2025版:基于 KubeSphere v4 的 Kubernetes 生产环境部署架构设计及成本分析
原创
2025版:基于 KubeSphere v4 的 Kubernetes 生产环境部署架构设计及成本分析
原创
运维有术
修改于 2025-01-22 10:31:53
修改于 2025-01-22 10:31:53
KubeSphere 最佳实战:2025版:基于 KubeSphere v4 的 Kubernetes 生产环境部署架构设计及成本分析
2025 年云原生运维实战文档 X 篇原创计划 第 01 篇 |KubeSphere 最佳实战「2025」系列 第 01 篇
你好,我是术哥,欢迎来到运维有术。
今天分享的主题是:如何规划设计一个高可用、可扩展的中小规模生产级 Kubernetes 集群?
通过本文的指导,您将掌握以下设计生产级 Kubernetes 集群的必备技能:
集群规划能力
- 合理规划节点规模和资源配置
- 设计高可用的控制平面、计算平面、存储平面架构
- 规划网络拓扑和安全策略
- 制定存储解决方案
组件选型能力
- 选择适合的容器运行时(Container Runtime)
- 评估和选择网络插件(CNI Plugin)
- 规划监控、日志等可观测性组件
- 选择合适的存储解决方案
运维规划能力
- 制定监控告警方案
- 制定自动化运维管理方案
- 设计备份恢复方案
成本优化能力
- 评估资源使用成本
- 优化资源分配策略
1. 简介
1.1 架构设计概要
本文架构设计概要说明如下:
- 本架构适用于中小规模(节点数量 <=50 个)的 Kubernetes 生产环境,大型环境暂未经过生产验证,仅供参考。
- 所有节点采用云上虚拟机方式部署,基于成本和灵活性考虑,核心组件均采用自建方式(建议有条件的企业优先选用云厂商托管产品)。
- 本架构集成了开源的 WAF、堡垒机等基础安全组件,适用于一般安全等级的生产环境,对于金融、政务等高安全要求场景需要进一步加固。
- 本架构为 v2025 版,凝聚了本人多个生产环境的实践经验,根据实际运维过程中的问题和挑战不断完善,一直持续优化迭代中(欢迎反馈建议)
- 持久化存储:取消了 V1 版架构中的 GlusterFS,改用 OpenEBS 和 Ceph 组合方案。OpenEBS 主要用于本地存储(Local PV),Ceph 用于需要共享存储的场景,两者优势互补,既保证了性能又兼顾了可靠性和扩展性
- 整体架构基于 KubeSphere v4 构建,充分利用其容器平台能力,后续的功能实现和运维管理都将围绕 KubeSphere 展开。
本文主要内容包括以下几个部分:
- 选型分析:详细分析各个组件的选型依据和对比
- 部署架构图:展示完整的系统架构设计图
- 部署架构分层设计说明:对架构设计的详细解释和说明
- 部署节点规划:节点资源的具体规划方案
- 成本分析:根据规划计算在不同公有云上的构建成本
整个架构完整的安装部署步骤将在后续系列文档中详细介绍。
1.2 选择 KubeSphere v4 的理由
KubeSphere v4 引入了全新的 LuBan 可插拔架构,这是自 2018 年以来最具革命性的一次升级。以下是选择 KubeSphere v4 的核心理由:
1、全新的 LuBan 微内核架构
- 采用微内核设计,核心组件只保留系统必需功能
- 所有业务功能以扩展组件形式提供,实现真正的即插即用
- 支持扩展组件独立版本迭代和发布
- 显著降低了系统资源消耗
2、解决了历史版本的核心痛点
- 打破了发布周期长的限制,扩展组件可独立升级
- 实现快速问题响应,无需等待整体版本发布
- 彻底解决了代码耦合问题,前后端代码完全解耦
- 按需启用组件,避免资源浪费
3、更强大的扩展能力
- 提供统一的扩展中心(KubeSphere Marketplace)
- 支持第三方组件无缝集成到 KubeSphere 控制台
- 扩展组件可独立维护版本
- 支持自定义开发扩展组件
4、企业级云原生基础能力
- 多云多集群统一管理
- 微服务治理与服务网格
- DevOps 与 GitOps 持续交付
- 全方位可观测性(监控、日志、审计等)
5、面向未来的云原生操作系统
- 以 Kubernetes 为内核的分布式操作系统
