠定坚实的基础。
本文系外文翻译,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文系外文翻译,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号