AIGC入门之生成对抗网络


1. GAN
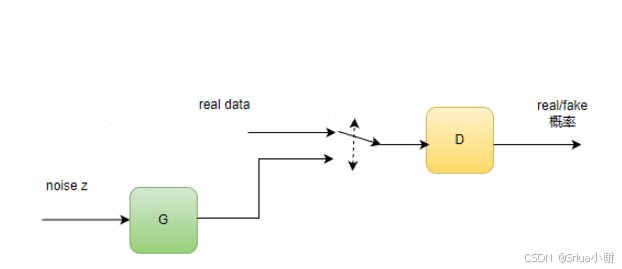
原始论文:https://arxiv.org/abs/1406.2661 放一张GAN的结构,如下:我们有两个网络,生成网络G和判别网络D。生成网络接收一个(符合简单分布如高斯分布或者均匀分布的)随机噪声输入,通过这个噪声输出图片,记做G(z)。判别网络的输入是x,x代表一张图片,输出D(x)代表x为真实图片的概率。最终的目的式能够生成一个以假乱真的图片,使D无法判别真假,D存在的意义是不断去督促G生成的质量
先拿出论文中的优化公式,后面在详解由来。
minGmaxDV(G,D)=Ex∼pdata(x)[logD(x)]+Ez∼pz(z)[log(1−D(G(z)))]GminDmaxV(G,D)=Ex∼pdata(x)[logD(x)]+Ez∼pz(z)[log(1−D(G(z)))]
这里pdata(x)pdata(x) 表示真实数据的分布,z是生成器G输入的噪声, pz(z)pz(z)是噪声的分布,乍一看这个公式是不是很难理解。没关系,接下来,我们慢慢分析由来。
2 GAN的优化函数
2.1 判别器D
我们先看判别器D,作用是能够对真实数据x∼ pdata(x)x∼ pdata(x)其能够准确分辨是真,对生成的假数据G(z)能够分辨是假,那么实际上这就是一个二分类的逻辑回归问题,还记得交叉熵吗?没错这也等价于交叉熵,只不过交叉熵是负对数,优化最小交叉熵必然等价于优化以下最大值:
maxDV(G,D)=Ex∼pdata(x)[logD(x)]+Ez∼pz(z)[log(1−D(G(z)))]DmaxV(G,D)=Ex∼pdata(x)[logD(x)]+Ez∼pz(z)[log(1−D(G(z)))]
看过我前面写的熵的问题,公式由来很容易懂。我们现在单独从公式来看,这个函数要想取得最大值,必然当真实数据来的时候D(x)=1,当假数据G(z)来的时候D(x)=0。这也满足我们的初衷:能够分辨真假。实际上是一个二分类。 这一步目标是优化D,G是固定的不做优化,G为上一次迭代优化后的结果,因此可简写成:
DG∗=maxDV(G,D)DG∗=DmaxV(G,D)
2.2 生成器G
在来看看生成器,对于生成器来说,我不想判别器D能够识别我是真假,我希望判别器识别不出来最好,理想极端情况下:D(x)=0,D(G(z))=1,也就是真的识别成假,假的识别成真。反应在优化函数上就是,是不是很好理解了
minG=Ex∼pdata(x)[logD(x)]+Ez∼pz(z)[log(1−D(G(z)))]Gmin=Ex∼pdata(x)[logD(x)]+Ez∼pz(z)[log(1−D(G(z)))]
当理想情况下D(x)=0,D(G(z))=1,必然是最小值优化。 同样这一步优化是优化G,D不做优化,D为上一次迭代优化后的结果,因此可简写成:
GD∗=minGV(G,D)GD∗=GminV(G,D)
2.3 互相博弈
作者习惯上把分开的两个优化写道一起,就变成了我们最初看到的论文中的公式:
minGmaxDV(G,D)=Ex∼pdata(x)[logD(x)]+Ez∼pz(z)[log(1−D(G(z)))]GminDmaxV(G,D)=Ex∼pdata(x)[logD(x)]+Ez∼pz(z)[log(1−D(G(z)))]
但是实际上,D和G在迭代过程中是分开优化的。 上面说了,我生成器又要能够准确判断真假,又要不能够判断,作为判别器他说他好难啊,怎么办呢,干脆判别器最终输出0.5,这也是理想优化结果,谁也不偏向。这也是整个GAN优化的终极目的。
3 训练过程

对于判别器D优化,因为这是个二分类,ylogq + (1-y)log(1-q):对于x,标签只会为1,因此只有log(D(x))这一项;对于g(z),其标签只会为0,因此只有log(1-D(G(z)))这一项,在损失函数上,
对于生成器G优化:因为D(x)这一项,并不包含生成器的优化参数,因此在求梯度的时候D(x)这一项为0,因此只有log(1-D(G(z)))这一项,损失函数:
4 在看优化
4.1 D的最优解
还记得完美的优化结果是D=0.5吗?这到底是怎么来的呢。我们先看一下对于D的优化,去求D的最优解
maxDV(G,D)=Ex∼pdata(x)[logD(x)]+Ez∼pz(z)[log(1−D(G(z)))]DmaxV(G,D)=Ex∼pdata(x)[logD(x)]+Ez∼pz(z)[log(1−D(G(z)))]
写成积分形式:不知道怎么来的可以补一下概率论均值的计算。
maxDV(G,D)=∫xpdata(x)logD(x)dx+∫xpz(z)log(1−D(g(z)))dzDmaxV(G,D)=∫xpdata(x)logD(x)dx+∫xpz(z)log(1−D(g(z)))dz
我们考虑在优化D的时候G是不变的,并且假设,通过G生成的g(z)满足的分布为pgpg,因此上式子可写为:
maxDV(G,D)=∫xpdata(x)logD(x)+pg(x)log(1−D(x)dxDmaxV(G,D)=∫xpdata(x)logD(x)+pg(x)log(1−D(x)dx
上式什么时候取得最大结果呢,alog(y)+blog(1−y)alog(y)+blog(1−y)在[0,1]上最大值是y=a/(a+b),因此上式最大值是
DG∗(x)=pdata(x)pdata(x)+pg(x)DG∗(x)=pdata(x)+pg(x)pdata(x)
以上我们得到D的最优解,但是别忘了,我们目标是G能够生成的分布pg能和pdata一致,让D真假难辨,那么此时pg = pdata,D=0.5,判别器已经模棱两可了。然而这一结果只是我们的猜测。
4.2 G的最优解
作者也是先说了pg=pdata是G的最优解,后面才证明的。让我们跟着作者思路证明一下。 D的最优解已经得到了,带入求解G最优的公式,这里作者起了个C(G)的名称,按照他的思路来,已然求C(G)的最小值
