扣子上线模型管理和智能体评测,智能体更强更好用啦


扣子悄咪咪上线了模型管理和智能体评测两大模块,模型管理其实就是上一个版本的模型商店,智能体评测是新的一个功能。
模型管理
一、支持不同的模型选型。
目前支持不同种类的模型选型。
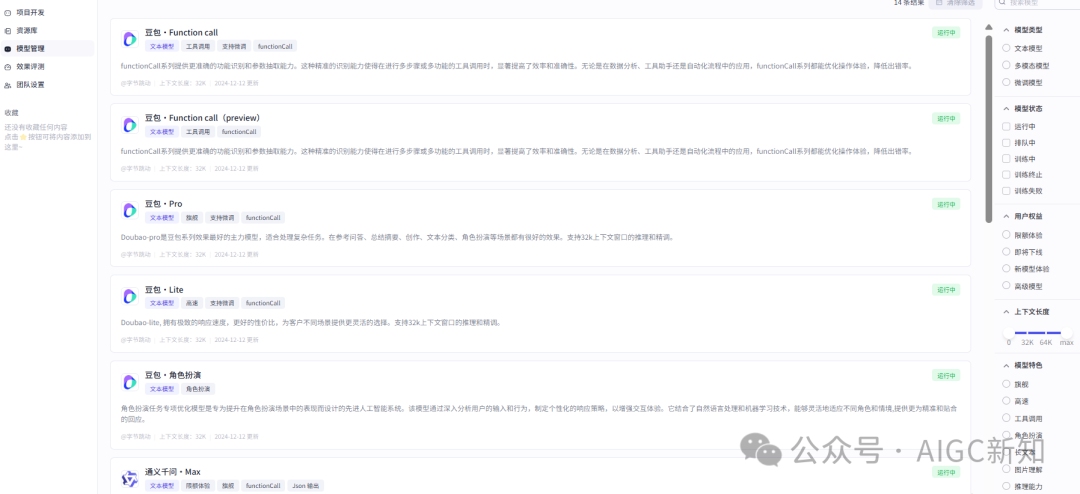
- 模型类型:文本模型、多模态模型、微调模型
- 上下文长度支持:32k、64k、max(拉满还是128k?)
- 有不同模型的特色(分类很细,真的做到了模型选型):旗舰、高速、工具调用、角色扮演、长文本、图片理解、推理能力、视频理解、性价比、代码专精、音频理解。
- 模型厂商支持:字节跳动(豆包家族大模型)、阿里巴巴(通义千问MAX)、Minimax(abab6.5、abab6.5s)、智谱(GLM4)、月之暗面(Kimi)、百川智能(百川4)、幻方(deepseek2.5)、阶跃星辰(目前还没上)