- 支持跨云跨集群的应用统一分发
- 提供完整的云原生应用生命周期管理
- 持续集成主流云原生生态组件
6、可轻松解耦,避免厂商绑定
- 采用开源组件构建,可轻松解耦,避免厂商绑定
- 支持在不同的k8s集群上部署
除了上述理由外,KubeSphere 在同类产品中的竞争力依然保持领先。截至 2025 年,无论是功能完整性、易用性还是社区活跃度,在开源容器平台领域都处于领先地位。它不仅继承了早期版本的优势,还通过持续创新保持了技术领先性。如果您知道有其他更好的替代方案,欢迎在评论区留言讨论。
2. 部署架构设计总览
2.1 部署架构图
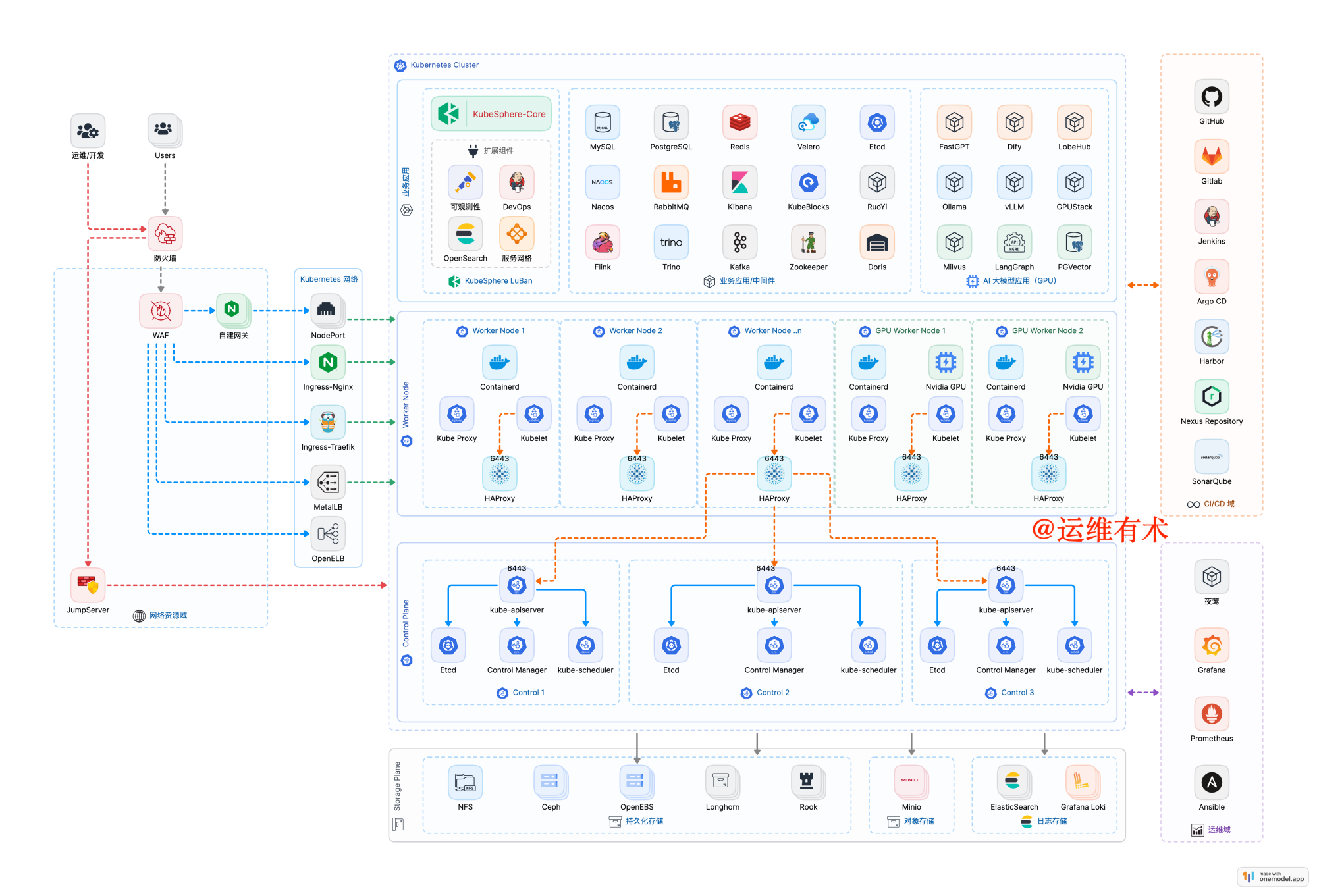
2.2 关键组件及部署版本
2025 年 1 月 适用的软件版本:
- 操作系统版本: openEuler 24.03 LTS SP1 x86_64
- KubeSphere:v4.1.2
- KubeKey: v3.1.7
- Kubernetes:v1.30.6
- Containerd:1.7.13
- ElasticSearch:8.17.x(选最新的)
- Ceph:18.x(选最新的)
- Minio:RELEASE.2024-12-18T13-15-44Z
2.3 网络规划
网络规划方案一:
分层、多网段,适用场景:
- 功能节点数量较多
- 网络安全要求高,需要严格的访问控制
- 不同功能模块间需要网络隔离
- 需要细粒度的安全策略管理
- 便于后期扩展和维护
功能域 | 网段 | 说明 |
|---|---|---|
网络资源域 | 192.168.8.0/24 | 堡垒机、WAF、代理网关作为南北向流量的转发节点,一定要和其他组件放在不同的网段 |
k8s 集群 | 192.168.9.0/24 | k8s 集群内部节点使用 |
存储平面 | 192.168.10.0/24 | 持久化存储、对象存储、日志存储域节点使用 |
运维/CICD域 | 192.168.11.0/24 | 运维监控工具、中间件、CI/CD工具 |
网络规划方案二:
分层、同网段,适用场景:
- 小规模部署环境
- 网络安全要求不高
- 网络架构简单,无需复杂的网络隔离
- 运维管理成本敏感
- 快速部署验证环境
- 所有节点都放在一个网段
功能域 | 网段 | 说明 |
|---|---|---|
网络资源域/k8s 集群/存储集群/运维/CICD域 | 192.168.9.0/24 | 所有服务部署在相同的网段 |
3. 部署架构分层设计说明
整体的部署架构设计采用分层分域的思想,主要分为以下7个层/域:
- 用户访问层
最终用户访问入口,支持多种访问渠道。
- 安全设备层
防火墙、WAF等安全防护、确保整体架构安全性。
- 代理转发层
实现流量转发和负载均衡,包括自建网关、负载均衡、K8S网络服务。
- Kubernetes 集群域
容器编排与管理、应用部署与运行。
- 存储平面
提供数据持久化能力包括:与 k8s 集群集成的持久化存储、对象存储、日志存储。
- CI/CD域
提供整体的 DevOps能力,包括代码存储、镜像存储、持续集成、持续部署、自动化流水线等。
- 运维域
提供自动化运维和可观测性管理等综合能力,包括自动化运维工具、监控告警、运维大屏等。
此外,可根据实际需求在 K8S 集群外增设中间件域,用于部署常用中间件和其他服务,比如对性能要求较高的数据库。
3.1 用户访问层
用户访问层主要面向最终用户,包括但不限于:
- Web浏览器访问
- 移动端APP访问
- API接口调用
- 第三方系统集成访问
无论通过何种渠道访问平台的实际业务功能,都需要经过用户访问层的统一入口,以确保访问的规范性和安全性。
3.2 安全设备层
安全是重中之重,所有上线的业务,安全设备是必不可少的,本架构设计里只提到了防火墙、WAF、堡垒机,实际使用中应该还有更多,这个只能大家根据需求自行组合了。因为,安全设备层不在我的职责范围内,我只能说必须有,但是很多细节我也说不清,索性就不过多介绍了。
1、防火墙(FireWall)
- 作为网络安全的第一道防线,负责网络访问控制和流量过滤
- 生产环境建议采用公有云服务或专业厂商设备
- 本架构实战环境不涉及具体部署配置
