2024 年 11 月 Apache Hudi 社区新闻

2024 年 11 月 Apache Hudi 社区新闻

ApacheHudi
发布于 2024-12-20 16:58:01
发布于 2024-12-20 16:58:01

最新发布的 Hudi-rs 0.2.0 延续了首个版本的势头,为 Rust 和 Python 生态系统中的数据湖平台带来了更多功能。Hudi-rs 让无需 JVM 就能与 Hudi 表进行交互成为可能,为轻量级、高性能的工作流开辟了新的机遇。
感谢所有为此版本做出贡献的同学。请在这里查看发布说明[1]。
社区活动
亚马逊的 Nexus:使用 Hudi 实现运营扩展
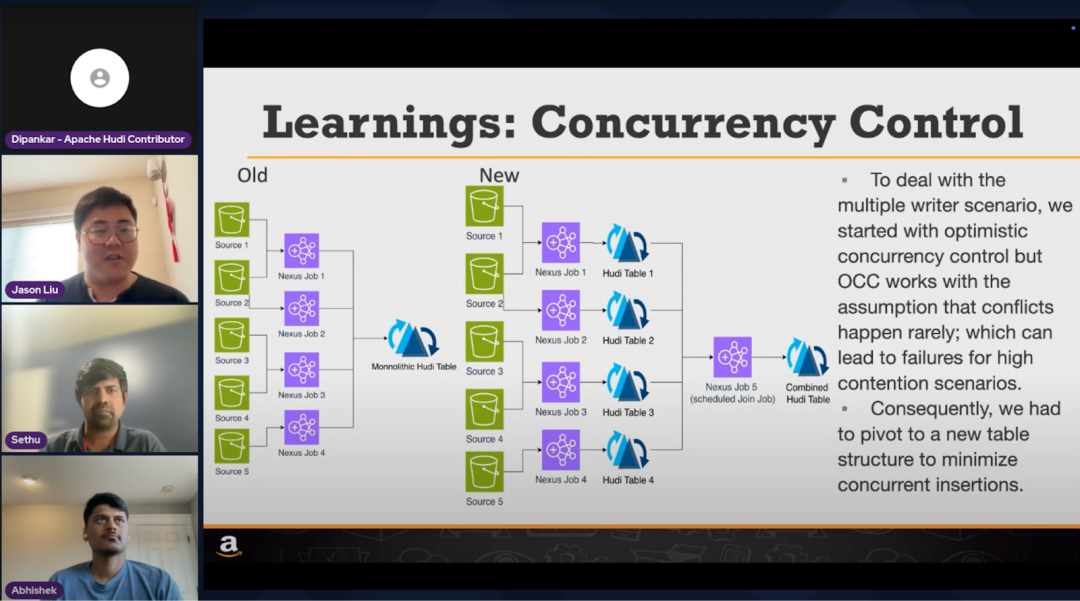
在最新的社区同步会议中,亚马逊工程团队分享了他们构建 Nexus 的见解,这是一个基于配置驱动的系统,用于扩展运营并快速引入新业务。Nexus 使亚马逊的财务团队能够通过配置在其基于 Hudi 的数据湖中定义工作流程、业务逻辑和数据持久化。如果您错过了会议,可以在这里观看录像[2]。
Lakehouse 编年史第三集:从 PostgreSQL 到数据湖仓
在《Apache Hudi 数据湖仓编年史》第三集中,Soumil Shah 演示了如何通过将数据从业务数据源引入数据湖仓来解决实际的变更数据捕获(CDC)挑战。本次会议包含了一个实操演示,涵盖以下内容:
- • 使用 Debezium 从 PostgreSQL 捕获变更
- • 发布到 Kafka 主题
- • 在持续模式下使用 Hudi Streamer 进行数据摄取
- • 通过 Trino 查询已摄取的数据
对于处理 CDC 管道的数据工程师来说,这一集是必看内容。您可以在这里查看这个精彩系列的所有往期内容[3]!
Hudi at PrestoCon