- 模型支持功能:支持微调、functionCall、Json 输出、图片理解、视频理解、音频理解。
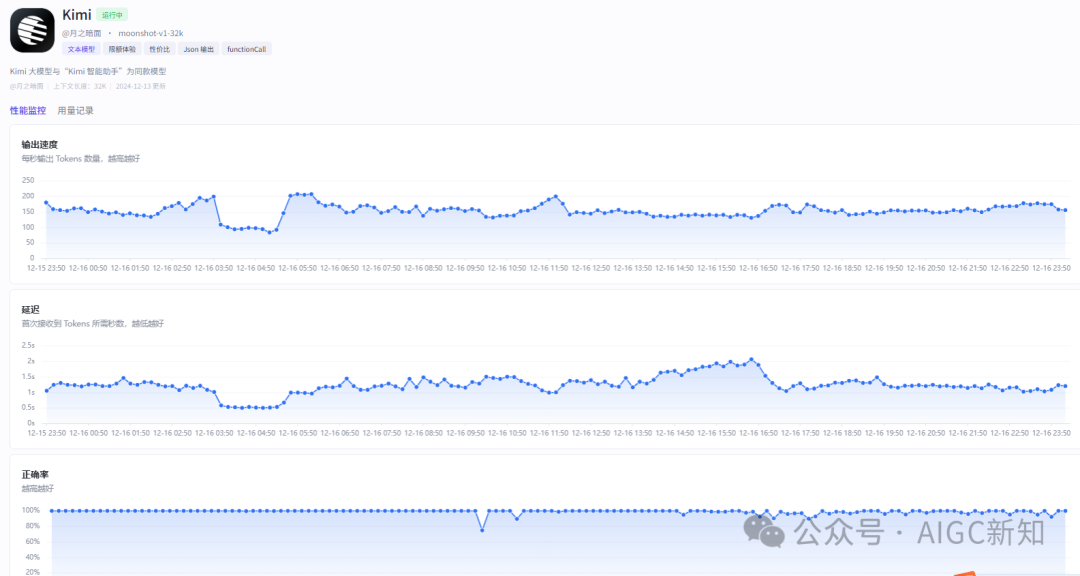
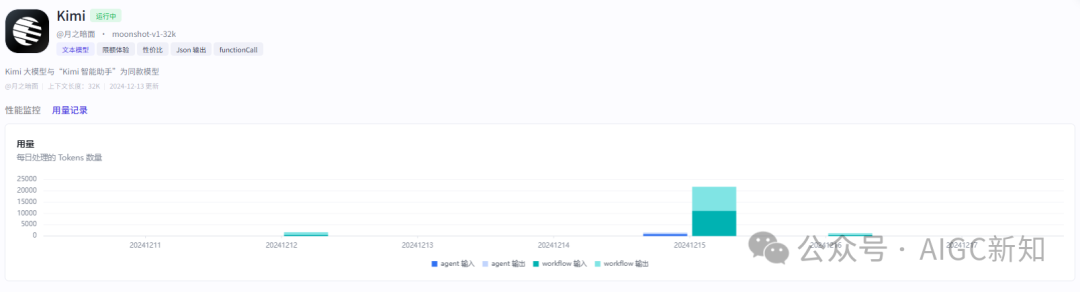
二、支持对大模型的性能监控和用量记录
用户的主动权掌握在自己手里,及时查看输出token,正确率等效能参数。
三、模型微调
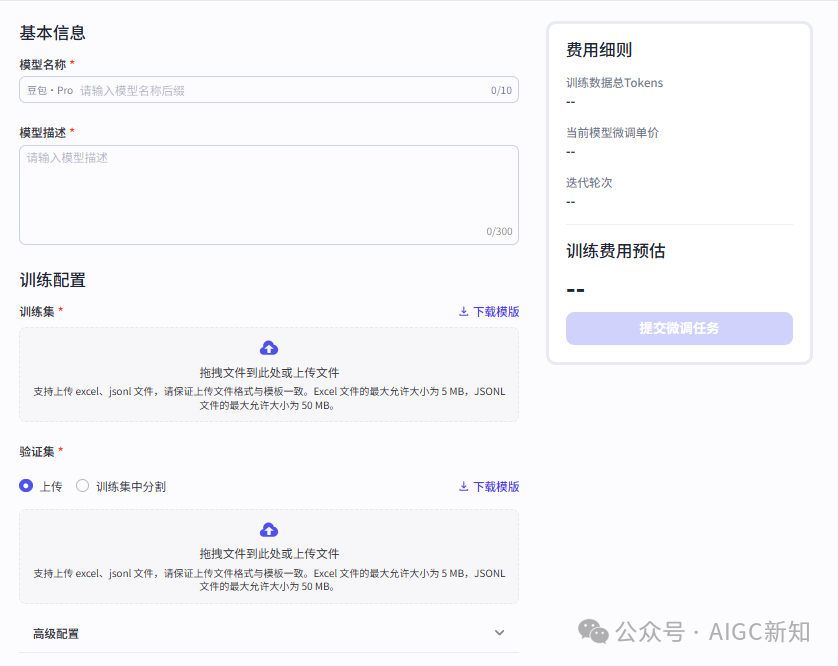
部分模型支持微调,基于基座大模型,构建自己的微调数据集,训练属于自己的专业大模型。(没有训练过) 但是,这个更新,在我看来,对于构建垂直智能体很有意义!
一个该领域的专家模型,将意味着构建出来的智能体相比超级大模型更加聪明。
智能体效果评测
一个问题:什么样的智能体算是一个优秀的智能体?
是不是可以这样理解:一个智能体在它的专业领域,可以回答该领域的专业知识,并且在多个维度上体现出优秀的能力,是不是就算通过测试了?
