B站标签系统建设实践
原创
B站标签系统建设实践
原创
哔哩哔哩技术
修改于 2024-12-26 15:41:01
修改于 2024-12-26 15:41:01
01 背景
标签系统是一种用于组织和分类信息的技术,它广泛应用于内容管理、搜索引擎优化(SEO)、推荐系统和用户行为分析等多个领域。随着数据科学的发展,标签系统可以更有效地从大量数据中提取有用信息,实现智能分类和推荐。AI和ML技术的应用使得标签系统能够自学习和适应,提高标签生成的准确性和个性化推荐的效果。云计算提供了弹性的计算资源,大数据技术则为处理和分析海量数据提供了可能。
一个好的标签系统,可以帮助公司更高效地管理和检索内部和外部信息,提高工作效率;通过提供个性化的标签推荐,公司可以增强用户满意度和忠诚度,同时可以更好地分析用户行为和市场趋势,支持数据驱动的决策制定。B站标签系统在2021年立项时的初衷是解决业务侧频繁的adhoc查询问题,提高效率并节约资源。然而,随着时间的推移,系统在2022年中旬遇到了一些挑战,这些问题促使公司重新审视并启动了标签系统的建设。
遇到的问题:
- 性能瓶颈:随着查询量和频率的增加,现有的标签系统计算方式已经达到了性能瓶颈。
- 缺乏规范:没有统一的标签体系建设规范,导致数据源接入和标签配置需要平台人员手动操作,效率低下。
- 重复建设:由于数据来源和业务的多样性,业务侧建设了多个定制化的类标签系统,这些系统虽然满足了特定需求,但缺乏通用性,造成了资源的重复投入。
- 对接不规范:下游业务应用对接缺乏规范和系统层面的管理,导致效果回收链路没有建设,影响了整体的业务流程和数据流转效率。
建设目标:
1.加速和巩固数据链路:
- 数据源接入和标签建设:开放给全站业务,允许自助操作,同时平台需明确规范标准并建立审批流程。
- 多源存算引擎:引入以提升数据链路的稳定性和性能。
2.打造全站通用的标签系统:
- 对外连通:与数据平台和各业务应用平台实现连通,确保数据和应用的无缝对接。
- 对内整合:整合其他数据应用产品,构建一个全站统一的标签系统。
02 架构设计
2.1 实施策略
为实现标签系统的系统化建设,提高整个数据链路的效率和稳定性,我们从以下6个方面实施标签系统的重构:
- 技术升级:对现有标签系统进行技术升级,引入更高效的计算方法和存储解决方案。
- 建立标准:制定明确的标签建设和数据接入标准,简化操作流程,提高自动化水平。
- 平台化管理:建立统一的平台化管理机制,实现标签的集中管理和监控。
- 用户参与:鼓励业务侧用户参与标签系统的建设,提供反馈,以用户需求为导向优化系统。
- 跨部门协作:加强不同部门之间的协作,共同推动标签系统的建设和优化。
- 效果评估:建立效果评估机制,定期检查标签系统的性能和业务效果,确保持续改进。
2.2 整体框架
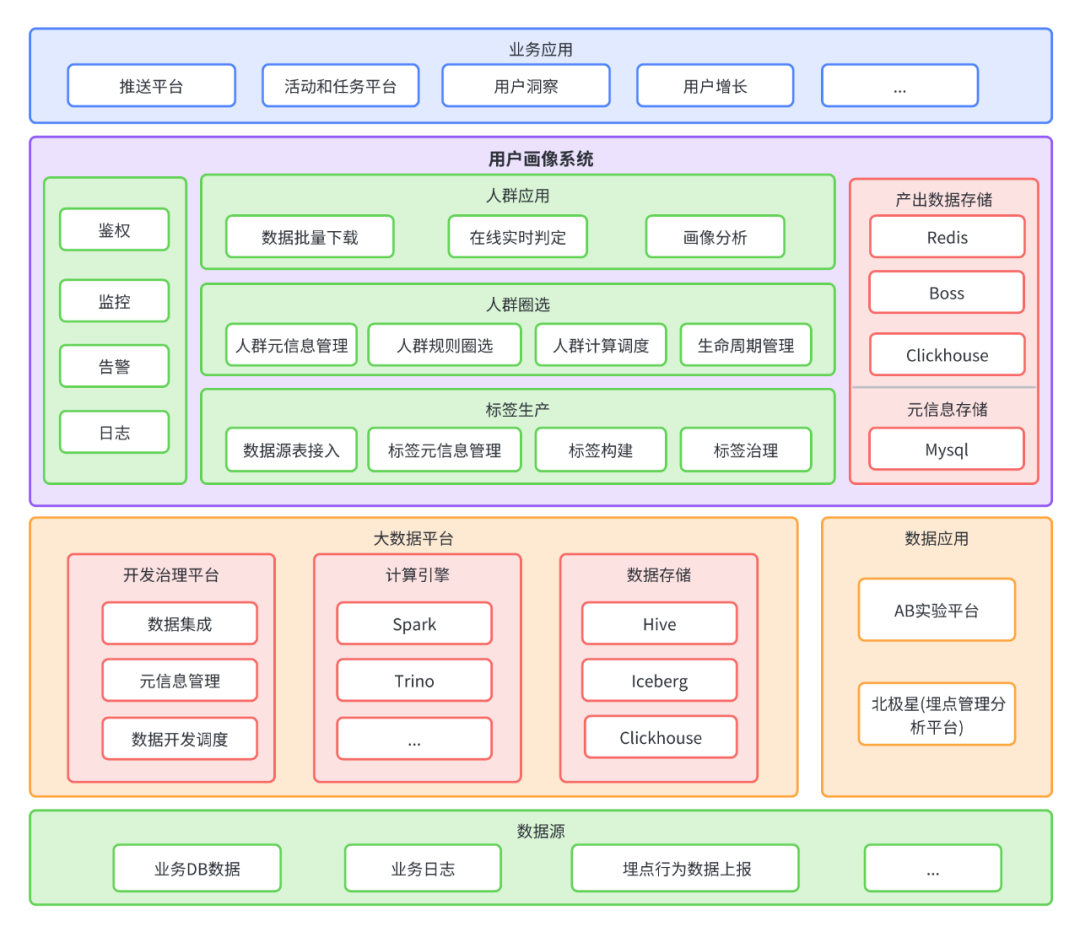
系统整体架构从下到上可以分为三个层级,依次为标签生产、人群圈选、人群应用。