在 PrestoCon 大会上,Hudi 工程团队发表了题为《使用 Apache Hudi 提升 Presto 的查询效率和数据管理》的演讲。这次演讲追溯了 Presto-Hudi 连接器从基于 Hive 的初始形态到当前先进功能的演进历程。
博客
Hudi 的自动文件大小调整带来卓越的性能提升 - Aditya Goenka[4]
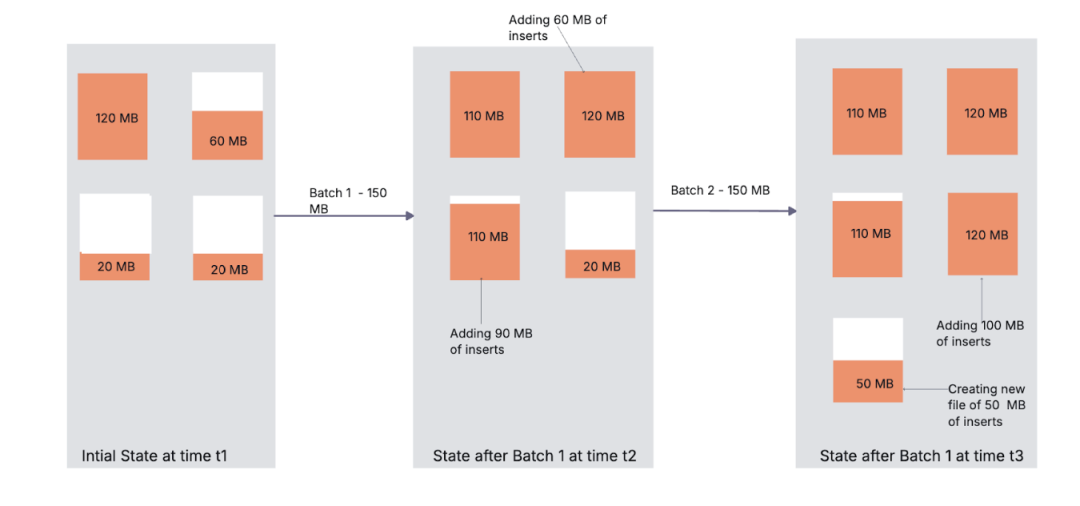
在数据湖中管理小文件是一个常见的挑战,会导致存储和查询性能低下。这篇博客探讨了 Apache Hudi 如何通过自动化的文件大小调整来解决这个问题,在数据摄取过程中利用装箱算法来优化数据布局。
Apache Hudi 中的记录级索引 - Bibhu Pala[5]
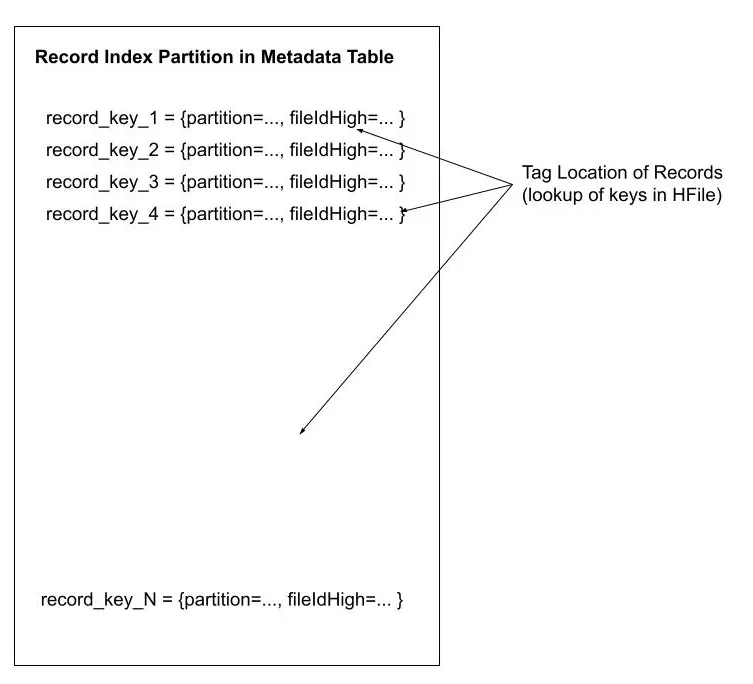
在这篇博客中,Bibhu Pala 深入探讨了 Hudi 中记录级索引的概念。博客讨论了这项功能如何通过基于主键快速识别记录来提高数据检索效率,从而提升查询性能并降低存储成本。文章还强调了简化数据源接入的优势,以及在计算和存储费用方面的显著节省。
深入理解 Apache Hudi 中的 CoW 和 MoR:选择正确的存储策略 - Deepak Nishad[6]