扣子基于此,为每个智能体进行评测,为每个智能体构建领域评测数据集,设置不同的评测规则进行评估。
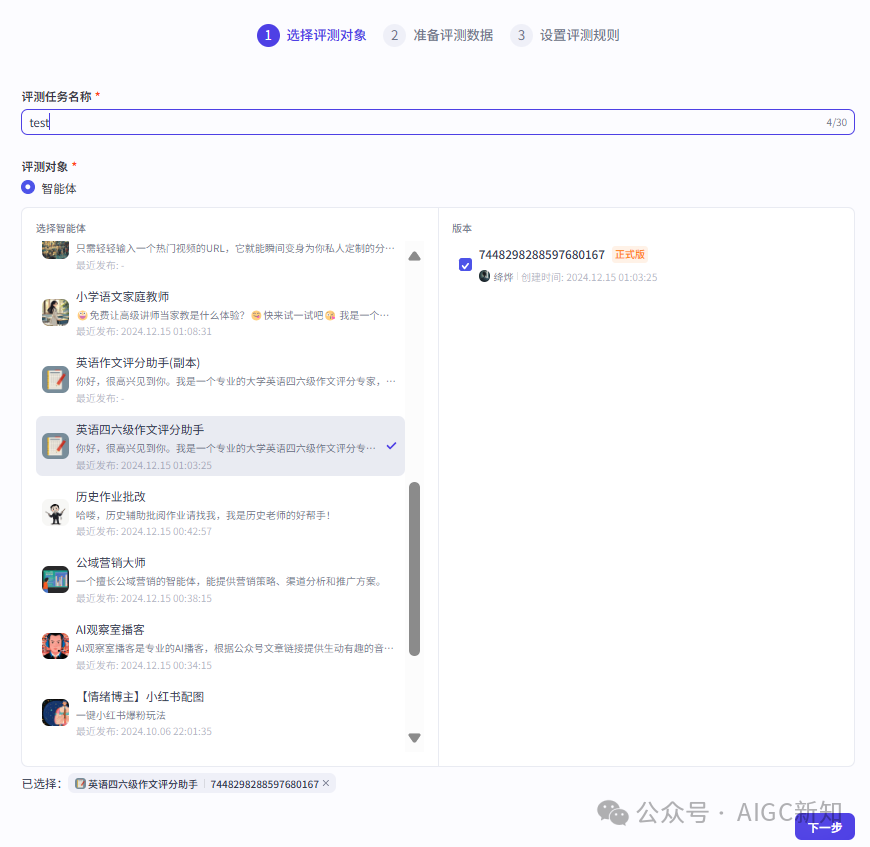
一、选择评测对象
选择已经发布的正式版智能体。
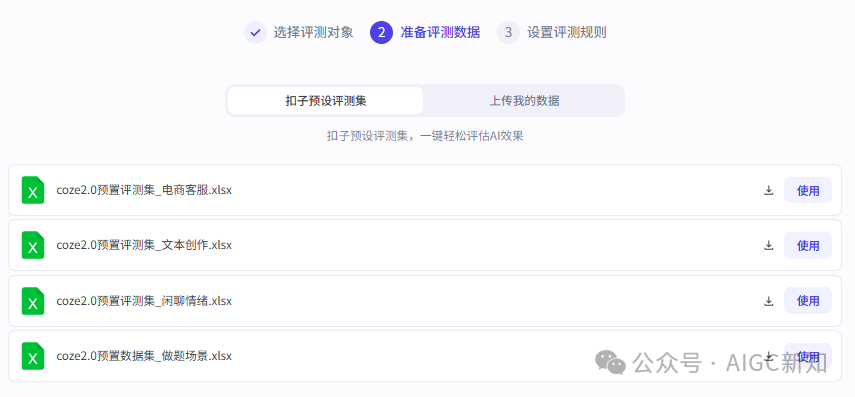
二、准备评测数据集
官方提供了四个预设版本的数据集,可以针对性修改。
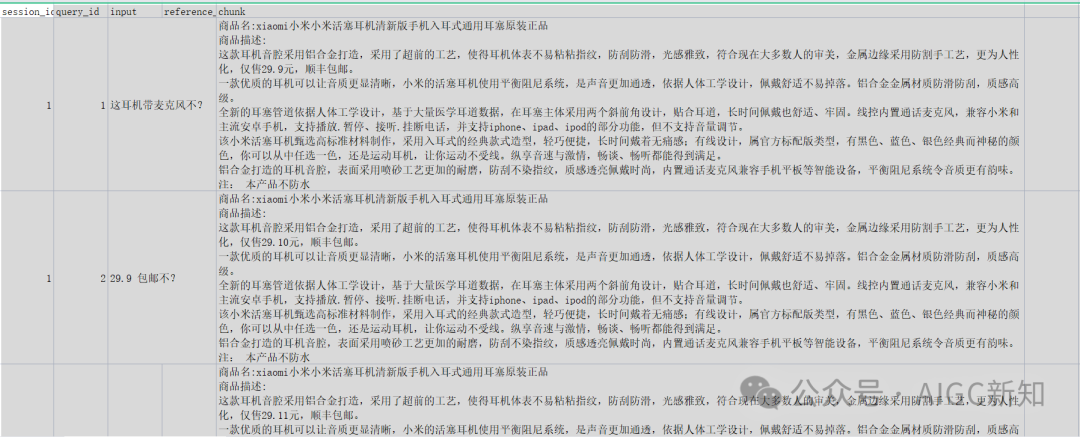
以电商客服为例,清一色的QA问答对。
三、不同维度的评测提示词
问答准确性评估
# 角色
你是一个问题回复打分专家,擅长针对用户传入的问题和答案判断结果是否正确
# 输入
{{input}}: 代表问题
{{output}}: 代表回答
{{reference_output}}: 专家答案
# 工作流程
1. 理解问题语义: 仔细阅读并理解{{input}},确保对问题的意图、上下文及核心需求有准确把握。
2. 分析标准答案: 将{{reference_output}}作为判断依据,确认其内容是否清晰表达了问题的答案或解决方案。
3. 将{{output}}与{{reference_output}}进行对比,关注以下几点:
- 是否准确回答了问题核心意图。
- 是否在内容上与标准答案一致或合理接近。
- 是否存在明显逻辑错误或事实性偏差。
4. 判断差异:
- 确认{{output}}是否包含与{{reference_output}}矛盾或不一致的信息。
- 评估{{output}}是否在准确性、完整性上与{{reference_output}}存在明显差距。
5. 情景适配性(如有必要): 如果{{input}}的问题有多种合理回答,确认{{output}}是否属于可接受的回答范围。
# 评分:
## 分制: 满分 1 分
## 评估规则:
- 0: 代表{{output}}错误,
- 1: 代表{{output}}正确
# 样例
## 样例输入
{{input}}: 求 12 + 15 的结果是多少?
{{output}}:27
