玩转 OCR|智能Excel数据分析助手
原创
玩转 OCR|智能Excel数据分析助手
原创
刺头
修改于 2025-01-12 15:08:57
修改于 2025-01-12 15:08:57
项目背景
在当今数字化时代,大量的业务数据仍以Excel表格和纸质文档的形式存在。如何高效地将这些数据转化为可分析的数字资产,是很多企业和个人面临的挑战。
解决方式
本项目旨在构建一个智能化的Excel数据分析助手,通过结合OCR技术和自然语言处理,实现从图片到数据分析的端到端解决方案。
通过腾讯云的OCR技术,将图片中的数据转化为可分析的数字资产。在加上混元大模型的自然语言的解析能力与DuckDB 的高性能查询能力相结合,实现了自动化字段解析、数据类型推断与高效数据入库等功能。无论是对复杂数据的快速处理,还是多源数据的灵活支持,系统均能高效响应,满足用户对实时性和准确性的需求。
同时,项目提供了轻量化的分析引擎,在处理数据的同时保持资源占用的低门槛,让用户无需掌握复杂的技术知识即可完成高质量的数据分析。
主要功能
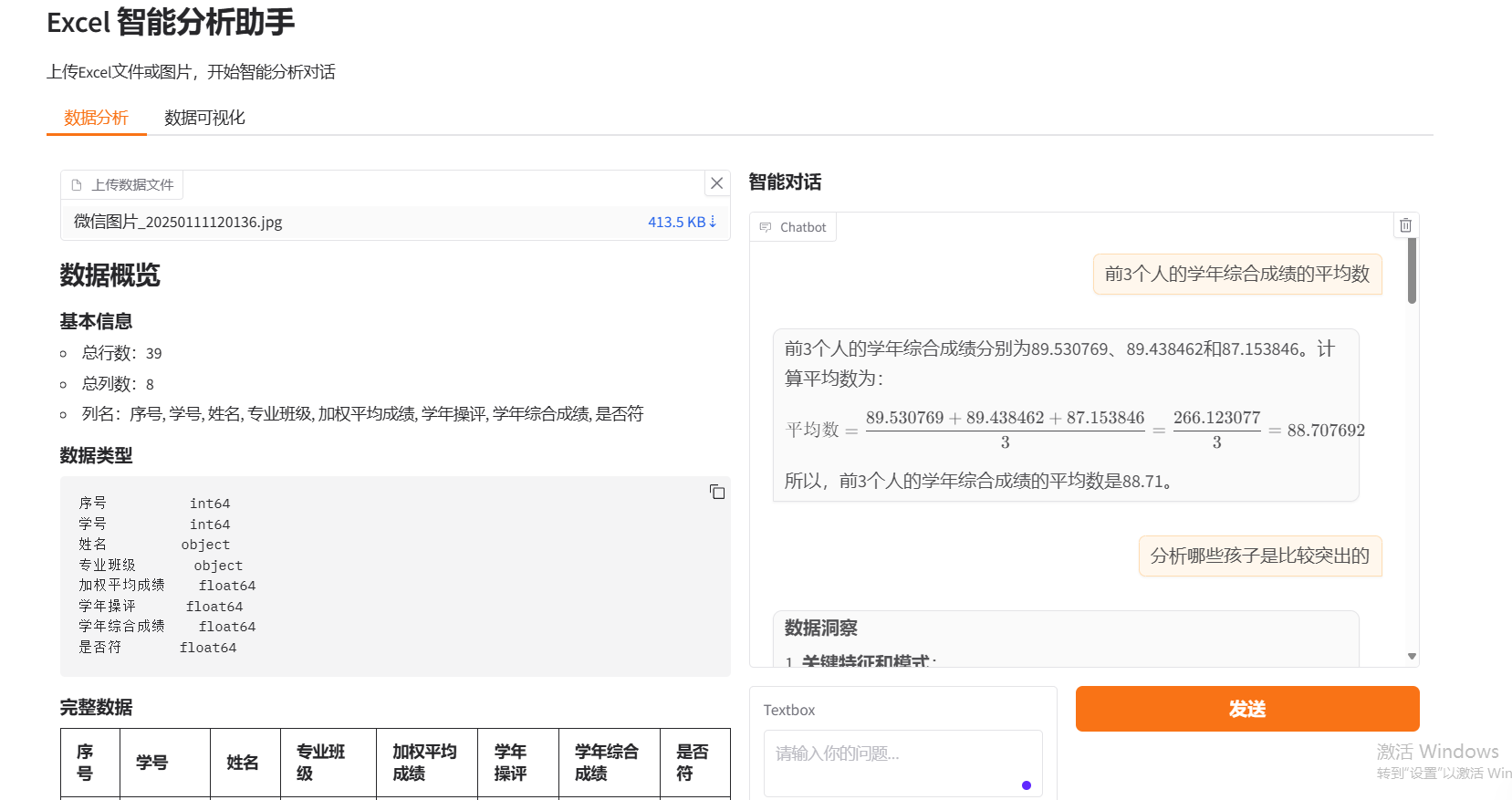
1. 数据输入模块
- Excel文件直接读取
- 图片OCR表格识别
- 数据预处理和清洗
2. 分析引擎模块
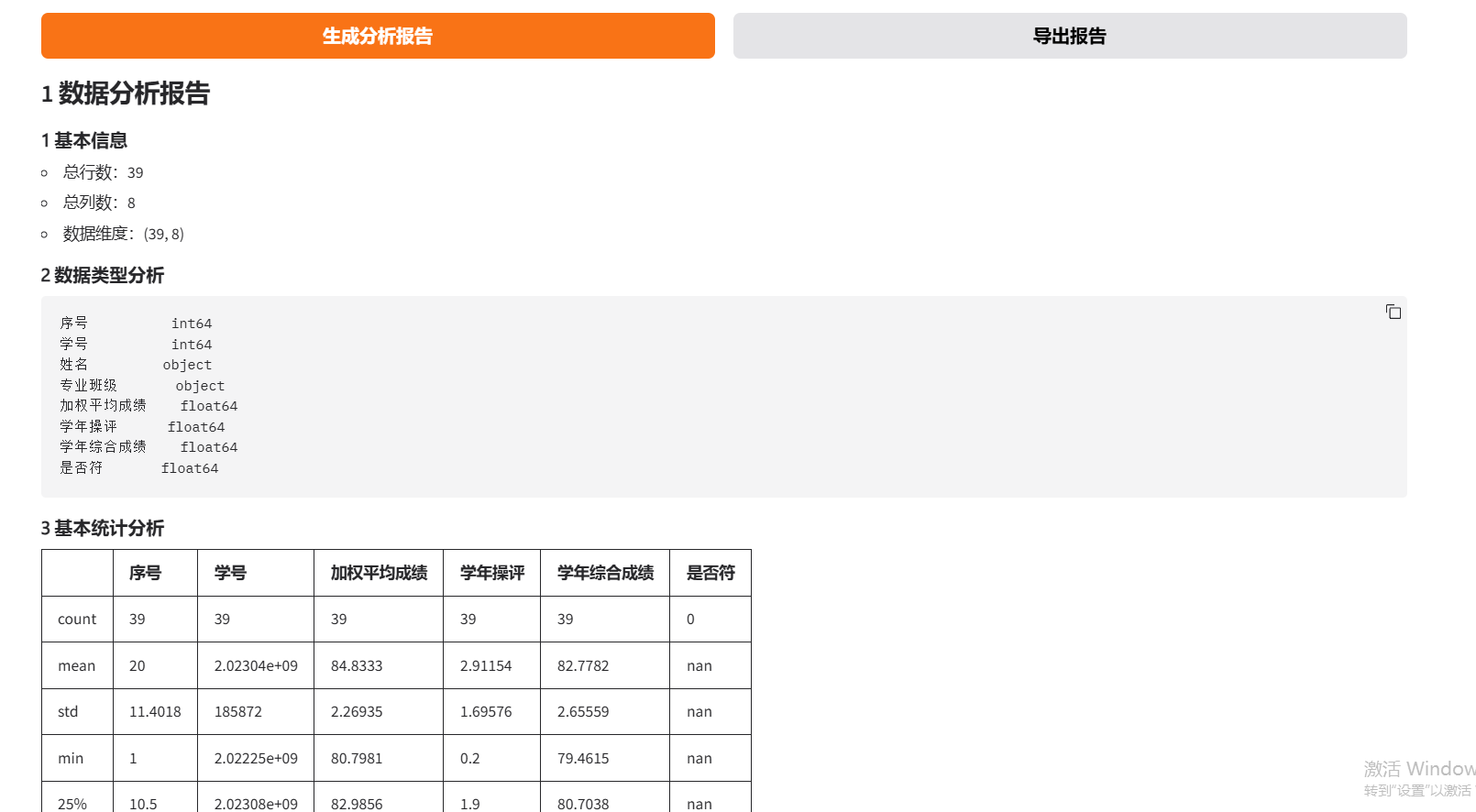
- 自动生成分析报告
- 智能对话分析
- 统计分析功能
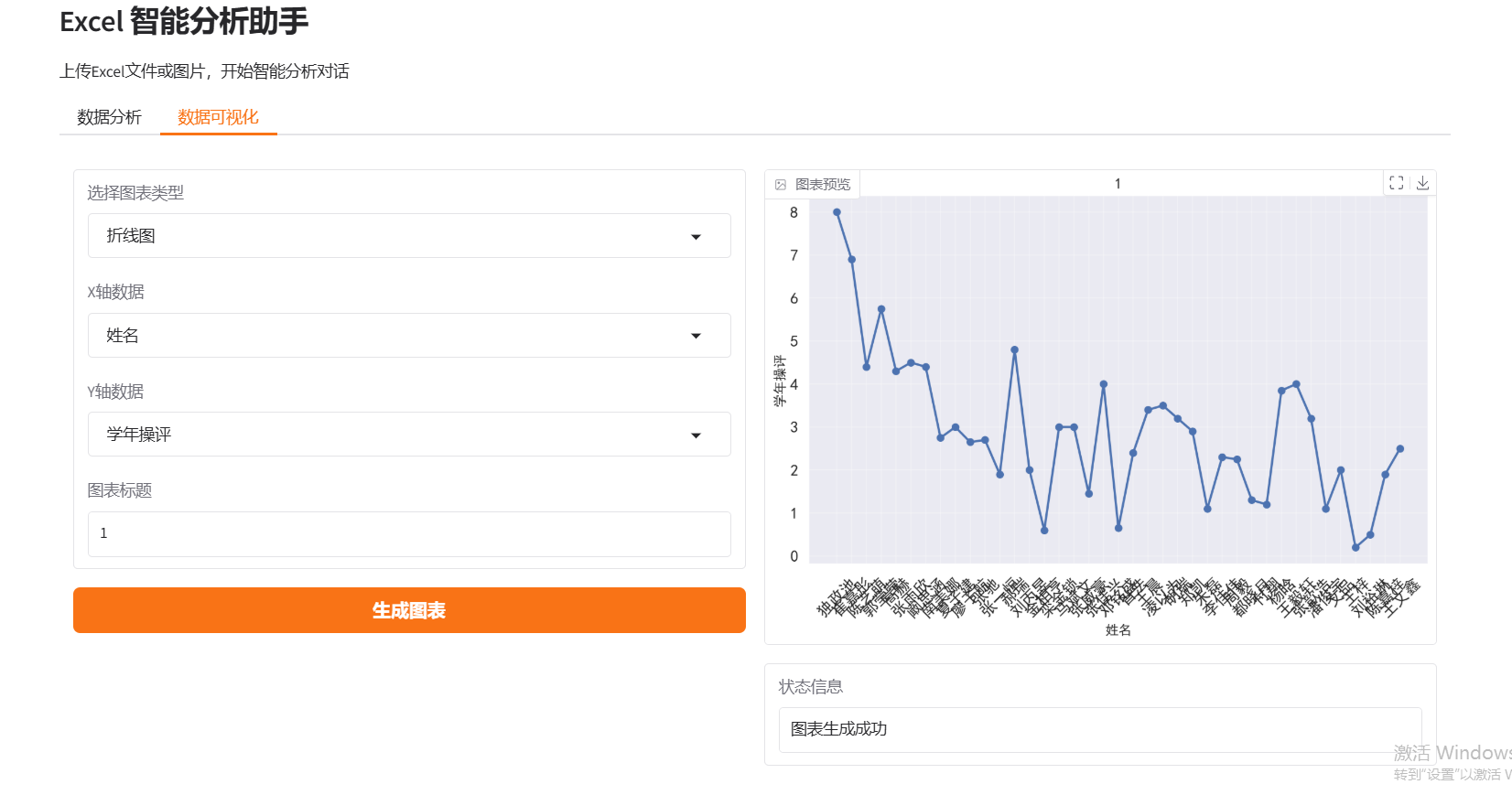
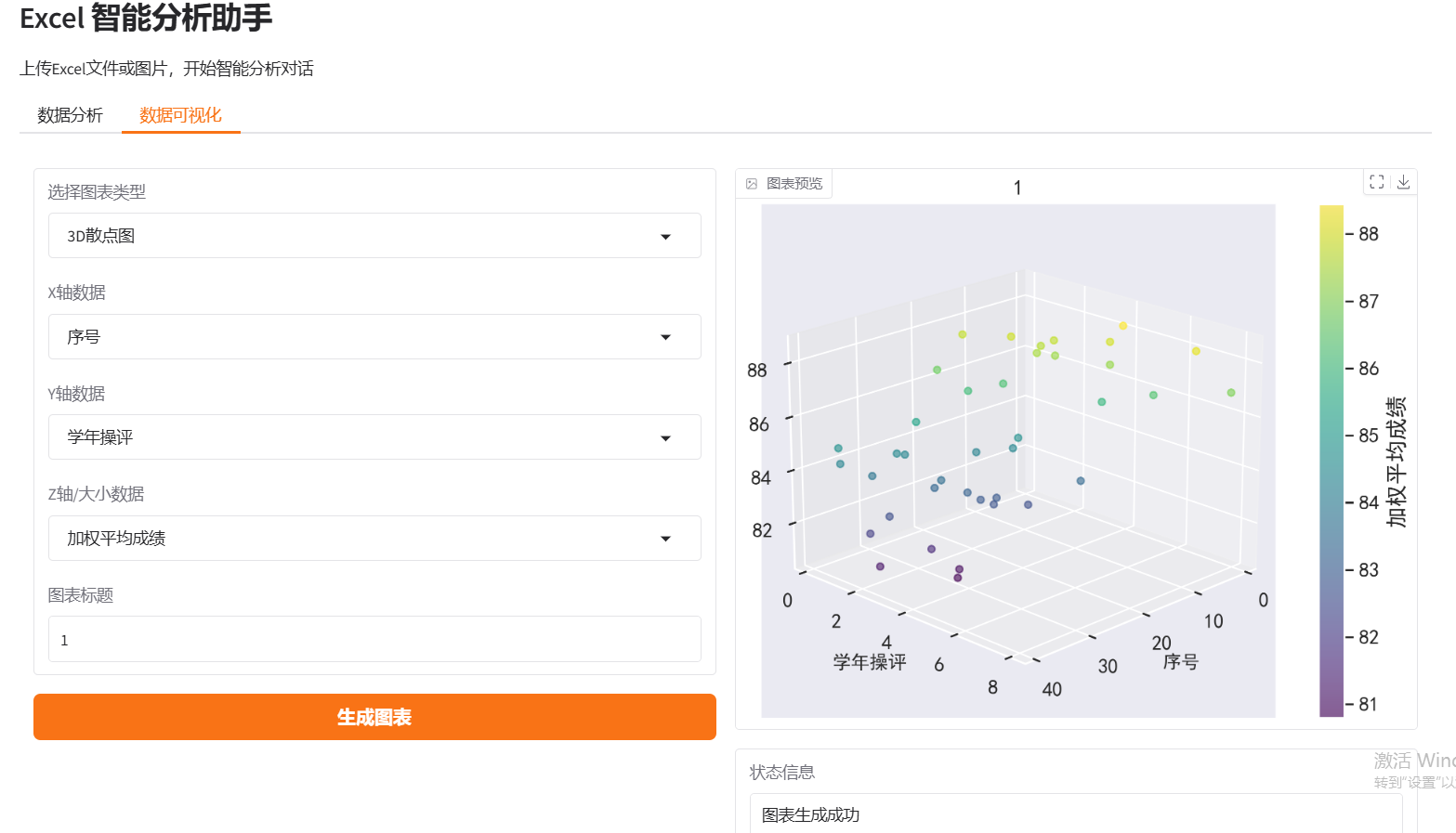
- 可视化图表生成
3. 交互界面模块
- 文件上传和预览
- 智能对话交互
- 图表定制生成
- 分析报告导出
4. 可视化实现
支持11种专业图表类型:
基础图表
- 折线图:展示趋势变化
- 柱状图:数值比较
- 散点图:相关性分析
- 饼图:占比展示
统计图表
- 箱线图:分布特征
- 直方图:频率分布
- 热力图:相关性矩阵
高级图表
- 3D散点图:三维关系
- 气泡图:多维数据
- 堆叠图:层次关系
- 面积图:累积趋势
主要技术实现