C(G)=Ex∼pdata(x)[logDG∗(x)]+Ez∼pz(z)[log(1−DG∗(G(z)))]=Ex∼pdata(x)[logDG∗(x)]+Ex∼pg[log(1−DG∗(x))]=Ex∼pdata(x)[logpdata(x)pdata(x)+pg(x)]+Ex∼pg[log(pg(x)pdata(x)+pg(x))]=∫xpdata(x)logpdata(x)pdata(x)+pg(x)+pg(x)logpg(x)pdata(x)+pg(x)dx=∫x(log2−log2)pdata(x)+(log2−log2)pg(x)+pdata(x)logpdata(x)pdata(x)+pg(x)+pg(x)logpg(x)pdata(x)+pg(x)dx=−log2∫x[pdata(x)+pg(x)]dx+∫xpdata(x)(log2+logpdata(x)pdata(x)+pg(x))+pg(x)(log2+logpg(x)pdata(x)+pg(x))dxC(G)=Ex∼pdata(x)[logDG∗(x)]+Ez∼pz(z)[log(1−DG∗(G(z)))]=Ex∼pdata(x)[logDG∗(x)]+Ex∼pg[log(1−DG∗(x))]=Ex∼pdata(x)[logpdata(x)+pg(x)pdata(x)]+Ex∼pg[log(pdata(x)+pg(x)pg(x))]=∫xpdata(x)logpdata(x)+pg(x)pdata(x)+pg(x)logpdata(x)+pg(x)pg(x)dx=∫x(log2−log2)pdata(x)+(log2−log2)pg(x)+pdata(x)logpdata(x)+pg(x)pdata(x)+pg(x)logpdata(x)+pg(x)pg(x)dx=−log2∫x[pdata(x)+pg(x)]dx+∫xpdata(x)(log2+logpdata(x)+pg(x)pdata(x))+pg(x)(log2+logpdata(x)+pg(x)pg(x))dx
由于对概率积分结果为1,上式继续化简为:
C(G)=−2log2+∫xpdata(x)logpdata(x)[pdata(x)+pg(x)]/2+∫xpg(x)logpg(x)[pdata(x)+pg(x)]/2C(G)=−2log2+∫xpdata(x)log[pdata(x)+pg(x)]/2pdata(x)+∫xpg(x)log[pdata(x)+pg(x)]/2pg(x)
看过熵的应该知道后两项其实式散度的形式,写为散度的形式,
C(G)=−log4+KL(pdata(x)∣∣pdata(x)+pg(x)2)+KL(pg(x)∣∣pdata(x)+pg(x)2)C(G)=−log4+KL(pdata(x)∣∣2pdata(x)+pg(x))+KL(pg(x)∣∣2pdata(x)+pg(x))
在我写熵的那篇文章里已经详细介绍和推导过,KL(P||Q)散度取最小值0的时候P=Q,因此上式最小值的情况是: pdata(x)=pdata(x)+pg(x)2pdata(x)=2pdata(x)+pg(x) 和pg(x)=pdata(x)+pg(x)2pg(x)=2pdata(x)+pg(x)。这两个当且仅当pg(x)=pdata(x)pg(x)=pdata(x)时满足。 又因为JSD散度和KL散度有如下关系:
JSD(P∣∣Q)=12KL(P∣∣M)+12KL(Q∣∣M),M=12(P+Q)JSD(P∣∣Q)=21KL(P∣∣M)+21KL(Q∣∣M),M=21(P+Q)
因此继续简化:
C(G)=−log4+2JSD(pdata∣∣pg)C(G)=−log4+2JSD(pdata∣∣pg)
由于JSD的散度取值为(0,log2),当为0的时候pg=pdatapg=pdata,同样也证明了G最优解的情况是pg=pdatapg=pdata。至此也完成论文中的证明,不得不说GAN中的理论真的很强,这些理论对后面各种生成模型用处非常大。虽然GAN是历史的产物,但是他带来的价值却很高,如果想做AIGC,GAN必学习。
5. 主要代码结构
5.1 模型结构(以DCGAN为例)
"""
Discriminator and Generator implementation from DCGAN paper
"""
import torch
import torch.nn as nn
from torchinfo import summary
class Discriminator(nn.Module):
def __init__(self, channels_img, features_d):
super().__init__()
self.disc = nn.Sequential(
self._block(channels_img, features_d, kernel_size=4, stride=2, padding=1),
self._block(features_d, features_d * 2, 4, 2, 1),
self._block(features_d * 2, features_d * 4, 4, 2, 1),
self._block(features_d * 4, features_d * 8, 4, 2, 1),
nn.Conv2d(features_d * 8, 1, kernel_size=4, stride=2, padding=0),
nn.Sigmoid(),
)
def _block(self, in_channels, out_channels, kernel_size, stride, padding):
return nn.Sequential(
nn.Conv2d(
in_channels,