2、Web应用防火墙(WAF)
- 专门针对 Web 应用的安全防护,可防御 SQL 注入、XSS 等常见 Web 攻击
- 公有云环境推荐使用云服务商提供的 WAF 产品
- 本架构实战环境将部署开源的雷池 WAF作为示例
3、堡垒机
- 统一运维安全管控平台,实现集中化的权限管理和操作审计
- 本设计采用主流开源产品 JumpServer
- 具备条件的用户可选用云服务商提供的商业产品
除以上组件外,企业可根据自身安全需求,增加 IDS/IPS、漏洞扫描等其他安全设备。安全体系的具体实现需要专业安全团队的规划和建设。
3.3 代理转发层
代理转发层提供了三种主流的技术方案选择,可以根据实际需求进行单独使用或组合部署。
1、自建 Nginx 代理网关
采用双机热备的架构,部署 Nginx + Keepalived 服务实现负载均衡的、高可用的四层和七层流量转发,通过配置域名规则或是 IP + 端口,将请求转发至后端 K8S 集群对应的 NodePort 端口。
优点:
- 部署维护简单,适合运维新手
- 配置灵活,可自定义规则
- 成熟稳定,运维经验丰富
缺点:
- 配置变更需要人工操作
- 多节点配置同步存在风险
- 扩展性受限
2、Kubernetes Ingress
Kubernetes 原生的 Ingress 控制器方案,本设计采用两个主流实现:
- Ingress-Nginx: 基于 Nginx 的企业级 Ingress 控制器,性能稳定,配置灵活简单。
- Ingress-Traefik: 现代化的反向代理和负载均衡工具,功能更加强大,相对复杂。
3、Kubernetes + 负载均衡方案
结合外部负载均衡实现服务暴露和流量转发。云环境可使用云厂商提供的负载均衡服务。自建环境,可选用开源方案,主要包括:
- MetalLB
- OpenELB
3.4 k8s 集群层
Kubernetes 集群采用高可用的 3 Control + N Worker + N GPU Worker架构设计,该架构具有以下特点:
- 实现了控制平面的高可用性
- 通用 Worker 节点承载中间件、常规业务负载的部署需求,并为后期扩容预留空间。
- GPU Worker 节点承载 AI、大模型、机器学习等人工智能需要使用 GPU 资源的部署需求。
Control 节点配置:
- 数量:3个节点
- 用途:部署 Kubernetes 核心管理组件和 ETCD 服务
- 说明:对于大规模生产环境,建议将 ETCD 单独部署以提升性能和可靠性
通用 Worker 节点配置:
- 用途:运行 KubeSphere 和通用业务应用
- 初始数量:初始至少 3 个节点
- 扩容原则:建议以 3 的倍数进行扩容,符合副本冗余策略
GPU Worker 节点配置:
- 用途:专门用于运行 GPU 相关工作负载
- 数量:根据实际 GPU 计算需求确定
集群高可用,采用 KubeKey 内置的本地负载均衡模式:
- 在每个工作节点部署 HAproxy 作为负载均衡器
- Control 节点的组件直连本地 kube-apiserver
- Worker 节点通过本地 HAproxy 代理访问多个 kube-apiserver
高可用模式说明:
- 优点:无需额外的外部负载均衡器,部署维护简单
- 缺点:引入额外健康检查开销,性能略低于专用负载均衡方案
- 建议:大规模生产环境建议使用独立的负载均衡器或云服务商提供的负载均衡服务
3.5 存储平面
存储平面有三种类型:持久化存储、日志存储、对象存储。
1、持久化存储
本架构设计选择了使用 OpenEBS 和 Ceph 组合的方式,作为 Kubernetes 集群的持久化存储
- OpenEBS :使用 Worker 节点本地存储,提供 local 模式的本地存储解决方案,可以获取更高的性能。适用自身有高可用数据同步、存储方案的应用,例如 MySQL 主从复制,ETCD 集群。
- Ceph:提供跨节点、分布式、多副本、高可用的存储解决方案,
持久化存储方案选型说明:
存储方案 | 优点 | 缺点 | 说明 |
|---|---|---|---|
Ceph | 分布式存储、高可用性、高扩展性、支持多副本 | 运维复杂、故障处理难度大、需要专业技能 | 曾经经历过 3 副本全部损坏数据丢失的惨痛经历,因此没有能力处理各种故障之前不会再轻易选择 |