如何使用腾讯云OCR
官方文档:API Explorer - 云 API - 控制台
OCR识别表格
代码
class OcrTableAccurate:
def __init__(self, secret_id, secret_key):
self.secret_id = secret_id
self.secret_key = secret_key
def recognize_table_accurate(self, image_path):
# 读取图片文件
with open(image_path, "rb") as img_file:
img_data = img_file.read()
# 将图片转换为Base64编码
image_base64 = b64encode(img_data).decode()
# 实例化一个认证对象,入参需要传入腾讯云账户 SecretId 和 SecretKey
cred = credential.Credential(self.secret_id, self.secret_key)
# 实例化一个http选项,可选的,没有特殊需求可以跳过
httpProfile = HttpProfile()
httpProfile.endpoint = "ocr.tencentcloudapi.com"
# 实例化一个client选项,可选的,没有特殊需求可以跳过
clientProfile = ClientProfile()
clientProfile.httpProfile = httpProfile
# 实例化要请求产品的client对象,clientProfile是可选的
client = ocr_client.OcrClient(cred, "ap-guangzhou", clientProfile)
# 实例化一个请求对象,每个接口都会对应一个request对象
req = models.RecognizeTableAccurateOCRRequest()
params = {
"ImageBase64": image_base64
}
req.from_json_string(json.dumps(params))