2.2.1 标签生产
标签生产作为标签系统最下面一层是整个系统的基础,需遵循一系列有序的构建阶段,以确保系统的稳定性、准确性和对业务需求的适应性。这些阶段包括标签的定义、预构建和预生产,每个阶段都承载着其独特的目的和重要性。
标签定义阶段是构建过程的起点,其核心在于确立标签的业务意义和使用场景。在此阶段,技术团队与业务利益相关者紧密合作,通过需求分析来明确标签的预期用途和业务目标的一致性。接着,进行属性设计,定义每个标签的名称、描述、分类和适用对象等关键信息。此外,制定标签生成的逻辑规则,确定基于哪些数据源和条件来生成标签,为后续的实现打下基础。
构建阶段的目的在于验证标签生成逻辑的正确性。在此阶段,开发团队将基于定义阶段的规则,开发标签生成的原型。这不仅验证了逻辑的准确性,还对性能进行了初步评估,确保标签生成逻辑在处理大规模数据时的可行性和效率。
生产阶段是标签的线上部署阶段,会对标签的更新周期、生产调度、质量监控等进行配置,确保系统在各种条件下都能稳定运行。
通过这三个阶段的有序推进,技术团队能够逐步识别和降低风险,确保标签系统的稳定性和可靠性。同时,这也保证了标签的质量和性能满足生产要求,提高了业务团队的使用效率,优化了资源使用。
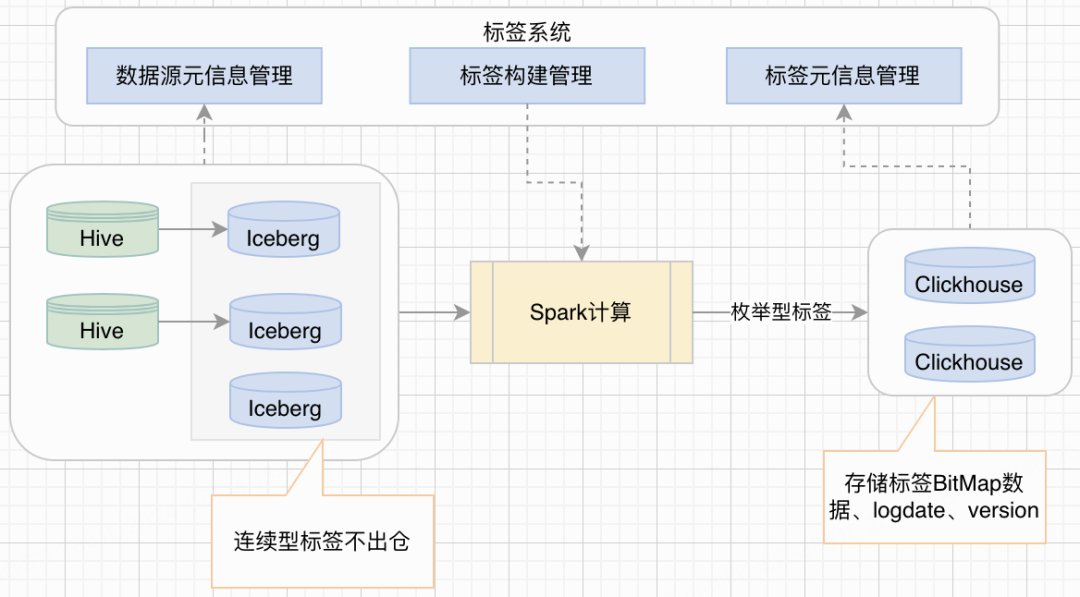
离线标签生产过程如下图所示:
图片
数据源接入标签系统后,系统会在大数据平台自动创建对应的Spark离线计算任务,并每天零点触发任务进行标签构建。数据源接入和标签生产过程中系统会记录标签和数据源表字段绑定的元信息以及标签构建结果元信息,是下一个环节人群圈选的必要输入。
2.2.2 人群圈选:
在构建人群圈选系统时,提供多样化的创建方式是满足不同业务需求的关键。以下是对不同人群创建方式的分析和技术实现要点:
规则和行为创建人群
- 标签引擎:开发一个灵活的标签引擎,允许用户根据标签组合来定义人群。
- 行为分析:集成用户行为分析工具,以识别符合特定行为模式的用户群体。
- 实时处理:对于需要实时反馈的场景,集成流处理技术。
导入Excel创建人群
- 数据导入接口:提供一个稳定高效的数据导入接口,支持大文件上传和处理。
- 数据验证:在导入过程中实施数据验证,确保数据质量和一致性。
- 用户界面:设计直观的用户界面,简化Excel文件的上传和人群定义过程。
根据HTTP链接创建人群
- URL解析:开发服务解析外部链接指向的数据,并将其导入系统。
- 数据同步:实现数据同步机制,确保链接更新时人群信息也随之更新。
基于Hive表创建人群
- 数据库集成:与Hive数据库紧密集成,直接从数据表中提取人群信息。
- SQL查询:允许用户编写SQL查询来定义人群,提高灵活性。
同步DMP人群包
- 系统集成:与数据管理平台(DMP)集成,实现人群包的同步。
- 数据映射:确保DMP中的人群信息可以正确映射到本系统的人群定义中。