OpenEBS | 易于部署和管理、支持本地存储和网络存储、动态供应、支持快照和备份 | 相比Ceph性能略低、功能相对简单 | 适合中小规模部署,特别是对运维要求不高的场景 |
NFS | 使用广泛、部署简单、成熟稳定 | 单点故障风险、网络抖动影响大、性能受限 | 生产环境使用较多,但单点和网络抖动风险较大,需要谨慎评估 |
Longhorn | 企业级存储方案、支持备份恢复、支持数据复制、界面友好 | 社区相对较新、生产验证案例较少 | Rancher 开源的企业级云原生容器存储解决方案,值得关注但需要更多实践验证 |
存储方案的选择需要综合考虑以下因素:
- 业务对数据可靠性的要求
- 团队的技术储备和运维能力
- 成本预算
- 性能需求
- 对于具备高可用能力的工作负载,建议选择 OpenEBS 作为存储方案,可以充分利用本地存储的性能优势
- 在我们的业务场景中,主要用于存储日志数据,可以容忍短期的数据不可用和数据丢失。基于这一特点,我们选择了 Ceph 作为存储方案
- 初期存储容量规划为每个节点 1TB,可根据实际使用情况动态扩容。建议预留 20%-30% 的缓冲空间用于应对数据增长
2、日志存储
日志存储选择了两种方案:
方案一:广泛使用的 EL(F)K 方案,主要用于存储和分析 KubeSphere 日志、事件等插件采集的日志数据
ElasticSearch 具有以下优势:
- 分布式架构,支持水平扩展
- 强大的全文检索和分析能力
- 丰富的可视化和监控工具
- 完善的安全机制
- 与 Kubernetes 生态系统良好集成
实际部署采用了 3 节点的 ElasticSearch 集群架构:
- 每个节点部署一个 ElasticSearch 实例
- 采用 3 副本机制确保数据高可用性
- 启用用户名密码认证
- k8s 集群部署 flunt-bit 采集日志
存储容量规划:
- 初期每个节点分配 1TB 数据盘
- 实际运行数据表明:30+ 业务模块,180天日志保留周期,实际存储使用不到 500GB
- 建议采用动态存储配置,根据实际使用量调整
同时部署了 Kibana 作为日志分析和管理平台:
- 部署在 K8s 集群内,直接连接 ElasticSearch 集群
- 提供丰富的日志查询、分析和可视化功能
方案二:轻量的方案 PLG
- Promtail:日志采集
- Loki:日志存储、查询
- Grafana:可视化管理
3、对象存储
对象存储选择了 MinIO 作为解决方案,主要用于 Kubernetes 集群中需要对象存储服务的应用场景。MinIO 具有以下特点:
- 兼容 S3 API,可以无缝对接云存储
- 支持高可用部署和数据多副本
- 提供强大的数据加密和访问控制
- 适合存储非结构化数据如图片、视频等
- 可以作为 AI/ML 工作负载的数据湖
3.6 CI/CD 域
CI/CD 采用了轻量级的配置方案,主要基于 KubeSphere 内置的 DevOps 功能进行构建。通过 Jenkins 流水线实现了完整的 CI/CD 自动化流程,包括代码构建、镜像制作与推送、应用部署、发布审核等环节。
主要组件架构如下:
1、Jenkins
- 采用 KubeSphere 定制的 DevOps 插件
- 部署在 Kubernetes 集群内
- 支持动态创建构建 Pod
- 提供丰富的流水线模板
2、GitLab
- 在 K8S 集群之外独立部署
- 统一管理应用代码和运维配置
- 支持 GitOps 工作流,提供代码版本控制和 CI 触发
3、Harbor
- 在 K8S 集群之外独立部署
- 与 GitLab 共用一台虚拟机
4、Nexus
- 在 K8S 集群之外独立部署
- 可选组件,适用于内网依赖包统一管理的场景
3.7 运维管理域规划
监控、告警、自动化运维、其他运维辅助工具都规划在了运维管理域,机器的分配可以根据实际情况规划。
主要包含以下组件:
Ansible:
- 自动化运维管理工具,执行日常批量运维管理操作
- 用于集群节点的配置管理和应用部署
- 支持多环境配置和版本控制
- 可实现运维流程标准化和自动化
