实战:Stream流进阶案例集结,看看有哪些复杂的操作场景吧!
原创
实战:Stream流进阶案例集结,看看有哪些复杂的操作场景吧!
原创
小草飞上天
发布于 2025-01-20 22:28:53
发布于 2025-01-20 22:28:53
前言
JAVA中的Stream流是一种以声明的方式处理数据的工具,它的核心是将要处理的元素数据集合看做成一种流。
我们可以理解为这就是一个生产线,在一个生产线上可以对产品进行各种不同的操作,比如过滤掉不良的产品、对产品进行一些加工、包装产品等。
为什么会出现Stream流,直接用foreach遍历不行吗?
当然是可以的,但是foreach会存在一些问题,它属于外部遍历,在foreach里如果需要对原数据进行变更,则可能会出现异常,这是它的诟病。
所以Stream流的出现解决了这个问题,同时Stream流也大量采用Lambda模式进行数据操作。极大的简化了代码,让代码理加简洁。
今天我们就不简述Stream流的基础用法了,这里我们梳理几个实战案例,来了解一下Stream流的更复杂用法。
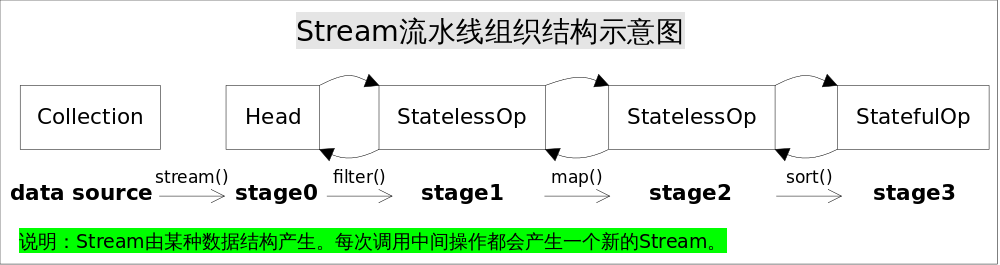
数组分割
我们以一个简单的数组分割方法,来简单介绍一下Stream的几个函数。
Stream.iterate(0, n -> n + 1): 这是一个无限流的生成器,从0开始,每次递增1。
limit(maxSize)将无限流限制为一个有限流,最多包含maxSize个元素。
parallel()转换为并行流
skip(a * splitSize) 跳过a * splitSize个元素。例如,当a=0时,跳过0个元素;a=1时,跳过splitSize个元素
这个方法的核心就是skip跳过前面已经分割的数据,然后开始limit截取后面的几位。这样来进行分割。
/**
* Description: 分割list集合
* @param list 集合数据
* @param splitSize 几个分割一组 2代表每2个数据为一组
* @return 集合分割后的集合
*/
public static <T> List<List<T>> splitList(List<T> list, int splitSize) {
//判断集合是否为空
if (CollectionUtils.isEmpty(list)) {
return Collections.emptyList();
}
//计算分割后的大小
int maxSize = (list.size() + splitSize - 1) / splitSize;
//开始分割
return Stream.iterate(0, n -> n + 1)
.limit(maxSize)
.parallel()
.map(a -> list.parallelStream().skip(a * splitSize).limit(splitSize).collect(Collectors.toList()))
.collect(Collectors.toList());
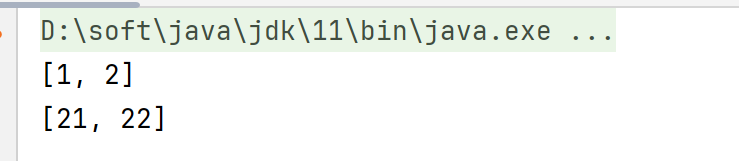
}使用demo,每2个分割成一组数据
public static void main(String[] args) {
List<Integer> list = Arrays.asList(1, 2,21,22);
int splitNum = 2;
List<List<Integer>> splitList = splitList(list, splitNum);
for (List<Integer> integers : splitList) {
System.out.println(integers);
}打印结果为:
多条件排序
在业务中,我们有时候需要对类中的多个条件排序,比如文章需要先按权重排序,再按发布时间排序等,像这种需要排序的例子很多,所以我们来说一下如何进行多字段排序。
我们直接来写一个例子,针对这个例子来说明代码逻辑:人员列表数据,需要先通过年龄排序,如果年龄相同的话按姓名排序.