通过提供多样化且强大的人群创建方式,技术团队可以确保系统能够满足不同用户的需求,同时保持系统的灵活性和可扩展性,为业务提供坚实的数据支持。
2.2.3 人群应用:
数据应用产品集成使用
标签系统与北极星埋点管理分析平台和AB实验平台做了深入的产品集成打通,可以形成一套完整的数据驱动解决方案,使业务能够在一个统一的平台上管理数据收集、分析和实验测试。这种整合可以减少数据孤岛,提高数据分析的效率和准确性。使用场景包括:
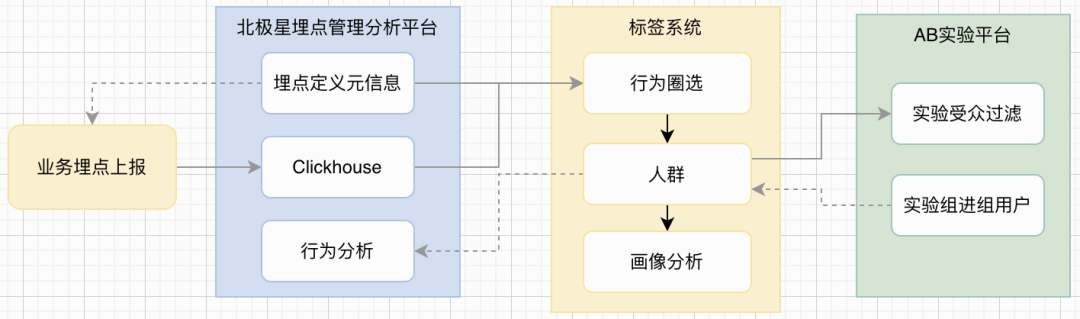
- 人群圈选:在AB实验中,企业可能需要根据特定的行为数据来选择目标受众,这可以通过北极星埋点管理分析平台来实现。
- 画像分析:实验组的用户数据可以进一步用于生成用户画像,这有助于更细致地了解用户特征和需求。
- 行为分析:对于参与实验的用户,可以进一步分析其行为模式,以评估实验效果或进行更深入的用户研究。
业务场景直接应用
当前系统在业务上主要有对接公司的推送平台、用增平台以及活动中台和任务平台,在分析上除了自身提供的画像分析能力之外,还有对接各类指标下钻分析系统。在推送触达场景中下游系统获取到人群数据明细后会进行批量推送,例如推送站内私信,推送特定业务卡片等,在业务运营场景中则更多的是使用标签系统在线服务判定能力。

- 个性化推荐:根据用户的标签,提供个性化的内容或产品推荐。
- 定向营销:使用标签来定向特定的营销活动,提高营销效率和转化率。
- 用户细分:通过标签对用户进行细分,以便更好地理解不同用户群体的需求和行为。
- 服务优化:利用标签系统来优化服务流程,提供更加个性化的服务体验。
整合这些系统和能力,可以为企业提供一个全面的解决方案,以支持从用户获取到用户运营的全过程。
03 核心方案
3.1 标签构建优化
3.1.1 引入Iceberg支持多存算引擎
在初版中,标签不区分类型,所有数据明细直接灌入Clickhouse,离线标签会通过物化视图生成 RoaringBitMap。这种方式可能导致在获取人群数据明细时产生大查询,影响 Clickhouse 的稳定性,甚至导致节点因内存溢出(OOM)而宕机。Apache Iceberg 可用于大规模分析数据集,它支持多种计算引擎,如 Apache Spark、Presto 等。Iceberg 的设计允许高效地读写大型数据集,并且可以与现有的数据湖生态系统无缝集成。通过支持多种计算引擎,Iceberg 允许业务根据自己的需求和现有的技术栈选择合适的处理工具,提高了灵活性和扩展性。
通过引入 Iceberg,标签的明细数据和连续标签直接存储在 Iceberg 中。Clickhouse 仅存储离散标签的 Bitmap 数据,这样可以减少 Clickhouse 的计算压力,提高查询效率和稳定性。由于Iceberg是数据湖技术,数据不再额外出仓,而是直接在 Iceberg 中处理,这样可以节约存储资源,降低成本。
3.1.2 自定义分shard模式读写Clickhouse