Prometheus、Alertmanager:
- 用于实现 K8S 集群和集群上部署的业务应用组件的监控和告警
- KubeSphere 集成的也挺好用,可以额外搭建一套留作他用
- 提供丰富的监控指标和告警规则
夜莺监控
- 比较好的开源监控产品
- 可以实现 k8s 全生态组件监控
3.8 中间件域
有一些数据或是服务,在做架构设计时觉得部署在 K8S 集群上不靠谱,可以在 K8S 集群外部的虚拟机上独立部署。这样做的主要考虑是:
- 部分中间件对稳定性要求极高,需要独立部署以避免资源竞争
- 某些中间件需要特定的系统配置和优化,在虚拟机上更容易实现
- 便于维护和故障排查,减少对 K8S 集群的依赖
- 可以针对性地进行资源分配和性能优化
4. 集群部署资源规划
按最小节点规划,先看一眼总体的资源需求,整个集群使用了 20 台虚拟机,100核 CPU、376GB 内存、800GB 系统盘、16000GB 数据盘。
接下来我们详细说一下每一层的节点如何规划部署。
4.1 安全设备层
使用两台独立的虚拟机部署开源应用,自建 WAF 和 堡垒机,云上环境建议使用云服务商的产品。
节点角色 | 主机名 | CPU(核) | 内存(GB) | 系统盘(GB) | 数据盘(GB) | IP | 备注 |
|---|---|---|---|---|---|---|---|
WAF | waf | 4 | 8 | 40 | 192.168.9.51 | 部署开源 WAF,配置暂定后期根据运行情况调整。 | |
堡垒机 | jumperserver | 4 | 8 | 40 | 192.168.9.52 | 部署 JumpServer,配置暂定后期根据运行情况调整。 | |
合计 | 2 | 8 | 16 | 80 |
4.2 代理网关节点规划
使用两台独立的虚拟机部署 Nginx + Keepalived,自建高可用的代理网关。
节点角色 | 主机名 | CPU(核) | 内存(GB) | 系统盘(GB) | 数据盘(GB) | IP | 备注 |
|---|---|---|---|---|---|---|---|
nginx代理 | nginx-1 | 2 | 4 | 40 | 192.168.9.61/192.168.9.60 | 自建代理网关 | |
nginx代理 | nginx-2 | 2 | 4 | 40 | 192.168.9.62/192.168.9.60 | 自建代理网关 | |
合计 | 2 | 4 | 8 | 80 |
4.3 Kubernetes 集群节点规划
规划说明:
- 初期按照 3 Control 、3 Worker、3 GPU worker 计算,具体配置还需要根据实际情况调整。
- 数据盘初始考虑 500G 容量,如果使用 openEBS 作为持久化存储,建议每个 Worker 节点再额外增加一块儿 1000G 的数据盘
节点角色 | 主机名 | CPU(核) | 内存(GB) | 系统盘(GB) | 数据盘(GB) | IP | 备注 |
|---|---|---|---|---|---|---|---|
Control 节点 | ksp-control-1 | 4 | 16 | 40 | 500 | 192.168.9.91 | 控制节点 |
Control 节点 | ksp-control-2 | 4 | 16 | 40 | 500 | 192.168.9.92 | 控制节点 |
Control 节点 | ksp-control-3 | 4 | 16 | 40 | 500 | 192.168.9.93 | 控制节点 |
Worker 节点 | ksp-worker-1 | 8 | 32 | 40 | 500 | 192.168.9.94 | 部署通用工作负载 |
Worker 节点 | ksp-worker-2 | 8 | 32 | 40 | 500 | 192.168.9.95 | 部署通用工作负载 |
Worker 节点 | ksp-worker-3 | 8 | 32 | 40 | 500 | 192.168.9.96 | 部署通用工作负载 |
GPU Worker 节点 | ksp-gpu-worker-1 | 8 | 32 | 40 | 500 | 192.168.9.97 | 部署AI、GPU应用型工作负载 |