out_channels,
kernel_size,
stride,
padding,
bias=False
),
nn.LeakyReLU(0.2),
)
def forward(self, x):
return self.disc(x)
class Generator(nn.Module):
def __init__(self, channels_noise, channels_img, features_g):
super().__init__()
self.gen = nn.Sequential(
self._block(channels_noise, features_g * 16, 4, 1, 0),
self._block(features_g * 16, features_g * 8, 4, 2, 1),
self._block(features_g * 8, features_g * 4, 4, 2, 1),
self._block(features_g * 4, features_g * 2, 4, 2, 1),
nn.ConvTranspose2d(features_g * 2, channels_img, 4, 2, 1),
nn.Tanh(),
)
def _block(self, in_channels, out_channels, kernel_size, stride, padding):
return nn.Sequential(
nn.ConvTranspose2d(
in_channels,
out_channels,
kernel_size,
stride,
padding,
bias=False,
),
nn.ReLU(),
)
def forward(self, x):
return self.gen(x)
def initialize_weights(model):
## initilialize weight according to paper
for m in model.modules():
if isinstance(m, (nn.Conv2d, nn.ConvTranspose2d,)):
nn.init.normal_(m.weight.data, 0.0, 0.02)
def test():
N, in_channels, H, W = 8, 1, 64, 64
noise_dim = 100
x = torch.randn(N, in_channels, H, W)
disc = Discriminator(in_channels, 8)
initialize_weights(disc)
assert disc(x).shape == (N, 1, 1, 1), "Discriminator test failed"
gen = Generator(noise_dim, in_channels, 8)
initialize_weights(gen)
z = torch.randn(N, noise_dim, 1, 1)
assert gen(z).shape == (N, in_channels, H, W), "Generator test failed"
if __name__ == "__main__":
gnet = Generator(100, 1, 64)
dnet = Discriminator(1, 64)
summary(gnet, input_data=[torch.randn(10, 100, 1, 1)])
summary(dnet, input_data=[torch.randn(10, 1, 64, 64)])5.2 训练代码(以DCGAN为例)
训练数据集拿MNIST 为例。
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision.datasets import MNIST
from torch.utils.data import DataLoader
from dcgan import Generator, Discriminator, initialize_weights
import torchvision.transforms as transforms
import torchvision
import cv2
import numpy as np
device = "cuda" if torch.cuda.is_available() else "cpu"
LEARNING_RATE = 1e-4
BATCH_SIZE = 128
IMAGE_SIZE = 64
NUM_EPOCHS = 5
CHANNELS_IMG = 1
NOISE_DIM = 100
FEATURES_DISC = 64
FEATURES_GEN = 64
transforms = transforms.Compose(
[
transforms.Resize(IMAGE_SIZE),
transforms.ToTensor(),
transforms.Normalize(
[0.5 for _ in range(CHANNELS_IMG)], [0.5 for _ in range(CHANNELS_IMG)]
),
]
)
def train(NUM_EPOCHS):
# 数据load
dataset = MNIST(root='./data', train=True, download=True, transform=transforms)
dataloader = DataLoader(dataset, batch_size=BATCH_SIZE, shuffle=True)
gen = Generator(NOISE_DIM, CHANNELS_IMG, FEATURES_GEN).to(device)