# 返回的resp是一个RecognizeTableAccurateOCRResponse的实例,与请求对象对应
resp = client.RecognizeTableAccurateOCR(req)
# 输出json格式的字符串回包
return json.loads(resp.to_json_string())图片转Excel(解析识别的参数)
table_data = result['TableDetections'][0]['Cells'] # 获取单元格数据参数
result = {
'TableDetections': [ # 检测到的所有表格列表
{
'Cells': [ # 单个表格中的所有单元格
{
# 单元格位置参数
'RowTl': 0, # 行的起始位置(Top-Left,左上角),0行
'ColTl': 0, # 列的起始位置(Top-Left,左上角),0列。
'RowBr': 1, # 行的结束位置(Bottom-Right,右下角)。
'ColBr': 1, # 列的结束位置(Bottom-Right,右下角)。
'Text': '单元格文本内容' # 识别出的文本内容
'Type': 单元格的类型。
'Confidence': 置信度或识别准确度。
'Polygon': 定义单元格的多边形边界。此处定义表格中的4个点的位置。顺时针
},
# ... 更多单元格
]
}
]
}将识别的参数转化为DataFrame
# 找出表格的最大行列数
max_row = max(cell['RowBr'] for cell in table_data)
max_col = max(cell['ColBr'] for cell in table_data)
# 创建空的二维数组
rows = [['' for _ in range(max_col)] for _ in range(max_row)]
# 填充数据
for cell in table_data:
row_start = cell['RowTl']
col_start = cell['ColTl']
text = cell['Text']
