Java中Map使用详解


一、初识Map
1、初识Map
概述:
以键值对形式来保存数据 ---key ---value;
键(key)值(value)来保存数据,其中值(value)可以重复,但键(key)必须是唯一,相同就覆盖;
也可以为空,但最多只能有一个key为空;
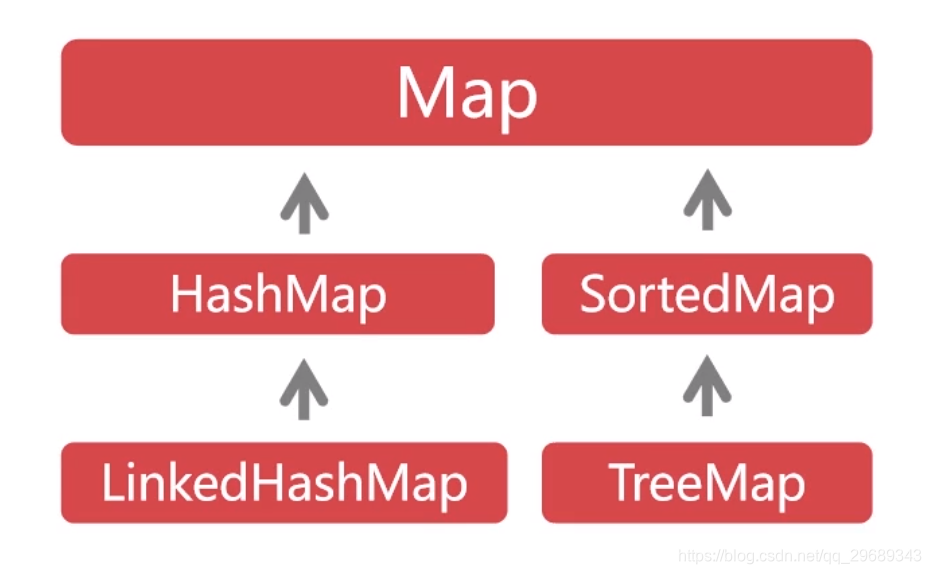
它的主要实现类有HashMap(去重)、LinkedHashMap、TreeMap(排序)。 指的都是对key 的操作;
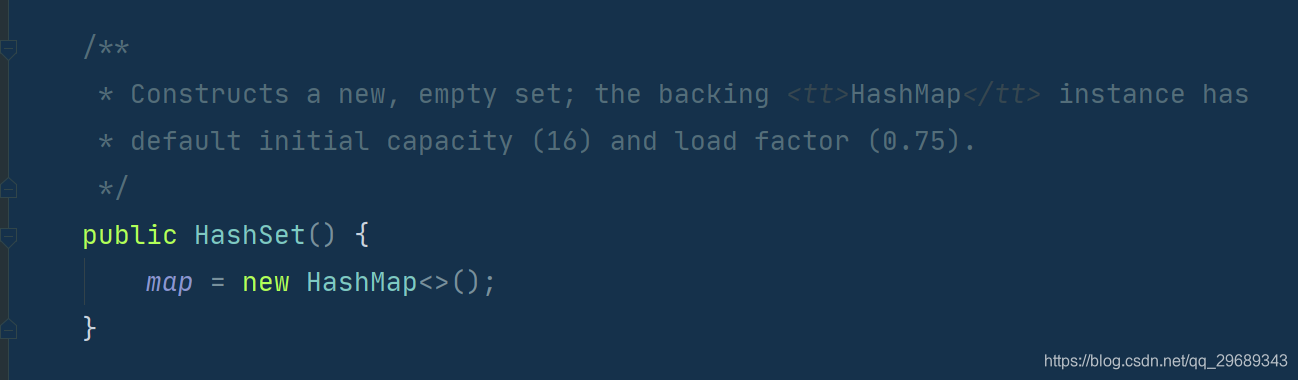
HashSet去重和HashMap的关系:
HashSet依赖Map 存储数据,set在保存数据时,实际上是在向Map中key这一列中存数据;
Map接口及其常用实现类:
2、Map通用方法
put(key,value):存入Map中的一个key-value键值对映射;
get(key):返回指定key所映射的值;
int size():返回键值对的数量;
remove(key):删除指定key的一对映射;
containsKey(key):判断是否包含指定的key;
二、HashMap的使用(无序)
1、HashMap基本用法
构造方法:
HashMap():无参构造,默认初始化长度为16,负载因子为0.75;
HashMap(int initalCapacity):指定初始化长度;
HashMap(int initalCapacity,float loadFactor):指定初始化长度和负载因子;
代码演示:
package com.zb.study.map;
import java.util.HashMap;
import java.util.Map;
//测试HashMap
public class TestHashMap {
public static void main(String[] args) {
//创建HashMap
Map<String,String> map = new HashMap<>();
//存放元素
map.put("齐天大圣","孙悟空");
//取出元素
String s = map.get("齐天大圣");
System.out.println(s);
//获取map长度
int size = map.size();
System.out.println(size);
//判断是否包含指定key
boolean b = map.containsKey("齐天大圣");
System.out.println(b);
}
}运行结果:
孙悟空
1
true2、HashMap的Entry结构

3、观察HashMap的顺序
代码演示:
package com.zb.study.map;
import java.util.HashMap;
import java.util.Map;
//测试HashMap
public class TestHashMap {
public static void main(String[] args) {
//创建HashMap
Map<String,Integer> map = new HashMap<>();
//存放元素
map.put("大哥",1);
map.put("二哥",2);
