字节跳动面试题-HashMap底层原理与HashTable的区别

字节跳动面试题-HashMap底层原理与HashTable的区别

GeekLiHua
发布于 2025-01-21 14:55:27
发布于 2025-01-21 14:55:27
字节跳动面试题-HashMap底层原理与HashTable的区别
HashMap底层原理解析
1. HashMap的基本概念
HashMap是一个基于哈希表的实现,它允许null键和null值,并且是无序的。它工作的原理是通过将键映射到值来存储和检索数据。在HashMap内部,通过使用哈希函数将键映射到存储桶中。
2. HashMap的数据结构
HashMap的底层数据结构主要包括数组和链表(或红黑树)。每个数组元素称为桶(bucket),每个桶存储了一个链表或者树结构,用于解决哈希冲突。
3. 哈希冲突的解决
当不同的键经过哈希函数映射到相同的桶时,就会发生哈希冲突。HashMap使用链表或红黑树来解决哈希冲突。在Java 8中,当链表长度超过阈值(默认为8)时,链表会转换成红黑树,以提高检索效率。
4. HashMap的关键方法
HashMap主要提供了以下几个核心方法:
put(key, value): 将指定的键值对存储到HashMap中。get(key): 根据键检索对应的值。remove(key): 根据键移除对应的键值对。
5. Java中HashMap的实现
下面是一个简单的HashMap实现示例:
import java.util.HashMap;
public class Main {
public static void main(String[] args) {
// 创建一个HashMap实例
HashMap<String, Integer> hashMap = new HashMap<>();
// 添加键值对
hashMap.put("apple", 10);
hashMap.put("banana", 20);
hashMap.put("orange", 30);
// 根据键获取值
int value = hashMap.get("apple");
System.out.println("Value for key 'apple': " + value);
// 删除键值对
hashMap.remove("banana");
// 打印HashMap的内容
System.out.println("HashMap after removal: " + hashMap);
}
}6. HashMap的内部工作流程
- 当调用
put(key, value)方法时,首先会计算键的哈希码。 - 根据哈希码计算桶的索引位置。
- 如果桶为空,则直接将键值对插入其中。
- 如果桶不为空,发生哈希冲突,则根据键的equals方法比较键的值:
- 如果存在相同的键,则更新对应的值。
- 如果不存在相同的键,则将键值对插入到链表的末尾或红黑树中。
- 当调用
get(key)方法时,会根据键的哈希码找到对应的桶,然后在链表或者红黑树中进行查找。
HashMap与HashTable的区别
1. 线程安全性
- HashMap是非线程安全的:HashMap不是同步的,即在多线程环境下不保证线程安全。
- HashTable是线程安全的:HashTable是同步的,它的方法都是synchronized的,能够在多线程环境下保证线程安全。
2. 性能
- HashMap通常比HashTable更快:由于HashTable的方法是同步的,因此在多线程环境下性能会受到影响。
- HashMap更适合单线程环境:在单线程环境下,HashMap的性能通常比HashTable更好,因为它不需要处理同步的开销。
3. null键值对的处理
- HashMap允许键和值为null:HashMap允许键和值为null,而HashTable不允许。
- HashTable不支持null键值:当尝试将null键或值放入HashTable时,会抛出NullPointerException。
4. 迭代器
- HashMap的迭代器是fail-fast的:如果在迭代期间修改了HashMap的结构(除了使用迭代器自身的remove方法),则会抛出ConcurrentModificationException。
- HashTable的迭代器不是fail-fast的:HashTable的Enumeration不抛出ConcurrentModificationException,因为它的方法都是同步的。
下面是一个示例代码,演示了HashMap和HashTable的迭代器特性以及fail-fast机制的区别:
import java.util.HashMap;
import java.util.Hashtable;
import java.util.Iterator;
import java.util.Map;
public class IteratorExample {