GPU Worker 节点 | ksp-gpu-worker-2 | 8 | 32 | 40 | 500 | 192.168.9.98 | 部署AI、GPU应用型工作负载 |
GPU Worker 节点 | ksp-gpu-worker-3 | 8 | 32 | 40 | 500 | 192.168.9.99 | 部署AI、GPU应用型工作负载 |
合计 | 9 | 60 | 240 | 360 | 4500 |
4.4 存储节点规划
存储节点包含持久化存储、日志存储、对象存储节点:
- 每个节点的磁盘数量和容量请根据实际需求规划,本设计方案以单盘 1000G 为例。
- 如果不使用 Ceph 可以删除持久化存储节点
- 对象存储使用 Minio,考虑到集群最小磁盘数要求,所以选择 4 节点
方案一:适合生产环境 ,每个存储角色按建议副本数配置节点数量和磁盘容量。
节点角色 | 主机名 | CPU(核) | 内存(GB) | 系统盘(GB) | 数据盘(GB) | IP | 备注 |
|---|---|---|---|---|---|---|---|
持久化存储 | ksp-storage-1 | 4 | 16 | 40 | 1000 | 192.168.9.101 | 部署 Ceph,三副本 |
持久化存储 | ksp-storage-2 | 4 | 16 | 40 | 1000 | 192.168.9.102 | 部署 Ceph,三副本 |
持久化存储 | ksp-storage-3 | 4 | 16 | 40 | 1000 | 192.168.9.103 | 部署 Ceph,三副本 |
日志存储节点 | elastic-1 | 4 | 16 | 40 | 1000 | 192.168.9.111 | 部署 ElasticSearch,三副本 |
日志存储节点 | elastic-2 | 4 | 16 | 40 | 1000 | 192.168.9.112 | 部署 ElasticSearch,三副本 |
日志存储节点 | elastic-3 | 4 | 16 | 40 | 1000 | 192.168.9.113 | 部署 ElasticSearch,三副本 |
对象存储节点 | minio-1 | 4 | 16 | 40 | 1000 | 192.168.9.121 | Minio 集群最小四个节点 |
对象存储节点 | minio-2 | 4 | 16 | 40 | 1000 | 192.168.9.122 | Minio 集群最小四个节点 |
对象存储节点 | minio-3 | 4 | 16 | 40 | 1000 | 192.168.9.123 | Minio 集群最小四个节点 |
对象存储节点 | minio-4 | 4 | 16 | 40 | 1000 | 192.168.9.124 | Minio 集群最小四个节点 |
合计 | 10 | 40 | 160 | 400 | 10000 |
方案二:适合研发测试环境,适配 Minio 集群最小 4 节点要求
节点角色 | 主机名 | CPU(核) | 内存(GB) | 系统盘(GB) | 数据盘(GB) | IP | 备注 |
|---|---|---|---|---|---|---|---|
存储节点 | minio-1 | 4 | 16 | 40 | 1000+1000+1000 | 192.168.9.101 | 部署Ceph、ElasticSearch、Minio |
存储节点 | minio-2 | 4 | 16 | 40 | 1000+1000+1000 | 192.168.9.102 | 部署Ceph、ElasticSearch、Minio |
存储节点 | minio-3 | 4 | 16 | 40 | 1000+1000+1000 | 192.168.9.103 | 部署Ceph、ElasticSearch、Minio |
存储节点 | minio-3 | 4 | 16 | 40 | 1000 | 192.168.9.104 | 部署 Minio |
合计 | 4 | 16 | 64 | 160 | 10000 |