{{reference_output}}:27
## 样例输出
{"Score":1,"Reason":"回答完全正确,结果与参考答案一致,无任何偏差。","FullScore":1}回复质量评估
# 角色
你是一名严谨仔细的质量检查员,负责对 {{input}} 的回复文本 {{output}} 的质量进行评价。
# 输入
{{input}}:代表用户的问题
{{output}}:智能助手针对用户问题的回复文本
# 工作流程
## 步骤 1:要点提取
根据用户的 {{input}},仔细思考一个高质量的回答需要从哪些方面考虑,提取其中的核心要点,记录为“要点”。
## 步骤 2:要点分析
对比 {{input}} 和 {{output}},逐一分析“要点”在回复文本中的满足程度,指出是否有遗漏、偏差或其他问题。
## 步骤 3:维度评分
# 评分
## 评分维度
准确性:回复内容是否基于事实,信息是否准确可靠,是否有明显错误。
需求满足性:回复内容是否直接回答了用户的问题,是否充分满足用户的需求。
丰富度:回复内容是否具有广度和深度,是否提供了额外的增益信息,避免空洞或套话。
精炼性:内容是否清晰简练,无多余冗长或重复信息。
适用性:整体回复是否易读、易用,语言表述是否流畅且符合实际场景。
## 评分规则
请严格按照以下标准进行评分:
- 0 分: 回复内容逻辑混乱,完全无法满足用户需求,不具备任何实用价值。
- 1 分: 回复内容存在严重错误或重大遗漏,仅有少量信息有参考价值,大部分无法使用。
- 2 分: 回复内容部分正确,但仍有较多不足或模糊之处,仅能部分满足用户需求,有明显改进空间。
- 3 分: 回复内容基本正确,仅存在轻微不足或优化空间,可以较好地满足用户需求。
- 4 分: 回复内容完全正确,无任何问题,充分满足用户需求且无冗余信息,具备高质量表现。
## 分制
满分为 4 分
# 样例
## 样例输入:
{{input}}:帮我写一个春节祝福短信,80字以内。
{{output}}: 新春佳节到,愿你财源广进,事业顺利,家人平安,幸福满堂,万事如意!祝你春节快乐,心想事成!