map.put("三哥",3);
map.put("四哥",4);
map.put("五哥",5);
//输出map
System.out.println(map);
}
}运行结果:
{二哥=2, 四哥=4, 大哥=1, 三哥=3, 五哥=5}发现:
HashMap输出后,我们发现:它不是按照值的顺序(12345)也不是按照put的顺序存放的,而是按照自己的算法进行排序的,见HashMap原理;
4、HashMap遍历-keySet
概述:
keySet是map集合中所有key的集合,我们可以通过遍历keySet的方法取出所有的value;
代码演示:
package com.zb.study.map;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
//测试HashMap
public class TestHashMap {
public static void main(String[] args) {
//创建HashMap
Map<String,Integer> map = new HashMap<>();
//存放元素
map.put("大哥",1);
map.put("二哥",2);
map.put("三哥",3);
map.put("四哥",4);
map.put("五哥",5);
//获取keySet,keySet是map集合中所有key的集合,我们可以通过遍历keySet的方法取出所有的value;
Set<String> keySet = map.keySet();
for (String key : keySet) {
System.out.println(map.get(key));
}
}
}运行结果:
2
4
1
3
55、HashMap遍历-values
概述:
values是map所有值的集合,可以直接通过遍历values并输出;
代码演示:
package com.zb.study.map;
import java.util.HashMap;
import java.util.Map;
//测试HashMap
public class TestHashMap {
public static void main(String[] args) {
//创建HashMap
Map<String,Integer> map = new HashMap<>();
//存放元素
map.put("大哥",1);
map.put("二哥",2);
map.put("三哥",3);
map.put("四哥",4);
map.put("五哥",5);
//获取values,values是map所有值的集合,可以直接通过遍历values并输出
for (Integer integer : map.values()) {
System.out.println(integer);
}
}
}运行结果:
2
4
1
3
56、HashMap遍历-entrySet
概述:
entrySet是所有entry的集合,可以通过遍历entrySet的方式获取key和value并输出;
代码演示:
package com.zb.study.map;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