public static void main(String[] args) {
// 创建一个HashMap实例
HashMap<String, Integer> hashMap = new HashMap<>();
hashMap.put("one", 1);
hashMap.put("two", 2);
hashMap.put("three", 3);
// 创建一个Hashtable实例
Hashtable<String, Integer> hashtable = new Hashtable<>();
hashtable.put("one", 1);
hashtable.put("two", 2);
hashtable.put("three", 3);
// 使用HashMap的迭代器遍历
try {
Iterator<Map.Entry<String, Integer>> hashMapIterator = hashMap.entrySet().iterator();
while (hashMapIterator.hasNext()) {
Map.Entry<String, Integer> entry = hashMapIterator.next();
System.out.println("HashMap: " + entry.getKey() + " - " + entry.getValue());
// 修改HashMap的结构,将会抛出ConcurrentModificationException
hashMap.put("four", 4);
}
} catch (Exception e) {
System.out.println("HashMap 迭代器 fail-fast 特性触发: " + e);
}
// 使用Hashtable的迭代器遍历
Iterator<Map.Entry<String, Integer>> hashtableIterator = hashtable.entrySet().iterator();
while (hashtableIterator.hasNext()) {
Map.Entry<String, Integer> entry = hashtableIterator.next();
System.out.println("Hashtable: " + entry.getKey() + " - " + entry.getValue());
// 修改Hashtable的结构,不会抛出ConcurrentModificationException
hashtable.put("four", 4);
}
}
}- 当我使用HashMap的迭代器遍历时,当尝试在迭代期间修改HashMap的结构时,会抛出ConcurrentModificationException异常,这是由于HashMap的迭代器是fail-fast的特性导致的。
- 而当我使用Hashtable的迭代器遍历时,即使在迭代期间修改了Hashtable的结构,也不会抛出ConcurrentModificationException异常,这是因为Hashtable的迭代器不是fail-fast的特性。
5. 容量增长
- HashMap的容量可以动态增长:HashMap允许根据需要动态调整容量,以保持加载因子(默认为0.75)以下。
- HashTable的容量不会动态增长:HashTable的容量是固定的,当容量不足
import java.lang.reflect.Field;
import java.util.HashMap;
import java.util.Hashtable;
public class Main {
public static void main(String[] args) throws NoSuchFieldException, IllegalAccessException {
// 创建一个HashMap实例
HashMap<String, Integer> hashMap = new HashMap<>();
// 向HashMap中添加大量数据
for (int i = 0; i < 10000; i++) {
hashMap.put("key" + i, i);
}
// 创建一个Hashtable实例
Hashtable<String, Integer> hashtable = new Hashtable<>();
// 向Hashtable中添加大量数据
for (int i = 0; i < 10000; i++) {
hashtable.put("key" + i, i);
}
// 获取HashMap内部的容量信息
Field tableField = HashMap.class.getDeclaredField("table");
tableField.setAccessible(true);
Object[] table = (Object[]) tableField.get(hashMap);