# 处理合并单元格
row_end = cell['RowBr']
col_end = cell['ColBr']
# 填充所有涉及的单元格
for r in range(row_start, row_end):
for c in range(col_start, col_end):
rows[r][c] = text解析数据类
ExcelToDuckDB 是一个 Python 类,用于将 Excel 数据文件快速解析并导入到 DuckDB 数据库中。该类主要实现了以下功能:
通过混元大模型构建智能体
如何使用混元大模型的API:腾讯混元大模型 简介-API 中心-腾讯云
def chat_completions(self, input_text, template_name=None):
"""
发送聊天请求
:param input_text: 输入文本或SQL查询结果
:param template_name: 模板名称
:return: API响应或错误信息
"""
try:
# 实例化认证对象
cred = credential.Credential(self.secret_id, self.secret_key)
httpProfile = HttpProfile()
httpProfile.endpoint = "hunyuan.tencentcloudapi.com"
clientProfile = ClientProfile()
clientProfile.httpProfile = httpProfile
# 实例化客户端
client = hunyuan_client.HunyuanClient(cred, "ap-guangzhou", clientProfile)
req = models.ChatCompletionsRequest()
# 构建系统提示词
system_prompt = self.get_prompt_template(template_name)
# 构建请求参数
params = {
"Messages": [
{
"Role": "system",
"Content": system_prompt
},
{
"Role": "user",