//测试HashMap
public class TestHashMap {
public static void main(String[] args) {
//创建HashMap
Map<String,Integer> map = new HashMap<>();
//存放元素
map.put("大哥",1);
map.put("二哥",2);
map.put("三哥",3);
map.put("四哥",4);
map.put("五哥",5);
//获取entrySet,entrySet是所有entry的集合,可以通过遍历entrySet的方式获取key和value并输出
Set<Map.Entry<String, Integer>> entrySet = map.entrySet();
for (Map.Entry<String, Integer> entry : entrySet) {
System.out.println(entry.getKey() + "==>" + entry.getValue());
}
}
}运行结果:
二哥==>2
四哥==>4
大哥==>1
三哥==>3
五哥==>56、HashMap遍历-Iterator
概述:
iterator是一个迭代器,iterator.hasNext()用来判断是否还存在下一个entry,iterator.next()用来获取下一个entry;
代码演示:
package com.zb.study.map;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
//测试HashMap
public class TestHashMap {
public static void main(String[] args) {
//创建HashMap
Map<String,Integer> map = new HashMap<>();
//存放元素
map.put("大哥",1);
map.put("二哥",2);
map.put("三哥",3);
map.put("四哥",4);
map.put("五哥",5);
//获取iterator,iterator是一个迭代器,iterator.hasNext()用来判断是否还存在下一个entry,iterator.next()用来获取下一个entry
Iterator<Map.Entry<String, Integer>> iterator = map.entrySet().iterator();
while (iterator.hasNext()){
Map.Entry<String, Integer> next = iterator.next();
System.out.println(next.getKey() + "==>" + next.getValue());
}
}
}运行结果:
二哥==>2
四哥==>4
大哥==>1
三哥==>3
五哥==>57、HashMap遍历-性能分析
我们组织了10万条数据,分别对集中遍历的方式进行了速度的测试,得出的结果从快到慢是顺序为:
iterator 11毫秒 (工作时次常用)—— values 11毫秒 —— entrySet 18毫秒(工作时最常用) —— keySet 33毫秒