// 输出HashMap和Hashtable的容量信息
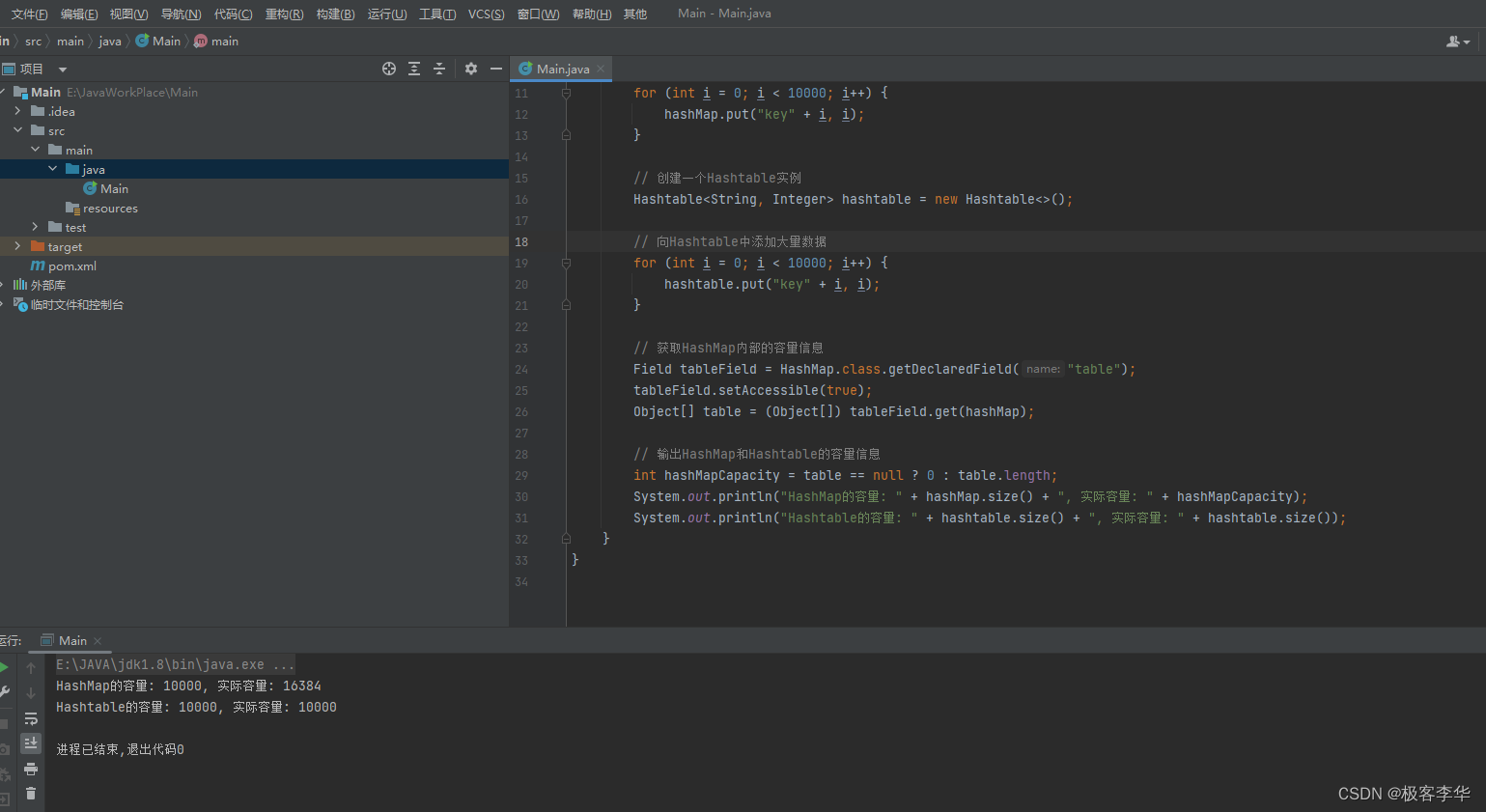
int hashMapCapacity = table == null ? 0 : table.length;
System.out.println("HashMap的容量: " + hashMap.size() + ", 实际容量: " + hashMapCapacity);
System.out.println("Hashtable的容量: " + hashtable.size() + ", 实际容量: " + hashtable.size());
}
}在上面的代码中,我创建了一个HashMap和一个Hashtable实例,并向它们分别添加了大量数据(10000条)。然后,我通过size()方法获取它们的大小,通过反射的方式获取它们的实际容量。
接下来,我解释一下代码中涉及到的重要概念:
- HashMap的容量增长:在向HashMap中不断添加键值对的过程中,当达到一定的负载因子(默认为0.75)时,HashMap会自动进行容量增长。这是为了保持HashMap的性能,在保持负载因子以下的情况下,减少哈希冲突的概率,提高检索效率。HashMap会以大约两倍的速度增长容量,以便尽量减少重新哈希的次数。
- Hashtable的固定容量:与HashMap不同,Hashtable的容量是固定的,不会动态增长。当添加新元素导致容量不足时,Hashtable会重新分配一个更大的存储空间,并将原有的键值对重新散列到新的存储空间中。这种方式效率较低,容易导致性能问题。
HashMap的应用场景
1. 缓存实现
HashMap可以用作缓存的实现,通过将键值对存储在HashMap中,可以快速地检索和访问缓存数据。例如,可以将最近访问的数据存储在HashMap中,以提高数据访问的速度。
HashMap<String, Object> cache = new HashMap<>();
// 将数据存储到缓存中
cache.put("key", data);
// 从缓存中获取数据
Object cachedData = cache.get("key");2. 数据索引
在需要快速查找和检索数据的场景中,HashMap是一个理想的数据结构。例如,在文本搜索引擎中,可以使用HashMap来存储文档索引,以快速查找包含特定关键字的文档。
HashMap<String, List<Document>> index = new HashMap<>();
// 将关键字和对应的文档列表存储到索引中
index.put("keyword", documents);
// 根据关键字快速获取文档列表
List<Document> matchedDocuments = index.get("keyword");3. 数据聚合与分组
在数据处理和分析领域,HashMap常常用于数据的聚合和分组。例如,在处理日志数据时,可以使用HashMap来按照不同的标签对数据进行分组统计。
HashMap<String, Integer> groupCounts = new HashMap<>();
// 遍历日志数据,按照不同的标签进行分组统计
for (LogEntry entry : logEntries) {
String label = entry.getLabel();
// 更新标签对应的计数
groupCounts.put(label, groupCounts.getOrDefault(label, 0) + 1);
}4. 缓存对象的快速检索
在对象关联性数据的管理中,HashMap可以用于快速检索对象。例如,在一个电子商务应用中,可以将商品ID映射到对应的商品对象,以便快速检索商品信息。
HashMap<String, Product> productMap = new HashMap<>();
// 将商品ID和对应的商品对象存储到HashMap中
productMap.put(product.getId(), product);
// 根据商品ID快速获取对应的商品对象
Product product = productMap.get(productId);5. 缓存管理
HashMap还可以用于管理系统中的配置信息、用户会话等数据。通过将这些数据存储在HashMap中,可以方便地进行管理和访问。
演示了如何使用HashMap来管理系统中的配置信息和用户会话数据:
import java.util.HashMap;
public class CacheManager {
// 创建一个HashMap实例用于存储配置信息
private HashMap<String, String> configMap = new HashMap<>();
// 创建一个HashMap实例用于存储用户会话数据
private HashMap<String, UserSession> sessionMap = new HashMap<>();