分shard写入和读取标签数据和人群数据的方法是一种有效的分布式数据处理策略,通过降低单节点的数据查询量,避免因单节点负载过高而引入的不稳定问题,同时也可以提升查询效率,通过并行处理来加速数据的写入和查询。
分shard的优势:
- 负载均衡:通过分shard,数据和查询负载被均匀地分配到多个节点上,避免了单点过载。
- 并行处理:利用并发数m,可以同时进行多个Spark任务,提高数据处理速度。
- 查询优化:查询时可以直接针对特定的shard进行,减少了跨节点的数据访问,提高了查询效率。
分shard构建过程如下图所示,首先会读取某标签对应列数据按行遍历,根据用户id和spark任务数(n*m)哈希得到n*m份数据,其中n是Clickhouse shard数,m可根据数据量级设定一个并发数,得到n*m份数据后,spark任务会根据任务id和shard数哈希确定要写入的shard,然后把数据以bitmap的结构直接写入shard本地表:
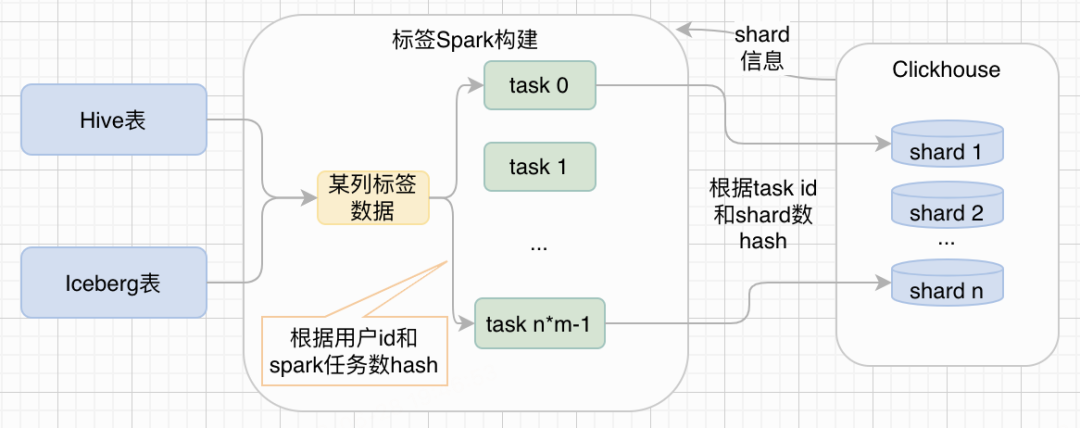
假设Clickhouse有5个shard,设定并发度m为2,那么spark分区任务数为10,数据分shard写入的示意图如下图所示:
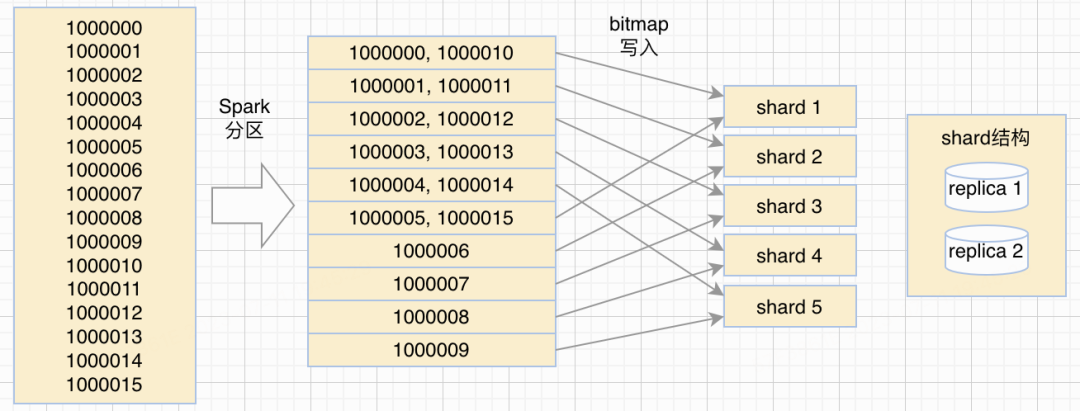
根据用户id分shard写入,可以保障同一个id只出现在同一个shard上,从而可以通过以下技巧提升计算和查询性能:
- 交并差计算时使用本地表:各节点完成本地表计算并把结果再写入本地表即完成计算,不需要额外聚合计算
- 分布式表读取时设置参数distributed_group_by_no_merge=1:本地表做完聚合后,不用在分布式表中再聚合所有数据
改造之后使后续的人群计算成功率从原来的85%提升至99.9%,相同数据量级计算速度提升50%。
3.2 人群交并差计算
在初版中,人群计算采用实时串型计算方式,这种方式在人群创建数量较少时可能表现良好。但随着人群创建频率的增加,底层引擎的瞬时压力增大,导致资源利用率低,系统稳定性难以保证。新版人群计算流程通过引入任务拆解和任务队列来提高系统效率和稳定性,通过任务拆解,将人群计算过程分解为多个小任务,这些任务可以根据数据来源类型和最终的数据存储类型生成人群圈选的任务DAG(有向无环图)。任务DAG提交到任务队列中,这样可以更灵活地管理和调度任务。DAG调度引擎根据任务类型,将任务分发到相应的计算或存储引擎进行处理。这种方式可以优化资源分配,提高计算效率,同时降低单个计算节点的负载。
人群计算流程如下图所示:
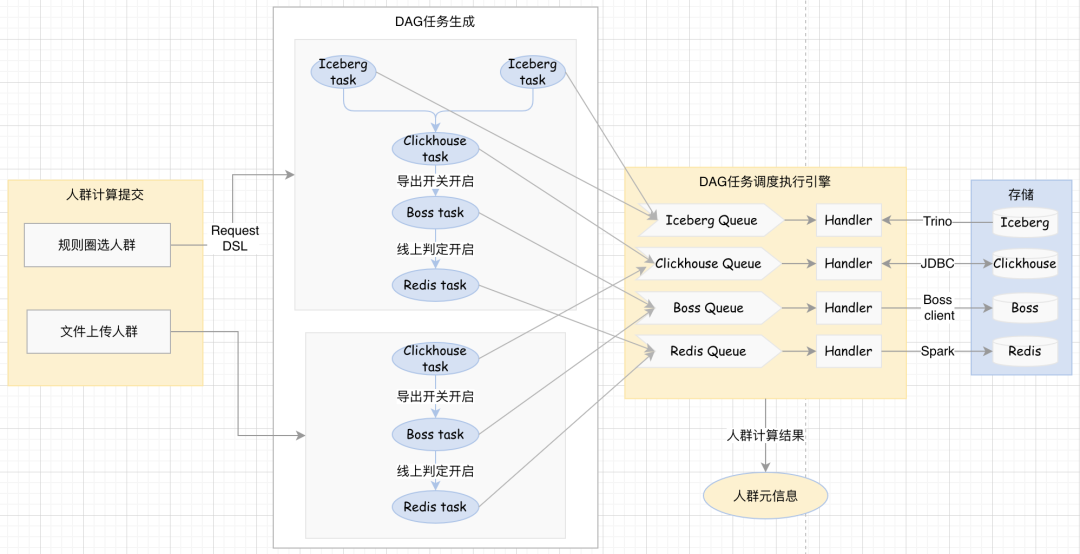
规则圈选人群支持用户选择标签和人群做多层级交集、并集和差集计算最终生成目标人群。用户选择好规则组合后,系统会根据规则描述DSL生成请求内容,传递给系统后端,后端根据描述DSL按最优的方式对规则进行合并优化,最终生成最少任务节点的DAG图,并依次把任务节点提交到对应的任务队列中。