补充:在上千万条数据进行遍历的时候,除了keySet时间较长,其他方式时间都极为接近;
三、HashMap的原理
1、需求场景描述
将五个学生的三门成绩使用Map存储起来;
2、代码实现
代码演示:
package com.zb.study.map;
import java.util.HashMap;
import java.util.Map;
//测试HashMap
public class TestHashMap {
public static void main(String[] args) {
//创建HashMap
Map<String,Integer> subMap1 = new HashMap<>();
Map<String,Map<String,Integer>> stuMap = new HashMap<>();
subMap1.put("chinese",90);
subMap1.put("math",96);
subMap1.put("english",98);
stuMap.put("s1",subMap1);
Map<String,Integer> subMap2 = new HashMap<>();
subMap2.put("chinese",91);
subMap2.put("math",94);
subMap2.put("english",95);
stuMap.put("s2",subMap2);
Map<String,Integer> subMap3 = new HashMap<>();
subMap3.put("chinese",96);
subMap3.put("math",95);
subMap3.put("english",94);
stuMap.put("s3",subMap3);
Map<String,Integer> subMap4 = new HashMap<>();
subMap4.put("chinese",91);
subMap4.put("math",97);
subMap4.put("english",96);
stuMap.put("s4",subMap4);
Map<String,Integer> subMap5 = new HashMap<>();
subMap5.put("chinese",93);
subMap5.put("math",96);
subMap5.put("english",99);
stuMap.put("s5",subMap5);
System.out.println(stuMap);
}
}运行结果:
(手动换行了)
{s3={chinese=96, english=94, math=95}, s4={chinese=91, english=96, math=97},
s5={chinese=93, english=99, math=96}, s1={chinese=90, english=98, math=96},
s2={chinese=91, english=95, math=94}}3、底层分析
思考:
将120、37、61、40、92、78作为key存放到map中的过程;
原理分析:
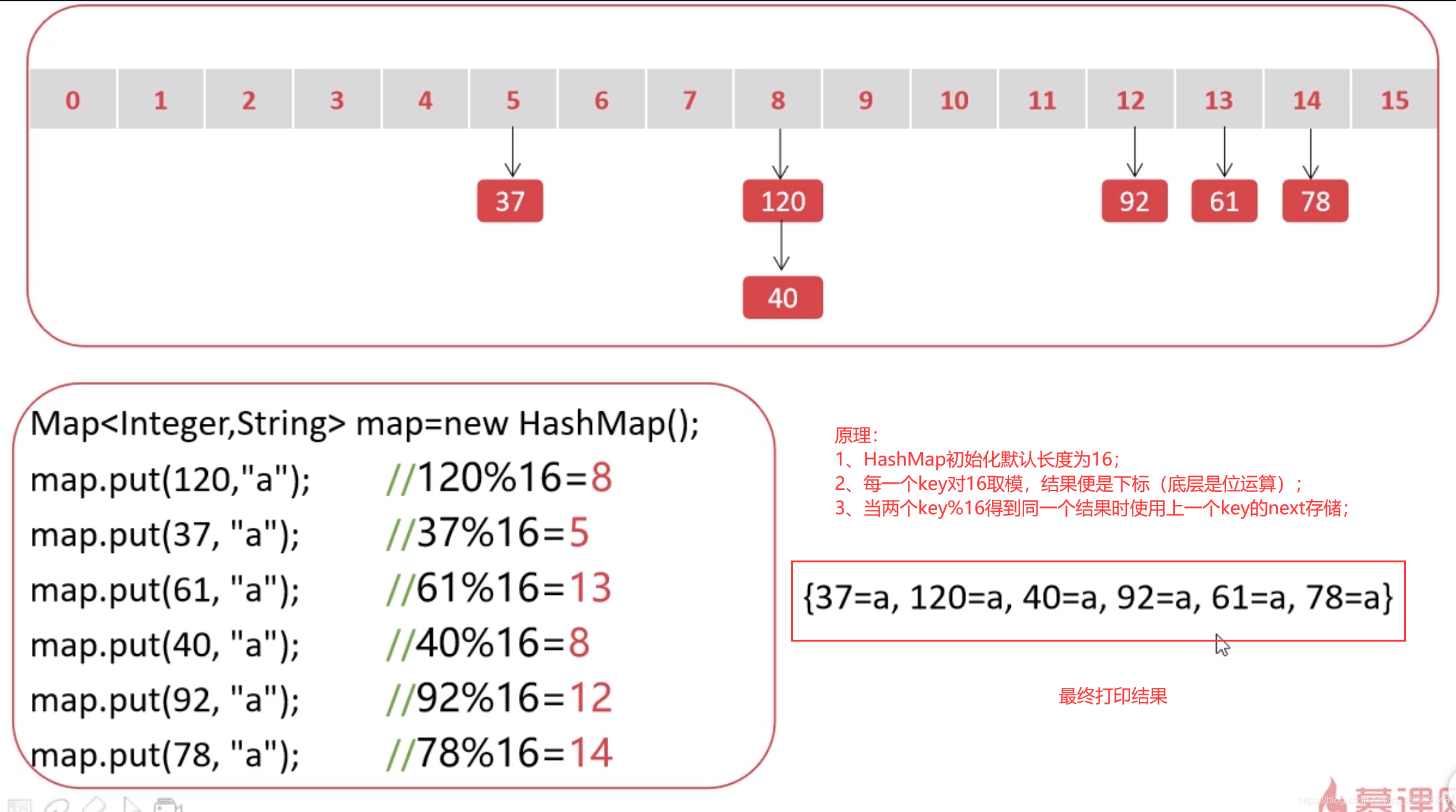
如何key是字符类型该怎么定位呢?