// 添加配置信息
public void addConfig(String key, String value) {
configMap.put(key, value);
}
// 获取配置信息
public String getConfig(String key) {
return configMap.get(key);
}
// 添加用户会话
public void addUserSession(String sessionId, UserSession session) {
sessionMap.put(sessionId, session);
}
// 获取用户会话
public UserSession getUserSession(String sessionId) {
return sessionMap.get(sessionId);
}
// 内部类,表示用户会话信息
private static class UserSession {
private String userId;
private long lastAccessTime;
public UserSession(String userId) {
this.userId = userId;
this.lastAccessTime = System.currentTimeMillis();
}
public String getUserId() {
return userId;
}
public long getLastAccessTime() {
return lastAccessTime;
}
}
public static void main(String[] args) {
CacheManager cacheManager = new CacheManager();
// 添加配置信息
cacheManager.addConfig("server.url", "http://example.com");
cacheManager.addConfig("server.port", "8080");
// 获取配置信息并打印
System.out.println("Server URL: " + cacheManager.getConfig("server.url"));
System.out.println("Server Port: " + cacheManager.getConfig("server.port"));
// 添加用户会话
UserSession session1 = new UserSession("user123");
cacheManager.addUserSession("session1", session1);
// 获取用户会话并打印
UserSession retrievedSession = cacheManager.getUserSession("session1");
if (retrievedSession != null) {
System.out.println("User ID: " + retrievedSession.getUserId());
System.out.println("Last Access Time: " + retrievedSession.getLastAccessTime());
}
}
}在这个示例代码中,我创建了一个 CacheManager 类,用于管理系统中的配置信息和用户会话数据。我使用了两个 HashMap 实例,一个用于存储配置信息 (configMap),另一个用于存储用户会话数据 (sessionMap)。我提供了方法来添加和获取配置信息,以及添加和获取用户会话数据。此外,我使用了一个内部类 UserSession 来表示用户会话信息。
HashMap优化和实践
1. 初始容量和加载因子
在创建HashMap时,可以指定初始容量和加载因子。初始容量是HashMap最初的容量大小,加载因子是HashMap在容量自动增加之前可以达到的负载因子。
通常情况下,应该根据预期的存储量和负载因子选择初始容量和加载因子,以避免HashMap频繁的扩容操作。
HashMap<String, Integer> map = new HashMap<>(16, 0.75f);2. 使用泛型
在定义HashMap时,应该尽量使用泛型来指定键和值的类型,以避免在编译时或运行时出现类型不匹配的错误。
HashMap<String, Integer> map = new HashMap<>();3. 考虑键的哈希性能
在实现自定义对象作为HashMap的键时,应该重写hashCode()和equals()方法,以确保对象的哈希码和相等性能满足HashMap的要求。否则可能导致哈希冲突或不正确的数据检索。
4. 使用迭代器遍历
在遍历HashMap时,应该优先使用迭代器进行遍历,以确保在遍历过程中不会修改HashMap的结构,避免ConcurrentModificationException异常。
