AI批量下载网页中的mp3音频

AI批量下载网页中的mp3音频

AIGC部落
发布于 2025-01-19 20:02:17
发布于 2025-01-19 20:02:17
这个网页中有多个mp3音频 https://www.barefootbooks.com/talesofmystery
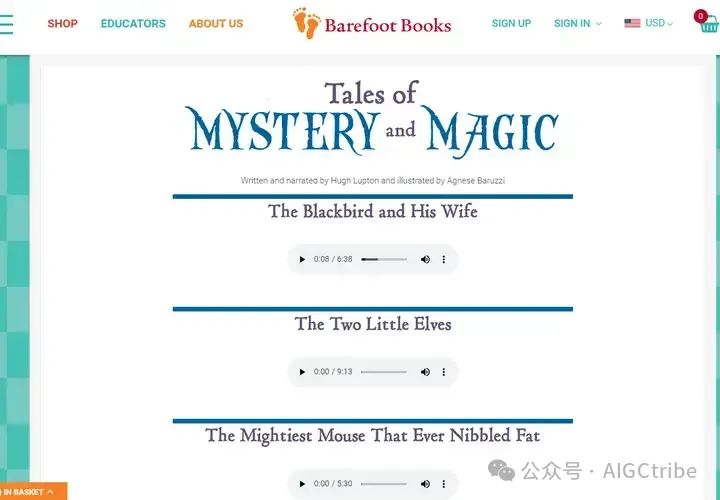
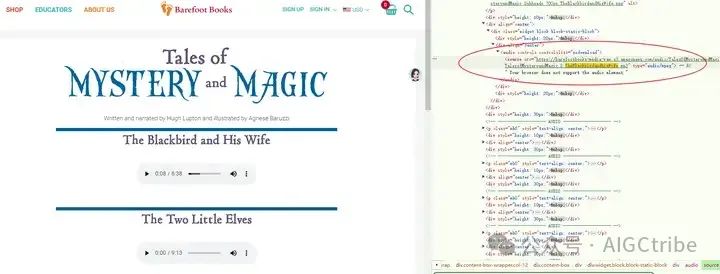
查看源代码,找到mp3文件:
https://barefootbooks-media-raw.s3.amazonaws.com/audio/TalesOfMysteryAndMagic/TalesofMysteryandMagic_2_TheBlackbirdandhisWife.mp3
<audio controls="" controlslist="nodownload">
<source src="https://barefootbooks-media-raw.s3.amazonaws.com/audio/TalesOfMysteryAndMagic/TalesofMysteryandMagic_2_TheBlackbirdandhisWife.mp3" type="audio/mpeg">
Your browser does not support the audio element.</audio>
在deepseek中输入提示词:
你是一个Python编程专家,写一个Python脚本,完成任务如下:
打开网页:https://www.barefootbooks.com/talesofmystery
定位源代码中所有audio标签,然后定位其中的<source >标签,提取其src属性,这是MP3下载链接;
下载所有的mp3音频,保存到文件夹:F:\aivideo
注意:每一步都要输出信息到屏幕上
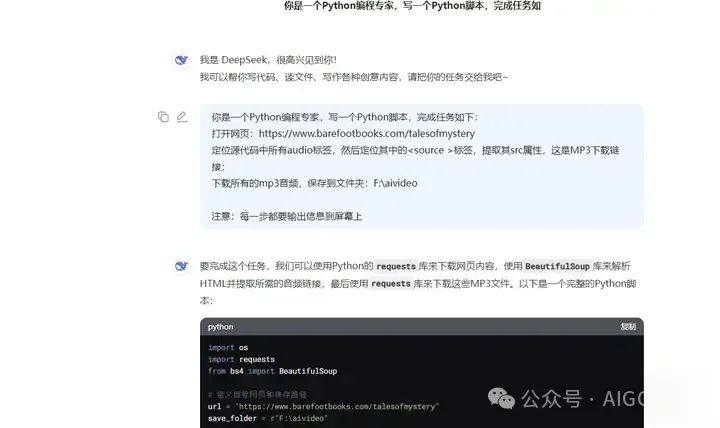
要完成这个任务,我们可以使用Python的requests库来下载网页内容,使用BeautifulSoup库来解析HTML并提取所需的音频链接,最后使用requests库来下载这些MP3文件。以下是一个完整的Python脚本:
import os
import requests
from bs4 import BeautifulSoup
# 定义目标网页和保存路径
url = "https://www.barefootbooks.com/talesofmystery"
save_folder = r"F:\aivideo"
# 确保保存文件夹存在
if not os.path.exists(save_folder):
os.makedirs(save_folder)
print(f"Created folder: {save_folder}")
# 下载网页内容
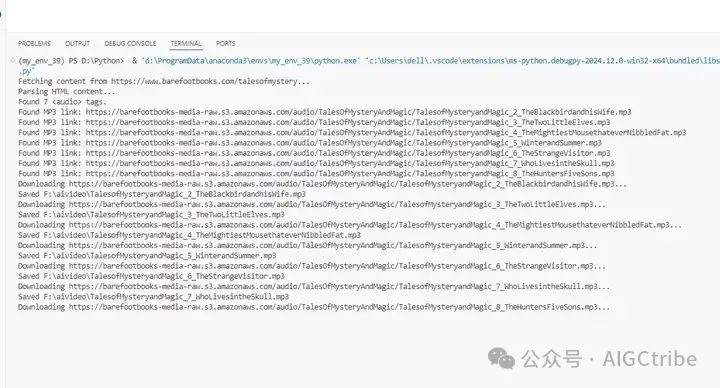
print(f"Fetching content from {url}...")
response = requests.get(url)
response.raise_for_status() # 检查请求是否成功
# 解析HTML内容
print("Parsing HTML content...")
soup = BeautifulSoup(response.text, 'html.parser')