转成hash码 —— 优化hash码 —— 根据优化后的hash码和HashMap的长度定位;
final int hash(Object k):用hashCode()方法将key转换成hash码并进行优化得到优化后的hash码;
static int indexFor(int h,int length):对优化的hash码进行取址,确定在Hashmap的位置;
关于负载因子loadFactor:
默认负载因子是0.75,意思是当元素占满map75%的时候对HashMap进行扩容,扩容规则是2的倍数(2的n次方),默认长16第一次扩容后就是32了,扩容之后重新计算,按照新的位置进行重新排序;
4、HashMap构造方法优化
不带参的构造方法:
Map<String,Integer> map= new HashMap<>();默认长度:16
负载因子:0.75f
等价:
Map<String,Integer> map= new HashMap<>(16, 0.75f);带一个初始化大小的参数:
Map<String,Integer> map= new HashMap<>(3);传参为3,实际长度为4;
如果传参为5,实际长度为8;
因为其长度必须是2的倍数,传的参数为3意思是大于3的最小的2的n次方,也就是4,同理传参为5,长度也就是8了;
负载因子参数:
假如有两个元素经过计算位置都是8,那么只计算一次,当所有的位置被占用比例超过负载因子时进行扩容,扩容到下一个2的n次方的长度,根据新的长度重新计算位置,然后重新排序;
经过计算默认的0.75是最合理的,一般不轻易更改;
备注:
我们因情况下只自定义长度,但我们明确知道我们录入多少数据,我们就将默认长度设置为与其接近的数值,减少map的自动扩容,因为自动扩容需要重新选址很消耗性能;
5、性能测试结果
我们计划传入10万条数据,分别创建初始化长度为16和初始化长度为16384的两个map,负载因子使用默认的0.75,经测算我们发现:
初始化长度为16384的map由于不需要太多次扩容,其执行速度高于初始化长度为16的map;
6、HashMap常用方法(一)
方法概述:
判断是否为空、删除节点、清空HashMap对象、判断是否存在某个key、判断是否存在某个value、替换某个key的value,不存在则put;
代码演示:
package com.zb.study.map;
import java.util.HashMap;
import java.util.Map;
//测试HashMap
public class TestHashMap {
public static void main(String[] args) {
//创建HashMap
Map<String,Integer> map = new HashMap<>();
map.put("大哥",1);
map.put("二哥",2);
//判断是否为空
System.out.println("判断是否为空map.isEmpty():" + map.isEmpty());
//删除节点
map.remove("大哥");
map.remove("大哥",1);
//清空HashMap对象
map.clear();
// 判断是否存在某个key
System.out.println("判断是否存在某个key:" + map.containsKey("二哥"));
// 判断是否存在某个value
System.out.println("判断是否存在某个value:" + map.containsValue(1));
// 替换某个key的value
map.replace("大哥",999);//替换
map.replace("大哥",1,999);//替换
map.put("大哥",888);//覆盖
//不存在则put
map.putIfAbsent("大哥",222);
}
}7、HashMap常用方法(二)
方法概述:
map.foreach()、getOrDefault();
代码实现:
package com.zb.study.map;
import java.util.HashMap;
import java.util.Map;
//测试HashMap
public class TestHashMap {
public static void main(String[] args) {
//创建HashMap
Map<String,Integer> map = new HashMap<>();
map.put("大哥",1);
map.put("二哥",2);
//forEach遍历
map.forEach((key,value)-> System.out.println(key + "==>" + value));
//默认返回值
System.out.println(map.getOrDefault("三哥", 9999));
}
}运行结果:
二哥==>2
大哥==>1
9999四、LinkedHashMap(有序)
1、速度对比(100万条数据)
代码实现:
package com.zb.study.map;
import java.util.HashMap;
import java.util.LinkedHashMap;
import java.util.Map;
//测试LinkedHashMap
public class TestLinkedHashMap {
public static void main(String[] args) {
Map<String, String> hashMap = new HashMap<>();
Map<String, String> linkedHashMap = new LinkedHashMap<>();
long start = System.currentTimeMillis();
System.out.println("=======put时间=======");
System.out.println("开始时间:" + start);
for (int i = 0; i < 1000000; i++) {
hashMap.put(String.valueOf(i),"value");
}
long end = System.currentTimeMillis();
System.out.println("结束时间:" + end);
System.out.println("hashMap使用时间:" + (end-start));
start = System.currentTimeMillis();
System.out.println("开始时间:" + start);
for (int i = 0; i < 1000000; i++) {
linkedHashMap.put(String.valueOf(i),"value");
}
end = System.currentTimeMillis();
System.out.println("结束时间:" + end);
System.out.println("linkedHashMap使用时间:" + (end-start));
System.out.println("=======遍历时间=======");
start = System.currentTimeMillis();
System.out.println("开始时间:" + start);