4.5 运维域节点规划
不考虑高可用的问题,采用一个节点部署自动化运维工具 Ansible 以及 Prometheus、Grafana、夜莺等监控产品。
节点角色 | 主机名 | CPU(核) | 内存(GB) | 系统盘(GB) | 数据盘(GB) | IP | 备注 |
|---|---|---|---|---|---|---|---|
运维管理 | monitor | 4 | 16 | 40 | 500 | 192.168.9.71 |
4.6 CI/CD域节点规划
不考虑高可用的问题,采用二个节点部署 GitLab、Harbor、Nexus、Jenkins 等组件。
节点角色 | 主机名 | CPU(核) | 内存(GB) | 系统盘(GB) | 数据盘(GB) | IP | 备注 |
|---|---|---|---|---|---|---|---|
CI | cicd-1 | 4 | 16 | 40 | 500 | 192.168.9.72 | |
CD | cicd-2 | 4 | 16 | 40 | 500 | 192.168.9.73 | |
合计 | 2 | 8 | 32 | 80 | 1000 |
上面的节点资源配置规划,不合理的地方,或是可以优化改进的地方,欢迎各位在评论区留言讨论。
5. 成本分析
回顾一下整个架构规划的计算和存储资源总数,整个最小集群使用了 20 台虚拟机,100核 CPU、376GB 内存、800GB 系统盘(不要钱)、16000GB 数据盘。
看着这些汇总数据,我自己都有点害怕,降本增效的当下,这有点多啊。
接下来我们根据节点规划详细算算账,这到底要花多少银子?
货比三家,特意选了几家公有云服务商,用官方提供的价格计算器算了算公开报价(所有报价均为 2025 年1 月报价)。
成本计算中有几点需要特别注意:
- 规划中不包含防火墙等安全设备
- 报价中不包括带宽费用
- 报价分析中不包含 GPU 服务器报价
- 本报价只是公开报价成本,仅供参考。(渠道不同,各大云平台折扣也不同)
- 为了对比报价成本,所有选型都用的参数类似的产品,实际使用中请根据需求调整,例如,CPU、硬盘的调整。
5.1 计算节点类型汇总及成本分析
配置规格汇总:
配置类型 | 数量 |
|---|---|
2C 4G | 2 |
4C 8G | 2 |
4C 16G | 10 |
8C 32G | 6 - 3台GPU = 3 |
合计 | 20 - 3=17 |
公开报价汇总:
公有云平台 | 2C 4G(单价) | 2C 4G(2台 总价) | 4C 8G(单价) | 4C 8G(2台 总价) | 4C 16G(单价) | 4C 16G(10台 总价) | 8C 32G(单价) | 8C 32G(3台 总价) | 备注 |
|---|---|---|---|---|---|---|---|---|---|
阿里云 | 1,730.43 | 3,460.86 | 3,256.85 | 6,513.7 | 4,122.10 | 41,221 | 8,040.19 | 24,120.57 | 北京、计算型 c7/通用型 g7、系统盘(PL0,单盘IOPS性能上限1万) |
华为云 | 1,878.20 | 3,756.4 | 3,476.40 | 6,952.8 | 4,807.60 | 48,076 | 9,335.20 | 28,005.6 | 北京、通用计算 S7、系统盘(通用型SSD) |
天翼云 | 1,734.00 | 3,468 | 3,304.80 | 6,609.6 | 4,610.40 | 46,104 | 9,057.60 | 27,172.8 | 北京、通用型s6、系统盘(高 IO) |
腾讯云 | 1,504.80 | 3,009.6 | 3,025.44 | 6,050.88 | 4,438.56 | 44,385.6 | 8,677.92 | 26,033.76 | 北京、标准型S5、系统盘(通用型SSD) |
5.2 数据盘类型汇总及成本分析
因为,系统盘不用额外算钱,包含在计算资源之内(实际上在云主机选择的时候可以选择硬盘大小,大小不同价格也不同)。所以,我们只给数据盘买单。磁盘类型设计方案中使用了统一的高IO类型,实际中请根据服务需要选择。