# 查找所有的<audio>标签
audio_tags = soup.find_all('audio')
print(f"Found {len(audio_tags)} <audio> tags.")
# 遍历每个<audio>标签,查找其中的<source>标签并提取src属性
mp3_links = []
for audio in audio_tags:
source_tags = audio.find_all('source')
for source in source_tags:
src = source.get('src')
if src and src.endswith('.mp3'):
mp3_links.append(src)
print(f"Found MP3 link: {src}")
# 下载所有的MP3文件
for mp3_link in mp3_links:
print(f"Downloading {mp3_link}...")
mp3_response = requests.get(mp3_link)
mp3_response.raise_for_status()
# 提取文件名
file_name = os.path.join(save_folder, os.path.basename(mp3_link))
# 保存文件
with open(file_name, 'wb') as f:
f.write(mp3_response.content)
print(f"Saved {file_name}")
print("All MP3 files downloaded successfully.")
代码说明:
导入库:我们导入了os、requests和BeautifulSoup库。
定义目标网页和保存路径:url是目标网页的URL,save_folder是保存MP3文件的文件夹路径。
创建保存文件夹:如果文件夹不存在,我们使用os.makedirs创建它。
下载网页内容:使用requests.get下载网页内容,并检查请求是否成功。
解析HTML内容:使用BeautifulSoup解析HTML内容。
查找所有的<audio>标签:使用soup.find_all('audio')查找所有的<audio>标签。
提取MP3链接:遍历每个<audio>标签,查找其中的<source>标签,并提取src属性中的MP3链接。
下载MP3文件:遍历所有提取的MP3链接,使用requests.get下载文件,并保存到指定文件夹。
注意事项:
确保你已经安装了requests和BeautifulSoup库。如果没有安装,可以使用以下命令安装:
pip install requests beautifulsoup4
该脚本假设所有的MP3链接都是直接可访问的。如果链接需要身份验证或其他特殊处理,可能需要进一步调整脚本。
该脚本会覆盖文件夹中同名的MP3文件。如果需要避免覆盖,可以在保存文件时添加一些唯一的标识。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-01-18,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 Dance with GenAI 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号