for (String value : hashMap.values());
end = System.currentTimeMillis();
System.out.println("结束时间:" + end);
System.out.println("hashMap使用时间:" + (end-start));
start = System.currentTimeMillis();
System.out.println("开始时间:" + start);
for (String value : linkedHashMap.values());
end = System.currentTimeMillis();
System.out.println("结束时间:" + end);
System.out.println("hashMap使用时间:" + (end-start));
}
}运行结果:
=======put时间=======
开始时间:1606196463697
结束时间:1606196463880
hashMap使用时间:183
开始时间:1606196463880
结束时间:1606196464040
linkedHashMap使用时间:160
=======遍历时间=======
开始时间:1606196464040
结束时间:1606196464074
hashMap使用时间:34
开始时间:1606196464074
结束时间:1606196464093
hashMap使用时间:19结论:
LinkedHashMap比HashMap速度快;
2、速度对比(500万条数据)
运行结果:
=======put时间=======
开始时间:1606196769308
结束时间:1606196773364
hashMap使用时间:4056
开始时间:1606196773364
结束时间:1606196779231
linkedHashMap使用时间:5867
=======遍历时间=======
开始时间:1606196779232
结束时间:1606196779384
hashMap使用时间:152
开始时间:1606196779384
结束时间:1606196779464
hashMap使用时间:80结论:
存的速度:hashMap > linkedHashMap ;
遍历速度:linkedHashMap > hashMap ;
3、速度对比(1000万条)
与500万条结论一致;
4、LinkedHashMap特有方法
两种输出顺序:
1、录入顺序;2、使用顺序;
录入顺序:
代码实现:
package com.zb.study.map;
import java.util.LinkedHashMap;
import java.util.Map;
//测试LinkedHashMap
public class TestLinkedHashMap {
public static void main(String[] args) {
Map<String, String> map = new LinkedHashMap<>();
map.put("y1","xx");
map.put("m1","xx");
map.put("k1","xx");
map.put("n1","xx");
System.out.println(map.get("m1"));
//按照录入顺序输出
for (String key : map.keySet()) {
System.out.println(key + "==>" + map.get(key));
}
}
}运行结果:
xx
y1==>xx
m1==>xx
k1==>xx
n1==>xx使用顺序:
代码实现:
package com.zb.study.map;
import java.util.LinkedHashMap;
import java.util.Map;
//测试LinkedHashMap
public class TestLinkedHashMap {
public static void main(String[] args) {
Map<String, String> map = new LinkedHashMap<>(16,0.75f,true);
map.put("y1","xx");
map.put("m1","xx");
map.put("k1","xx");
map.put("n1","xx");
System.out.println(map);
System.out.println(map.get("m1"));
//按照录入顺序输出
System.out.println(map);
}
}运行结果(实现和上面一样的方法会报错):
{y1=xx, m1=xx, k1=xx, n1=xx}
xx
{y1=xx, k1=xx, n1=xx, m1=xx}利用LinkedHashMap实现LRU缓存:
自定义LRUMap类:
package com.zb.study.map;
import java.util.LinkedHashMap;
import java.util.Map;
public class LRUMap<K,V> extends LinkedHashMap<K,V> {
private final int maxSize;
public LRUMap(int maxSize) {
super(16,0.75f,true);
this.maxSize = maxSize;
}
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return size() > this.maxSize;
}
}测试代码:
package com.zb.study.map;
import java.util.Map;
//测试LinkedHashMap
public class TestLinkedHashMap {
public static void main(String[] args) {
//长度为3,只保留最新“活跃”的3个
Map<String, String> lruMap = new LRUMap<>(3);
lruMap.put("大哥","value");
lruMap.put("二哥","value");
lruMap.put("三哥","value");
System.out.println(lruMap.get("大哥"));
lruMap.put("四哥","value");
lruMap.put("五哥","value");
System.out.println(lruMap);
}
}运行结果:
value
{大哥=value, 四哥=value, 五哥=value}五、TreeMap(有序)
1、TreeMap实现升序
代码实现:
package com.zb.study.map;
import java.util.Map;
import java.util.TreeMap;
public class TestTreeMap {
public static void main(String[] args) {
Map<String, String> map = new TreeMap<>();
map.put("c","a3");
map.put("e","a5");
map.put("b","a2");