Deepak 探讨了 Apache Hudi 中的两种主要存储类型:写时复制(Copy-On-Write,CoW)和读时合并(Merge-On-Read,MoR)。这篇博客概述了每种策略的独特特点和使用场景,就如何根据特定工作负载需求选择合适的方法提供了指导。
在 EMR Serverless 上运行 Spark Streaming Hudi 作业 - Soumil Shah[7]
在这篇博客中,Soumil Shah 提供了一份在 Amazon EMR Serverless 上使用 Apache Hudi 执行 Spark Streaming 作业的实用指南。文章包含了环境搭建、作业部署的详细步骤说明,以及可扩展且具有成本效益的流处理最佳实践。对于希望利用 Serverless 平台进行数据处理的从业者来说,这是一份非常有价值的参考资源。
社交平台
另一个激动人心的消息是,Apache Hudi 的 LinkedIn 页面[8]粉丝数达到了 10,000 的里程碑!🎉社区是开源项目成功的关键。衷心感谢这个令人难以置信的社区中的用户、贡献者、提交者和 PMC 成员们一直以来的支持与合作。

Hudi 开发更新
- • PR#12206[9]:Hudi 写入器现在支持写入与版本
6兼容的日志格式,确保与旧系统更好的兼容性,同时保持对最新版本8的支持。 - • PR#11923[10]:重构使 Hudi 能够无缝处理不同版本兼容性的写入和读取,使混合环境的管理更加容易。
- • PR#12327[11]:增加了对表版本 8 的平滑升级和降级操作的支持,进一步提升了灵活性。
- • PR#12262[12]:新的
truncate table过程使通过 Spark SQL 直接删除数据变得更简单。 - • PR#12222[13]:引入了
drop partition过程,可通过 Spark SQL 轻松管理分区。 - • PR#12310[14]:新的
hoodie.metadata.index.column.stats.max.columns配置将列统计生成限制为 32 列,优化了宽表的性能。 - • PR#12219[15]:添加了 SLF4j 指标报告器,可以直接将指标输出到日志中,提供了一个轻量级的监控解决方案。
Hudi 快速开始
❤️⭐️ https://github.com/apache/hudi
Spark
https://hudi.apache.org/docs/next/quick-start-guide
Flink
https://hudi.apache.org/docs/next/flink-quick-start-guide
欢迎关注 Hudi 公众号 ApacheHudi 获取微信群信息,加入钉钉群:35087066,发送空邮件至 dev-subscribe@hudi.apache.org[16] 参与讨论。
引用链接
[1] 发布说明: https://github.com/apache/hudi-rs/releases/tag/release-0.2.0
[2] 观看录像: https://www.youtube.com/watch?v=rMXhlb7Uci8
[3] 往期内容: https://youtube.com/playlist?list=PLxSSOLH2WRMNQetyPU98B2dHnYv91R6Y8&feature=shared
[4] Hudi 的自动文件大小调整带来卓越的性能提升 - Aditya Goenka: https://hudi.apache.org/cn/blog/2024/11/19/automated-small-file-handling/?utm_source=chatgpt.com
[5] Apache Hudi 中的记录级索引 - Bibhu Pala: https://medium.com/@prasadpal107/record-level-indexing-in-apache-hudi-0615804608ec
[6] 深入理解 Apache Hudi 中的 CoW 和 MoR:选择正确的存储策略 - Deepak Nishad:
[7] 在 EMR Serverless 上运行 Spark Streaming Hudi 作业 - Soumil Shah: https://www.linkedin.com/pulse/learn-how-run-spark-streaming-hudi-jobs-new-emr-serverless-shah-gqlje/?trackingId=vxiImsA5QKid3LDqw1bjiw%3D%3D
[8] LinkedIn 页面: https://www.linkedin.com/company/apache-hudi/
[9] PR#12206: https://github.com/apache/hudi/pull/12206
[10] PR#11923: https://github.com/apache/hudi/pull/11923
[11] PR#12327: https://github.com/apache/hudi/pull/12327
[12] PR#12262: https://github.com/apache/hudi/pull/12262
[13] PR#12222: https://github.com/apache/hudi/pull/12222
[14] PR#12310: https://github.com/apache/hudi/pull/12310
[15] PR#12219: https://github.com/apache/hudi/pull/12219
[16] dev-subscribe@hudi.apache.org: mailto:dev-subscribe@hudi.apache.org
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-12-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号