"Content": input_text
}
],
"Model": "hunyuan-turbo-20241120"
}
req.from_json_string(json.dumps(params))
resp = client.ChatCompletions(req)Prompt模板
构建的提示词:会根据输入问题的分析是否需要深入回答
简单回答
def _build_data_context(self, message):
"""构建数据上下文"""
basic_stats = {
'total_rows': self.current_df.shape[0],
'total_cols': self.current_df.shape[1],
'null_count': self.current_df.isnull().sum().sum(),
'numeric_cols': self.current_df.select_dtypes(include=['int64', 'float64']).columns.tolist(),
'categorical_cols': self.current_df.select_dtypes(include=['object']).columns.tolist()
}
# 使用模型判断问题类型
question_analysis_prompt = f"""
请分析以下问题的类型,判断是否需要深度分析。
问题:{message}
请只回答"简单"或"深入"。
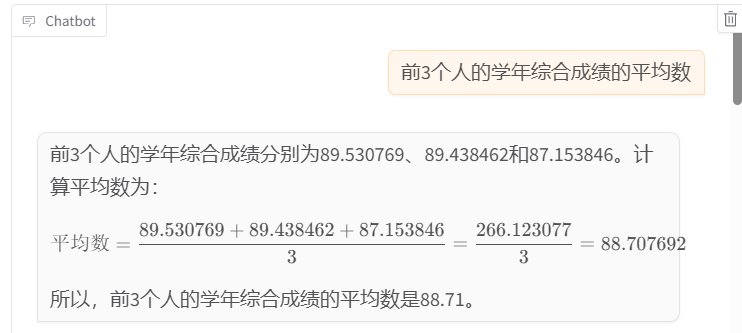
- 简单:如计算平均值、求和、查找最大最小值等基础操作。
- 深入:如分析趋势、寻找关系、提供建议、评估情况等需要综合分析的问题
"""
# 调用模型判断
analysis_type = self.analyzer.chat.chat_completions(question_analysis_prompt)
needs_deep_analysis = "深入" in self._format_response(analysis_type)
# 基础数据信息
data_context = f"""