连续标签将通过Trino直接查询Iceberg,所以对于连续标签规则将会生成Iceberg任务节点,任务输入为Iceberg sql,输出将为bitmap并写入Clickhouse,并且这个过程中会把多个sql子句按模型表维度整合为一条sql从而减少查询次数和流程复杂度。Iceberg得到的bitmap与离散标签和人群bitmap的交并差计算将组合成下游Clickhouse任务sql,Clickhouse任务计算得到目标人群bitmap。另外根据用户的选择任务链路将会附加上数据导出的Boss任务和离线构建写redis的任务。
DSL支持操作运算符如下表所示:
适用标签 | function | 运算关系 | params |
|---|---|---|---|
连续标签数值型 | LESS | < | 一个参数 |
MOST | <= | 一个参数 | |
GREATER | 一个参数 | ||
LEAST |
| 一个参数 | |
BETWEEN | between a,b | 两个参数 | |
所有连续标签 | NOTEQUAL | != | 一个参数 |
EQUAL | = | 一个参数 | |
IN | in(x1,x2,x3) | 多个参数 | |
ISNULL | is null | null | |
NOTNULL | is not null | null | |
连续标签字符串类型 | LIKE | 支持多值like | 多个参数 |
离散标签 | IN | in(x1,x2,x3) | 多个参数 |
人群 | EQUAL | = | 一个参数 |
圈选场景DSL描述和sql生成:

改造之后人群圈选平均耗时为30s左右,效率提升120%。
3.3 在线服务
标签在线服务作为C端业务中的关键组件,承担着实时判定用户是否属于特定人群的任务,并根据判定结果引导不同的业务逻辑。标签在线服务为独立的微服务承接所有的判定请求,因为该微服务直接对接线上业务流量所以需要满足线上服务SLA标准,主要体现在三个方面:
1.安全性:
- 确保高并发环境下的系统可用性,避免单点故障影响整体服务。
- 实现精确的人群权限控制,确保业务只能访问其授权的人群数据。
2.水平扩展性:
- 无状态计算:各计算节点独立运行,不共享状态,简化了扩展和管理。
- 业务存储相互隔离:允许在需要时独立扩展各个部分,而不会影响其他部分。
3.全生命周期功能覆盖:
- 服务需要覆盖人群数据的整个生命周期,包括生成、验证、配置、上线和下线。
- 在保证安全性和可扩展性的同时,满足用户在人群数据生命周期中的各种需求。
在线服务整体功能架构如下图所示:
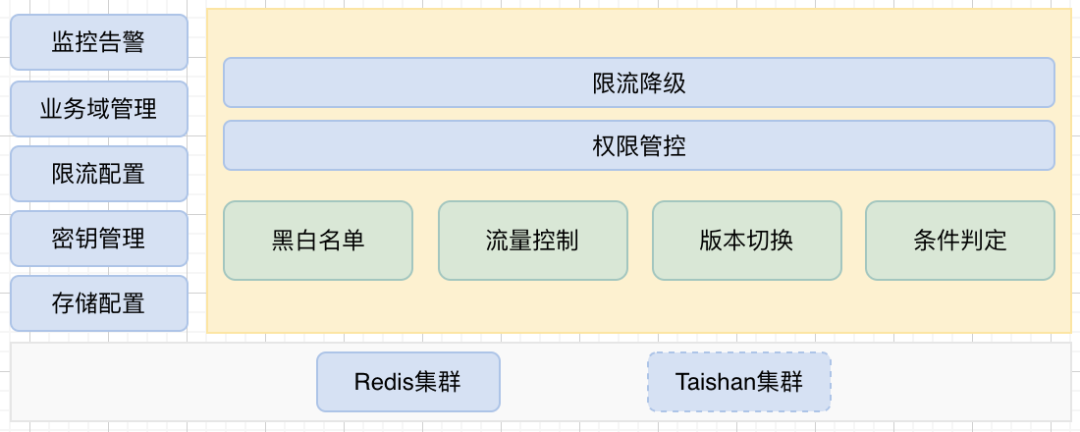
人群版本管理
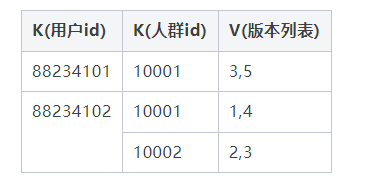
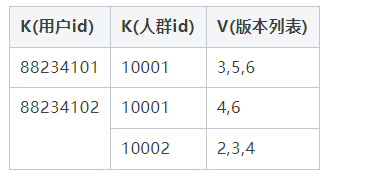