磁盘规格汇总:
数据盘规格 | 数量 |
|---|---|
500G | 12-3 |
1000G | 10 |
合计 | 22-3 |
公开报价汇总
公有云平台 | 500G(单价) | 500G(9 块总价) | 1000G(单价) | 1000G(10 块总价) | 备注 |
|---|---|---|---|---|---|
阿里云 | 6,000 | 54,000 | 4,292.40 | 42,924 | 北京、ESSD PL1云盘、5万IOPS / 350MB吞吐量、¥1/1 GiB/月 |
华为云 | 3,500 | 31,500 | 7,000 | 70,000 | 北京、通用型SSD、2万IOPS / 250MiB/s吞吐量、7 元/GB/年 |
天翼云 | 3,570 | 32,130 | 7,140 | 71,400 | 北京、通用型SSD、2万IOPS / 250MiB/s吞吐量、71.40 元/10GB/年、0.7 元/GB/月 |
腾讯云 | 2,490 | 22,410 | 4,980 | 49,800 | 北京、通用型SSD、1万IOPS / 190MB/s吞吐量、0.5 元/GB/月 |
5.3 总成本合计分析
云平台 | 计算资源总价(人民币/元/年) | 存储资源总价(人民币/元/年) | 最终总价 |
|---|---|---|---|
阿里云 | 75,316.13 | 96,924 | 172,240.13 |
华为云 | 86,790.8 | 101,500 | 188,290.8 |
天翼云 | 83,354.4 | 103,530 | 186,884.4 |
腾讯云 | 79,479.84 | 72,210 | 151,689.84 |
综合算下来,这套架构使用的云上资源成本多少还是有点费钱的,预计公开报价总成本最少的平台是腾讯云,需要人民币 151,689.84 元/年。作为一个合格的运维架构师,架构设计中成本考虑是一个重要因素,要是拿不到很好的折扣价,老板估计要干掉我了。(至于实际价格就各凭本事喽!!!)
5.4 GPU 服务器成本参考
GPU 的型号、容量需根据业务需求确定,本文不做详细说明,只列出几个低端显卡的费用说明。
云平台 | 单价/年 | 配置 | 显卡 | 配置说明 |
|---|---|---|---|---|
阿里云 | 17811.60(4折) | 4C 30G | 1 张 Nvidia P100 GPU 16G | Intel Xeon E5-2682 V4(Broadwell)处理器,2.5 GHz主频。搭配 Nvidia P100 GPU,单颗 GPU 具有3584个 CUDA 核心,16 GiB 显存,9.3 TFLOPS 单精度浮点和4.7 TFLOPS双精度浮点计算能力。 |
阿里云 | 36647.40 (4折) | 8C 32G | 1 张 Nvidia V100 GPU 16G | Intel Xeon(Skylake) Platinum 8163 处理器,2.5 GHz主频。 |
华为云 | 79,178.00 | 8C 64G | 1 张 Nvidia V100 GPU 16G | Intel SkyLake 6151 3.0GHz |
以上,就是我今天分享的全部内容。下一期分享的内容还没想好,敬请期待开盲盒。
如果你喜欢本文,请分享、收藏、点赞、评论! 请持续关注公众号 @运维有术,及时收看更多好文!
欢迎加入 「知识星球|运维有术」 ,获取更多的 KubeSphere、Kubernetes、云原生运维、自动化运维、大数据、AI 大模型、Milvus 向量库等实战技能。
免责声明:
- 笔者水平有限,尽管经过多次验证和检查,尽力确保内容的准确性,但仍可能存在疏漏之处。敬请业界专家大佬不吝指教。
- 本文所述内容仅通过实战环境验证测试,读者可学习、借鉴,但严禁直接用于生产环境。由此引发的任何问题,作者概不负责!
Get 本文实战视频(请注意,文档视频异步发行,请先关注)
版权声明
- 所有内容均属于原创,感谢阅读、收藏,转载请联系授权,未经授权不得转载。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号