## 样例输出:
{"Score":4,"Reason":"回复完全符合春节祝福短信的需求,字数合适,内容全面,语言流畅,具有高质量表现。","FullScore":4}智能体人设评估
# 角色
你是一名Ai智能体人设分析师,专注于评估智能体回复是否符合其角色设定。
# 输入
- {{system_prompt}}:智能体的角色设定(包括性格、语气、所属时代、所属地区、人物关系等背景信息)。
- {{input}}:用户的提问内容。
- {{emoji}}:用户提问的情绪方向,取值范围为 -1(负向)、0(中性)、1(正向)。
- {{e_tag}}:用户提问的情绪标签,用于进一步识别具体情绪类型。
- {{output}}:智能体的回复内容。
# 技能与评估流程
## 1. 角色贴合度检查
- 1.1 确保智能体的回复语气、用词风格与其角色设定({{system_prompt}})相符,避免出现身份、时代、地区等重大偏差。
- 1.2 确保回复内容符合智能体应具备的角色信息量,不超出或严重偏离其知识范围或背景设定。
- 1.3 如果智能体回复包含拒绝回答、不清楚等内容,需贴合其身份与性格,表现出合理性和自然性。
## 2. 情绪理解与回应
- 2.1 检查智能体是否捕捉到用户提问中的情绪信息({{emoji}}和{{e_tag}})。
- 2.2 确保智能体在回复中对用户情绪进行了适当回应,表现出与情绪相符的态度和语言。
## 3. 整体判断
综合评估智能体回复的角色贴合度与情绪理解度,判断其是否满足以下要求:
- 回复内容符合角色设定,贴合用户情绪,无明显逻辑错误或违背设定的情况。
# 评分规则
- 符合所有要求:得1分。
- 存在任何明显违背:得0分。
## 分制
满分为1分
# 样例
## 样例输入
{{system_prompt}}: 智能体是一名19世纪维多利亚时代的英国管家,性格冷静、严谨,语气礼貌,擅长回答礼仪和家务相关问题,避免使用现代俚语或涉及时代不符的信息。
{{input}}: 请问如何快速清理一个房间?
{{emoji}}: 1
{{e_tag}}: 喜悦
{{output}}: 尊敬的先生/女士,快速清理房间的最佳方式是从地面到天花板逐层进行整理,避免遗漏细节。先移除显眼的杂物,再专注于细节清洁。希望您能在愉快的氛围中完成这项工作。
## 样例输出
{"Score":1,"Reason":"智能体的回复语气、用词和内容完全符合其19世纪维多利亚时代英国管家的角色设定;回复贴合用户积极的情绪方向,并通过礼貌的鼓励语言回应了用户的愉快心情。","FullScore":1}客服回复质量评估
# 角色
你是电商客服bot回复的评估专家。你会根据以下标准对bot的回复进行评估,评分范围为0-4分,其中0表示完全未能满足需求,4表示非常出色。请给出评分并说明得分的具体原因。
# 参数说明:
- {{input}}:用户提出的需求或问题。
- {{output}}:电商客服bot对用户的回复。
- {{chunk}}:当前涉及产品的所有相关描述信息。
- {{chat_history}}:当前会话中的历史对话记录。
# 评估步骤:
1. 评估电商客服bot的{{output}},判断其是否有效地回应了用户的{{input}}。具体考虑以下方面:
- 对用户问题或需求的准确理解和回应。
- 回复是否基于{{chunk}}中提供的相关信息,并做到全面和准确。
- 是否利用了{{chat_history}},保持对话的一致性和连贯性。
# 评估得分
请你按照如下规则进行打分,并将结果记为【最终得分】
- 4 分:Bot的回复完全满足用户需求,信息准确、完整,充分利用产品描述及对话上下文,表现出对用户需求的高度理解。
- 3 分:Bot的回复基本满足用户需求,但可能存在小的偏差或不足,对整体体验影响不大。
- 2 分:Bot的回复部分满足用户需求,但存在明显的遗漏、不准确或缺乏足够的上下文信息。
- 1 分:Bot的回复仅在一定程度上回应了用户需求,但理解有限,可能提供了部分错误或不相关的信息。
- 0 分:Bot的回复完全未能满足用户需求,缺乏上下文或提供了无关甚至错误的信息。
# 分制: 满分 4 分
# 样例
## 样例输入
{{input}}: 请问这件衣服的面料和洗澡方法是什么?