离线构建任务通过人群元信息确定人群数据要写入的存储集群和版本,每个人群最多保留5个版本,所以构建时版本信息包括要保留的最近4个版本ID和将要写入的下个版本ID,例如当前有两个人群10001和10002,人群10001有用户数据88234101、88234102,此次构建的版本ID是6,人群10002有用户数据88234102,此次构建的版本ID是4:
人群id | 引擎配置 | 版本设置 |
|---|---|---|
10001 | { "engine_type": "redis", "address": "10.10.10.10:6379,10.10.10.10:6378,10.10.10.11:6378,10.10.10.10:6379"} | { "next_version": "6", "current_version": "2,3,4,5"} |
10002 | { "engine_type": "taishan", "address": "12.10.10.10:7788,12.10.10.11:7789,12.10.10.10:7788,12.10.10.11:7789"} | { "next_version": "4", "current_version": "2,3"} |
Redis采用KKV结构进行存储,第一个K为用户id,第二个K为人群id,V存储版本信息。采用KKV方式存储主要用于解决正查场景,即通过用户id查询所有人群包,通过这种结构对于同时判定多个人群的场景下只需与Redis交互一次即可。
图片
数据更新时,Spark任务首先获取对应用户id的数据,然后进行版本覆盖。业务层能保证同一个时刻,同一个人群包只会有一个计算实例运行,防止出现ABA覆盖问题。版本更新逻辑是 V & current_version U next_version。通过版本合并更新,可防止人群例行化,V无限增长,通过上面更新后存储数据会更新为:
图片
另外由于Redis不支持在第二个K上设置过期时间,我们采用了一套类似Redis清理过期Key的方式,渐进式的删除过期人群数据。实现方案是随机从集群中获取一个Key,判定对应人群是否过期,过期则进行删除,对应当前人群用户量级控制1w tps,可以在20小时内收敛到90%。
流量控制
人群灰度是人群应用于线上服务时保障稳定性的一种方式。例如,需要对某个人群包开放某个新功能,但是在正式上线前,我们不确定这个圈人策略是否合理,或不确定圈选的sql逻辑是否万无一失,如果一次性应用于整个人群,万一有问题,所有用户都会受到影响,所以需要灰度放量来将风险降到最低,即先对这个人群包中一定比例的用户上线该功能,观察数据指标表现是否正常,逐步增加灰度百分比,直到放量比例达到100%。另外当人群包圈选策略需要调整但线上服务又不方便修改人群ID时,可在标签系统进行人群替换,替换过程中也可灵活进行流量控制。人群数据如果出现问题还支持快速回滚到某个版本。
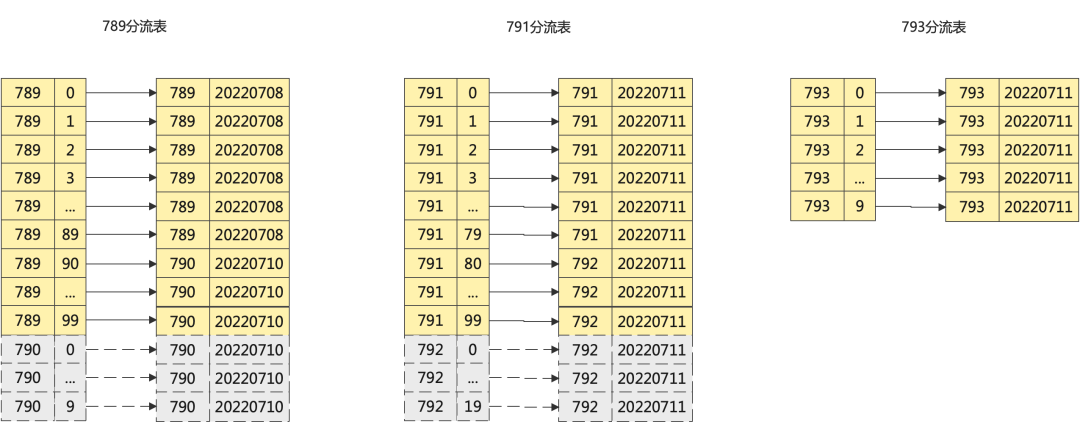