map.put("a","a1");
map.put("d","a4");
//默认升序
System.out.println(map);
}
}运行结果:
{a=a1, b=a2, c=a3, d=a4, e=a5}2、TreeMap实现降序
代码实现:
package com.zb.study.map;
import java.util.Comparator;
import java.util.Map;
import java.util.TreeMap;
public class TestTreeMap {
public static void main(String[] args) {
//Map<String, String> map = new TreeMap<>(String::compareTo);//这里用了lambda表达式
//完整表达式
Map<String, String> map = new TreeMap<>(new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return o2.compareTo(o1);
}
});
map.put("c","a3");
map.put("e","a5");
map.put("b","a2");
map.put("a","a1");
map.put("d","a4");
//降序
System.out.println(map);
}
}运行结果:
{e=a5, d=a4, c=a3, b=a2, a=a1}3、TreeMap速度测试
代码实现:
package com.zb.study.map;
import java.util.HashMap;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.TreeMap;
//测试LinkedHashMap
public class TestLinkedHashMap {
public static void main(String[] args) {
Map<String, String> hashMap = new HashMap<>();
Map<String, String> linkedHashMap = new LinkedHashMap<>();
Map<String, String> treeMap = new TreeMap<>();
long start = System.currentTimeMillis();
System.out.println("=======put时间=======");
System.out.println("开始时间:" + start);
for (int i = 0; i < 1000000; i++) {
hashMap.put(String.valueOf(i),"value");
}
long end = System.currentTimeMillis();
System.out.println("结束时间:" + end);
System.out.println("hashMap使用时间:" + (end-start));
start = System.currentTimeMillis();
System.out.println("开始时间:" + start);
for (int i = 0; i < 1000000; i++) {
linkedHashMap.put(String.valueOf(i),"value");
}
end = System.currentTimeMillis();
System.out.println("结束时间:" + end);
System.out.println("linkedHashMap使用时间:" + (end-start));
start = System.currentTimeMillis();
System.out.println("开始时间:" + start);
for (int i = 0; i < 1000000; i++) {
treeMap.put(String.valueOf(i),"value");
}
end = System.currentTimeMillis();
System.out.println("结束时间:" + end);
System.out.println("treeMap使用时间:" + (end-start));
System.out.println("=======遍历时间=======");
start = System.currentTimeMillis();
System.out.println("开始时间:" + start);
for (String value : hashMap.values());
end = System.currentTimeMillis();
System.out.println("结束时间:" + end);
System.out.println("hashMap使用时间:" + (end-start));
start = System.currentTimeMillis();
System.out.println("开始时间:" + start);
for (String value : linkedHashMap.values());
end = System.currentTimeMillis();
System.out.println("结束时间:" + end);
System.out.println("hashMap使用时间:" + (end-start));
start = System.currentTimeMillis();
System.out.println("开始时间:" + start);
for (String value : treeMap.values());
end = System.currentTimeMillis();
System.out.println("结束时间:" + end);
System.out.println("treeMap使用时间:" + (end-start));
}
}运行结果:
=======put时间=======
开始时间:1606201339487
结束时间:1606201339664
hashMap使用时间:177
开始时间:1606201339664
结束时间:1606201339827
linkedHashMap使用时间:163
开始时间:1606201339827
结束时间:1606201341737
treeMap使用时间:1910
=======遍历时间=======
开始时间:1606201341737
结束时间:1606201341774
hashMap使用时间:37
开始时间:1606201341774
结束时间:1606201341797
hashMap使用时间:23
开始时间:1606201341797
结束时间:1606201341832
treeMap使用时间:35结论:
treeMap存放数据比较耗时,遍历与hashMap和linkedHashMap差不多;
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-01-06,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号