高斯过程回归与sklearn代码实现
原创

一、简介
高斯过程回归是一个强大而灵活的非参回归工具,在机器学习和统计中经常应用。在处理输入和输出是连续变量且关系不明确的问题中尤其有用。高斯过程回归是一种贝尔斯方法,能用于预测概率建模,这使得其在优化、时间序列预测等方面成为重要工具。高斯过程回归有关于高斯过程,高斯过程本质是一系列的随机变量,其中任何有限的变量组合都有相同的高斯分布。高斯过程可以被视为一种函数的分布。
1.1 有关高斯过程的主要概念
高斯过程是一种非参、概率模型在统计和机器学习中经常被用于回归、分类和不确定度测量。它描绘了一组随机变量,每个变量遵从相同的联合高斯分布,并且可以有有限的数量。高斯过程是一种多功能且有效的技术,用于建模数据中的复杂关系,并生成带有相关不确定性的预测。
高斯过程的特点:
非参数特性:高斯过程能够适应数据的复杂性,因为它们不依赖于固定数量的模型参数。
概率预测:高斯过程的预测可以量化,因为它们以概率分布的形式提供预测结果。
插值和平滑:高斯过程对于噪声较大或样本不规则的数据非常有用,因为它们在平滑噪声数据和在数据点之间进行插值方面表现良好。
超参数的边缘化:通过消除对超参数调整的明确需求,它们对超参数进行边缘化,从而使模型更简单。
均值函数
在高斯过程中,所建模函数在每个输入点的预测值由均值函数表示。它作为对基础数据结构的基本假设。均值函数通常默认设置为零,但并不一定如此,可以根据数据特性或领域专业知识进行调整。通过影响预测的中心趋势,它帮助学习者识别数据中的模式或趋势。高斯过程通过包含均值函数,提供包含不确定性以及点估计的概率预测。
协方差(核)函数
协方差函数,也称为核函数,在高斯过程中用于测量输入数据点之间的相似性。它在表征 本模型的行为中至关重要,影响从先验分布中选择函数。协方差函数通过测量成对相似性来确定函数值之间的相关性。由于不同的核函数捕捉不同类型的相关性,高斯过程 能够适应从平滑趋势到复杂结构的各种数据模式。核的选择对模型的性能有着显著影响。
先验分布
在高斯过程中,先验分布是在观察到任何数据之前,我们对函数预先判定。通常由协方差(核)函数和均值函数来描述。协方差函数描述了不同输入点处函数值之间的相似性或相关性,而均值函数则编码了我们于数据之前的期望。高斯过程在此基础上创建函数的分布。在高斯过程中,可以选择先验分布以表示数据的不确定性、整合领域知识或指示数据的平整度。
高斯过程本质上描述了定义在映射函数上的概率分布,即随机函数。
1.2 高斯过程回归的概念
对于回归任务,采用一种称为高斯过程回归的非参数概率机器学习模型。它是建模输入与输出变量之间复杂和模糊交互的强大工具。在 高斯过 回归中,假设数据点是由多元高斯分布生成的,目标是推断这个分布。


1.3 高斯过程回归的步骤
- 数据收集:收集你的回归问题的输入-输出数据对。
- 选择核函数:选择一个适合你问题的协方差函数(核)。核的选择会影响高斯过程回归可以建模的函数形状。
- 参数优化:通过最大化数据的似然性来估计核函数的超参数。这可以使用诸如梯度下降等优化技术来完成。
- 预测:给定一个新的输入,使用训练好的模型进行预测。高斯过程回归提供了预测的均值以及相关的不确定性(方差)。
二、代码实现
import matplotlib.pyplot as plt
from sklearn.gaussian_process import GaussianProcessRegressor
from sklearn.gaussian_process.kernels import RBF
from sklearn.model_selection import train_test_split
# Generate sample data
np.random.seed(0)
X = np.sort(5 * np.random.rand(80, 1), axis=0)
y = np.sin(X).ravel()
# Add noise to the data
y += 0.1 * np.random.randn(80)
# Define the kernel (RBF kernel)
kernel = 1.0 * RBF(length_scale=1.0)
# Create a Gaussian Process Regressor with the defined kernel
gauss_process = GaussianProcessRegressor(kernel=kernel, n_restarts_optimizer=10)
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.5, random_state=0)
# Fit the Gaussian Process model to the training data
gauss_process.fit(X_train, y_train)
# Make predictions on the test data
y_pred, sigma = gauss_process.predict(X_test, return_std=True)
# Visualize the results
x = np.linspace(0, 5, 1000)[:, np.newaxis]
y_mean, y_cov = gauss_process.predict(x, return_cov=True)
plt.figure(figsize=(10, 5))
plt.scatter(X_train, y_train, c='r', label='Training Data')
plt.scatter(X_test, y_test, c='g', label='Test Data')
plt.plot(x, y_mean, 'k', lw=2, zorder=9, label='Predicted Mean')
plt.fill_between(x[:, 0], y_mean - 1.96 * np.sqrt(np.diag(y_cov)), y_mean + 1.96 *np.sqrt(np.diag(y_cov)), alpha=0.1, color='g', label='95% Confidence Interval')
plt.xlabel('X')
plt.ylabel('y')
plt.legend()
plt.show()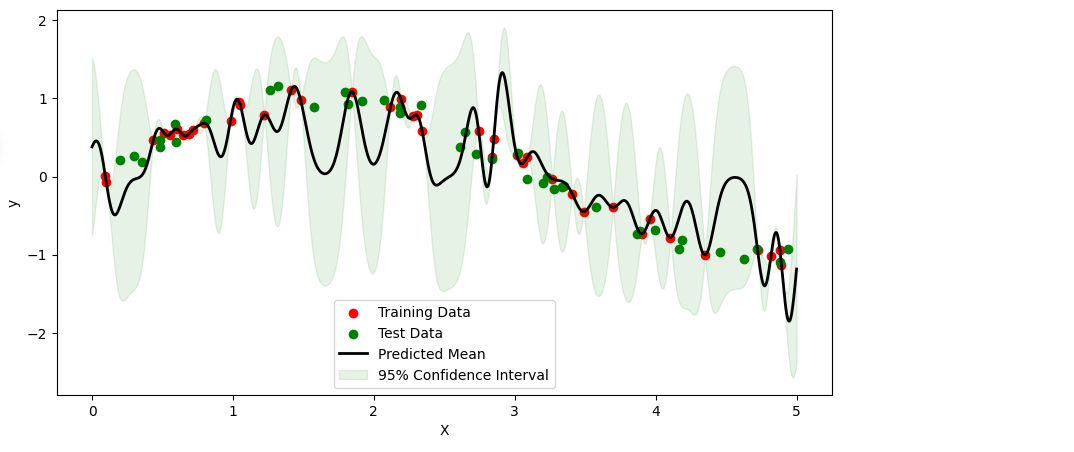
回归效果和预测图
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
作者已关闭评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号