数据基本信息:
- 数据规模:{basic_stats['total_rows']}行 × {basic_stats['total_cols']}列
- 缺失值:{basic_stats['null_count']}
- 数值列:{', '.join(basic_stats['numeric_cols'])}
- 分类列:{', '.join(basic_stats['categorical_cols'])}
数据内容:
{self.current_df.to_string()}
"""
# 根据模型判断结果添加分析要求
if needs_deep_analysis:
data_context += """
分析要求:
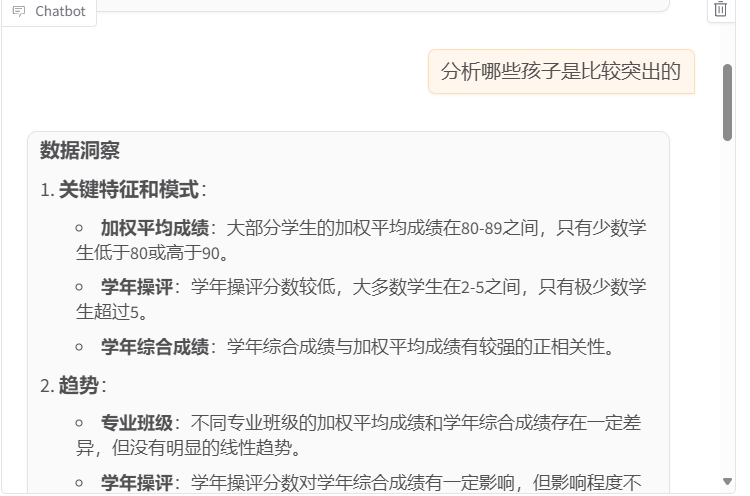
1. 数据洞察
- 识别关键特征和模式
- 发现数据中的趋势
- 分析异常和特殊情况
2. 统计分析
- 提供相关统计指标
- 解释数据分布特征
- 分析相关性(如适用)
3. 业务建议
- 提供数据驱动的见解
- 给出可行的改进建议
- 指出潜在的机会
4. 可视化建议
- 推荐合适的图表类型
- 建议关注的关键维度
5. 改进建议
- 指出数据质量问题
- 建议额外需要的数据
- 提供优化分析的方向
"""
else:
data_context += """
回答要求:
- 直接回答问题
- 确保计算准确
- 使用简洁的语言
"""
data_context += f"\n用户问题:{message}"
return data_context
应用场景
1. 企业数据分析
- 销售数据分析
- 财务报表分析
- 运营数据分析
- 市场调研分析
2. 个人数据处理
- 成绩单分析
- 消费记录分析
- 个人财务分析
- 数据整理归档
结语
Excel智能分析助手通过结合OCR技术和自然语言处理,为用户提供了一个简单易用的数据分析工具。无论是数据的导入转换,还是分析可视化,都能以智能化的方式完成,大大提高了数据分析的效率。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号