流量控制、人群替换、快速回滚都是基于流量表实现,在线服务检索端会周期加载人群元信息,然后生成分流配置表。比如下面人群元信息表示人群789、791分别被790和792替换,789放流90%,790放流10%,791放流80%,792放流20%,789最新版本是20220710但是回滚到了20220708版本,人群793放流10%。
人群id | 放流比例 | 最新版本 | 冻结版本 | 替换人群 |
|---|---|---|---|---|
789 | 90 | 20220710 | 20220708 | 790 |
790 | 10 | 20220710 | ||
791 | 80 | 20220711 | 792 | |
792 | 20 | 20220711 | ||
793 | 10 | 20220711 |
以上人群元信息生成的分流配置表如下,业务进行人群判定请求时只会请求789和791,不会请求替换人群。
条件判定
判定请求条件表达式采用antlr,支持多个人群进行交并差逻辑运算判定,antlr语法规则:
/*
Parser
*/
condition
: condition AND condition #logicalAnd
| condition OR condition #logicalOr
| LPAREN condition RPAREN #paren
| compare #logicalOp2
| variableDeclarator #commomOp
;
compare
: variableDeclarator op variableDeclarator #logicalOp
;
variableDeclarator
: TRUE #logicalTrue
| FALSE #logicalFalse
| INT #commonInt
| DOUBLE #commonDouble
| STRING #commonString
| IDENTIFIER #variable
;
/*
Lexer
*/
op : EQ | NE ;
EQ : '==';
NE : '!=';
OR : '||';
AND: '&&';
NOT: '!';
LPAREN: '(';
RPAREN: ')';
TRUE : 'true' ;
FALSE : 'false';
INT : [0-9]+; // 整数
DOUBLE : [1-9][0-9]*|[0]|([0-9]+[.][0-9]+);// 小数
STRING : '"' ('\\"'|.)*? '"' ; // 字符串
IDENTIFIER: Letter LetterOrDigit*;
fragment LetterOrDigit
: Letter
| [0-9]
;
fragment Letter
: [a-zA-Z$_]
;
WS : [ \r\n\t] + -> skip;例如:需要判定 命中人群1&&(不命中人群2||命中人群3),表达式:
condition = "tag_1 == 1 && (tag_2 == 0 || tag_3 == 1)"04 落地成果
在系统建设的落地过程中,取得了显著的成果,这些成果不仅体现在技术层面的稳定性和性能上,更在业务支持和应用场景的广泛性上得到了充分的体现。
技术稳定性与性能
得益于对算法和数据处理流程的不断优化,在人群圈选方面,成功率达到了99.9%,针对不同规模的数据集,圈选耗时如下:
- 千万级人群:离线标签,在Clickhouse数据库的支持下,圈选耗时小于10秒,这为需要快速响应的业务场景提供了强有力的支撑。
- 亿级人群:离线标签,同样利用Clickhouse数据库,圈选耗时在10秒至30秒之间,确保了大规模数据处理的高效率。
- 1~5千万人群:连续标签,在Iceberg的辅助下,圈选耗时在1分钟至2分钟之间,这为中等规模数据的处理提供了稳定而高效的解决方案。
在线服务的稳定性
对系统架构的重构和对服务流程的持续优化后,在线服务的稳定性达到了99.999%,响应耗时小于5毫秒。
业务场景的广泛支持
业务支持上具有较强的适应性和扩展性,打通了公司推送、活动、任务、风控等多个平台,支持了超过30+不同的业务场景。广泛的业务覆盖能力,能够满足多样化的业务需求,为不同领域的用户提供定制化的解决方案。
标签和人群规模的扩展性
在标签和人群规模方面,标签数量累计达到了3000+,人群生产规模累计达到了10w+。
05 未来规划
当前系统其实还有很多可以继续迭代优化的地方,针对当前未满足的业务需求和遗留的问题,后续将会从以下几个方面进行迭代优化:
实时标签和人群
- 实时数据处理:引入实时数据处理技术,如Apache Flink或Spark Streaming,以实现数据的实时流转和分析。
- 实时标签生成:开发实时标签生成机制,使业务能够即时获取并应用最新数据。
- 业务闭环:构建从数据决策到业务迭代再到数据回收的闭环链路,实现数据驱动的快速业务迭代。
标签基于指标灵活定义生成
- 指标模型复用:建立指标模型库,允许标签定义时复用已有的指标,减少重复开发。
- 动态标签生成:支持根据业务需求动态生成标签,无需预先聚合或分段数据。
- 自动化流程:开发自动化工具,简化标签定义和生成流程,提高效率。
应用效果回收
- 效果监测:建立监测机制,跟踪人群应用后的效果,为业务提供反馈。
- 数据链路打通:打通人群应用和业务效果数据生产链路,实现数据的无缝流转。
- 生命周期管理:根据业务使用情况优化人群标签的生命周期管理。
通过这些迭代优化方向,可以不断提升标签系统的能力,满足更多业务需求,提高数据驱动的业务效率和决策质量。同时,通过持续的技术创新和流程优化,确保标签系统的长期稳定发展。
-End-
作者丨vbarter、YuanMin、孟帅帅
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号