disc = Discriminator(CHANNELS_IMG, FEATURES_DISC).to(device)
initialize_weights(gen)
initialize_weights(disc)
opt_gen = optim.Adam(gen.parameters(), lr=LEARNING_RATE, betas=(0.5, 0.999))
opt_disc = optim.Adam(disc.parameters(), lr=LEARNING_RATE, betas=(0.5, 0.999))
criterion = nn.BCELoss()
fixed_noise = torch.randn(32, NOISE_DIM, 1, 1).to(device)
gen.train()
disc.train()
for epoch in range(NUM_EPOCHS):
# 不需要目标的标签,无监督
for batch_id, (real, _) in enumerate(dataloader):
real = real.to(device)
noise = torch.randn(BATCH_SIZE, NOISE_DIM, 1, 1).to(device)
fake = gen(noise)
# Train Discriminator: max log(D(x)) + log(1 - D(G(z)))
disc_real = disc(real).reshape(-1)
loss_real = criterion(disc_real, torch.ones_like(disc_real))
# 训练判别器,生成器输出的值从计算图剥离出来
disc_fake = disc(fake.detach()).reshape(-1)
loss_fake = criterion(disc_fake, torch.zeros_like(disc_fake))
loss_disc = (loss_real + loss_fake) / 2
disc.zero_grad()
loss_disc.backward()
opt_disc.step()
# Train Generator: min log(1 - D(G(z))) <-> max log(D(G(z)),
output = disc(fake).reshape(-1)
loss_gen = criterion(output, torch.ones_like(output))
gen.zero_grad()
loss_gen.backward()
opt_gen.step()
if batch_id % 20 == 0:
print(
f'Epoch [{epoch}/{NUM_EPOCHS}] Batch {batch_id}/{len(dataloader)} Loss D: {loss_disc.item()}, loss G: {loss_gen.item()}')
# 推理生成结果
with torch.no_grad():
fake = gen(fixed_noise)
img_grid_real = torchvision.utils.make_grid(real[:32], normalize=True)
img_grid_fake = torchvision.utils.make_grid(fake[:32], normalize=True)
img_grid_combined = torch.cat((img_grid_real, img_grid_fake), dim=2)
img_grid_combined = img_grid_combined.permute(1, 2, 0).cpu().detach().numpy()
img_grid_combined = (img_grid_combined * 255).astype(np.uint8)
# 使用 cv2 显示图片
cv2.imshow('Combined Image', img_grid_combined)
cv2.waitKey(1)
cv2.imwrite(f"ckpt/tmp_dc.jpg", img_grid_combined)
# 防止生成器崩溃,重新初始话模型
if loss_gen.item() > 5:
gen = Generator(NOISE_DIM, CHANNELS_IMG, FEATURES_GEN).to(device)
disc = Discriminator(CHANNELS_IMG, FEATURES_DISC).to(device)
initialize_weights(gen)
initialize_weights(disc)
opt_gen = optim.Adam(gen.parameters(), lr=LEARNING_RATE, betas=(0.5, 0.999))
opt_disc = optim.Adam(disc.parameters(), lr=LEARNING_RATE, betas=(0.5, 0.999))
if (epoch + 1) % 10 == 0:
torch.save(gen.state_dict(), f"ckpt/dc_gen_weights.pth")
torch.save(disc.state_dict(), f"ckpt/dc_disc_weights.pth")
if __name__ == "__main__":
train(100)5.3 生成结果
左边为训练的样本,右边为随机生成的手写数字。


本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-12-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号