我们简单梳理一下代码逻辑:
首先列表的定义咱就不说了哈。直接看stream流的操作。
1、通过sorted进行排序
2、Comparator.comparing创建一个比较器,第一个参数为:Function.identity() 代表原样数据输出类似于:v ->v 这样。第二个参数为二级比较器。
3、通过Comparator.comparing创建一个二级比较器,按age排序。然后通过thenComparing进行第二个参数排序。
这样就完成了多条件排序,
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Peoples {
private String name;
private Integer age;
}@Test
public void sorted() {
Peoples[] peoplesList = new Peoples[]{
new Peoples("A张三",16),
new Peoples("AB张三",1),
new Peoples("B张三",16),
new Peoples("BA张三",21),
new Peoples("CA张三",56),
new Peoples("C张三",33),
new Peoples("D张三",22),
new Peoples("D张三",15),
new Peoples("F张三",76),
};
List<Peoples> list = Arrays.asList(peoplesList);
list.stream().sorted(
Comparator.comparing(
Function.identity(),
Comparator.comparing(
Peoples::getAge,
(a,b) -> b - a
).thenComparing(Peoples::getName)
)
).forEach(System.out::println);
}合并两个数组
有时候我们需要对2个或者多个数组进行合并后在对合并后的数据进行stream流操作。
其实这里我主要是讲一下flatMap这个函数。这个函数很强大,在很多场景有用。
它的原理就是下面这张图所列的内容:将A1、A2两个不同的列表数据转换成一个同级的流数据。

接下来我们直接看例子,很简单
List<List<Integer>> objects = new ArrayList<>();
objects.add(Arrays.asList(1,2,3));
objects.add(Arrays.asList(4,5,6));
List<Integer> collect = objects.stream().flatMap(Collection::stream).collect(Collectors.toList());
System.out.println(collect);下面是打印结果,看结果我们很容易明白,这就是将两个数组合并到一个流中进行操作了。

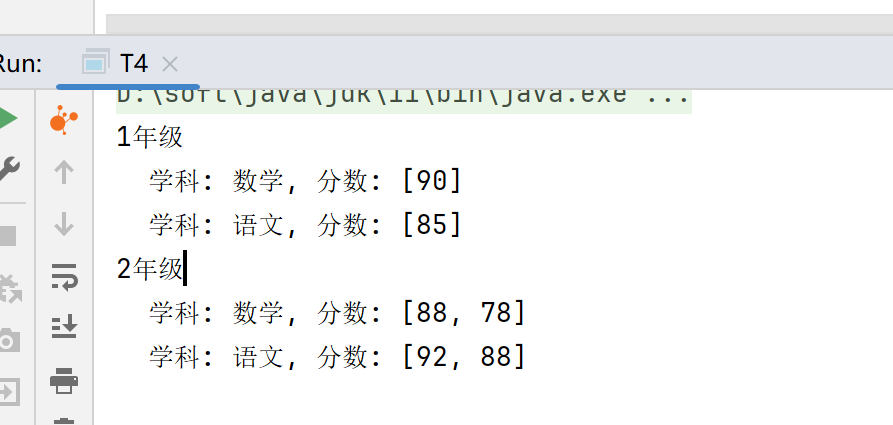
多级分组
我们看一下多级分组,在业务上我们经常会需要通过多字段进行数据的分组后,在进行处理数据。比如省市区的三级联动、部门人员的二级联动等。
这里我们以年级、科目、学生为例子,我们看看如何通过学生的学科成绩,来统计年级下学科的分数有哪些。
核心逻辑就是:通过年级分组再通过年级下的科目分组,统计出各科目的分数。
在这个案例中我们也着重在说一下Collectors.mapping这个函数,这个函数在实际中也经常用到,大家可以着重看一下。它的主要作用就是对流中的每个元素进行转换,并将转换完成的数据传递给下一个收集器。在这个例子中我们可以看到它将entry转换成了实际的score,并将score按list收集。
package com.demo;
import java.util.AbstractMap;
import java.util.Arrays;
import java.util.List;
import java.util.stream.Collectors;
import java.util.*;
import java.util.stream.Collectors;
class Student {
String name;
int grade; // 年级
List<CourseScore> scores;
Student(String name, int grade, List<CourseScore> scores) {
this.name = name;
this.grade = grade;
this.scores = scores;
}
}
class CourseScore {
String course;
int score;
CourseScore(String course, int score) {
this.course = course;
this.score = score;
}
}
public class T4 {
public static void main(String[] args) {
List<Student> students = Arrays.asList(
new Student("张三", 1, Arrays.asList(new CourseScore("数学", 90), new CourseScore("语文", 85))),
new Student("李四", 2, Arrays.asList(new CourseScore("数学", 88), new CourseScore("语文", 92))),
new Student("王五", 2, Arrays.asList(new CourseScore("数学", 78), new CourseScore("语文", 88)))
);
// 按年级和科目分组学生成绩
Map<Integer, Map<String, List<Integer>>> groupedScores = students.stream()
.flatMap(student -> student.scores.stream()
.map(score -> new AbstractMap.SimpleEntry<>(student.grade, score)))
.collect(Collectors.groupingBy(
entry -> entry.getKey(), // 按年级分组
Collectors.groupingBy(
entry -> entry.getValue().course, // 按科目分组
Collectors.mapping(entry -> entry.getValue().score, Collectors.toList()) // 收集成绩
)
));
// 输出结果
groupedScores.forEach((grade, courses) -> {
System.out.println(grade + "年级");
courses.forEach((course, scores) -> {
System.out.println(" 学科: " + course + ", 分数: " + scores);
});
});
}
}我们可以看到结果为:
总结
Stream流的操作让我们开发的代码更简洁。代码都是偏声明式的编码,能让开发者都能更清楚的知道代码书写的意图。而且在Stream流程的中间,不需要在关心其他的数据内容,只需要关心当下的数据状态即可。
本文总结的几个实战小案例,在业务开发中也是比较常用的,希望对大家有帮助。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号