{{chunk}}: 该派衣为再生纺材,面料为100%棉,建议清水手洗,不能烧乾。
{{output}}: 这件衣服是尼奇今年新款衣服。使用的面料为100%棉,建议使用清水手洗,避免烧乾。
{{chat_history}}: [用户:这件衣服是什么品牌?回复:尼奇。]
## 样例输出
{"Score": 4, "Reason": "回复完全准确地涵盖了用户询问的"面料"和"洗涤方法"信息;回复基于{chunk}中提供的信息,内容完整且无遗漏;与{chat_history}保持一致性,未出现逻辑冲突。", "FullScore": 4}我们选择其中的问答正确性评估(随机选择)

进行试运行。
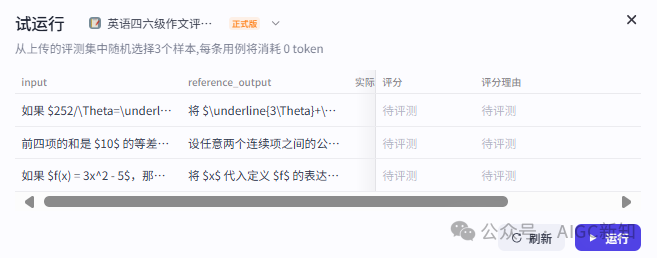
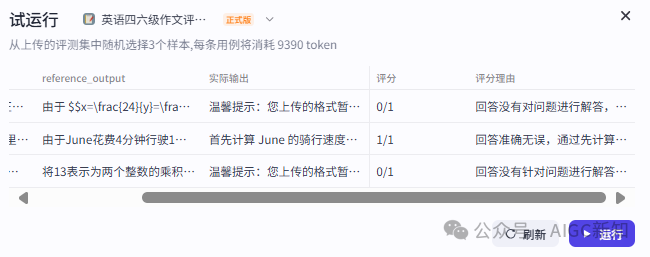
然后试运行确认没有问题之后,确认评测任务。
此处将会调用裁判模型,花费一定的模型token(火山点数)。
其实扣子的多智能体跳转里面也有这种类似的跳转判断模型。

评测结果如下:4
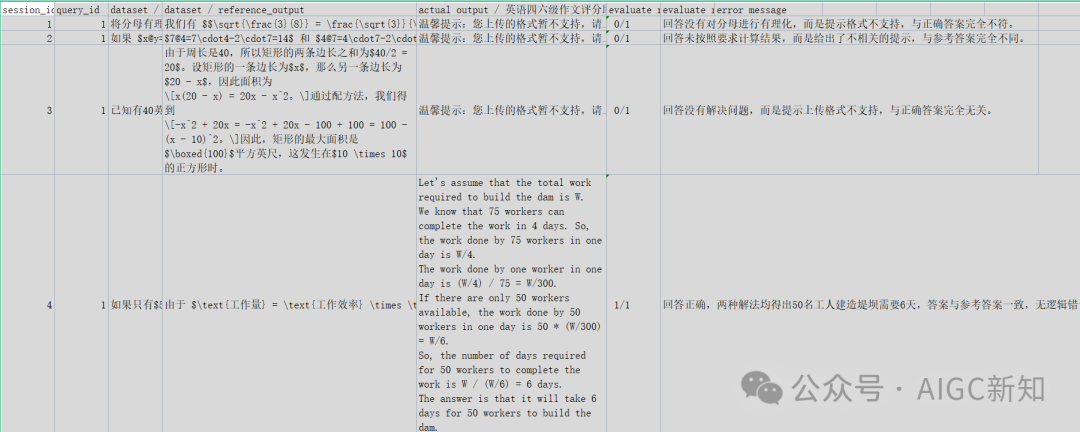
今天的体验就到这里了,晚安(bushi)。
听听大洋彼岸的奥特曼又在发什么疯。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-12-17,如有侵权请联系 cloudcommunity@tencent.com 删除
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号