HashMap<String, Integer> map = new HashMap<>();
Iterator<Map.Entry<String, Integer>> iterator = map.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<String, Integer> entry = iterator.next();
// 处理键值对
}5. 合理选择数据结构
在需要并发访问的场景下,应该考虑使用ConcurrentHashMap代替HashMap,以确保线程安全性。ConcurrentHashMap是Java提供的线程安全的HashMap实现。
下面是一个简单的示例代码,演示了在并发访问场景下如何使用 ConcurrentHashMap 替代 HashMap,以确保线程安全性:
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
public class ConcurrentExample {
public static void main(String[] args) {
// 使用 HashMap 存储数据的场景
Map<String, Integer> hashMap = new HashMap<>();
// 使用 ConcurrentHashMap 存储数据的场景
Map<String, Integer> concurrentHashMap = new ConcurrentHashMap<>();
// 创建并发访问的线程
Thread thread1 = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 1000; i++) {
// 向 HashMap 中添加数据
hashMap.put("key" + i, i);
// 向 ConcurrentHashMap 中添加数据
concurrentHashMap.put("key" + i, i);
}
}
});
Thread thread2 = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 1000; i++) {
// 向 HashMap 中添加数据
hashMap.put("key" + i, i);
// 向 ConcurrentHashMap 中添加数据
concurrentHashMap.put("key" + i, i);
}
}
});
// 启动线程
thread1.start();
thread2.start();
try {
// 等待线程执行完毕
thread1.join();
thread2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
// 输出 HashMap 和 ConcurrentHashMap 中的数据大小
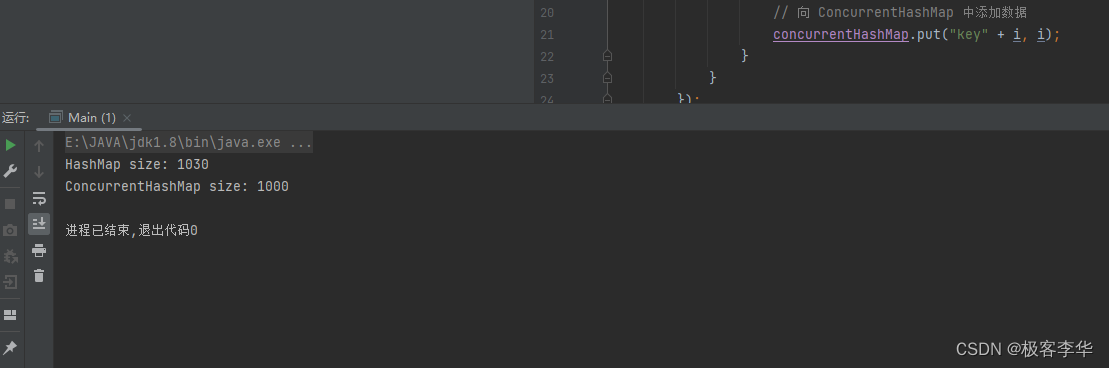
System.out.println("HashMap size: " + hashMap.size());
System.out.println("ConcurrentHashMap size: " + concurrentHashMap.size());
}
}在这个示例代码中,我创建了一个 HashMap 和一个 ConcurrentHashMap 实例,分别用于存储数据。然后,我创建了两个线程,每个线程分别向 HashMap 和 ConcurrentHashMap 中添加数据。最后,我通过输出两个集合中的数据大小来比较它们。
由于 HashMap 不是线程安全的,因此在多线程环境下使用可能会导致数据不一致或其他异常。而 ConcurrentHashMap 是线程安全的,它通过细粒度的锁和分段锁来保证线程安全性,因此在多线程环境下使用更为安全和高效。
在这里插入图片描述
虽然使用了两个线程向 HashMap 和 ConcurrentHashMap 中添加数据,但由于 HashMap 不是线程安全的,因此可能会发生竞态条件(race condition)和不一致的情况。
当多个线程同时向 HashMap 中添加元素时,由于 HashMap 不提供同步机制,可能会出现以下情况之一:
- 线程1和线程2同时尝试往同一个桶中添加元素,由于没有加锁,它们可能同时读取到相同的桶,然后同时尝试修改桶中的链表或树结构,导致数据丢失或者结构混乱。
- 两个线程同时尝试修改
HashMap的内部结构,比如扩容时,可能会导致其中一个线程的修改被覆盖或丢失。
这种情况在 ConcurrentHashMap 中是得到了有效的控制和处理的,因为它内部采用了分段锁机制,不同的段(Segment)拥有自己的锁,使得不同段的操作可以并发进行,从而提高了并发性能。
由于 HashMap 在并发访问时可能出现线程安全问题,所以可能会导致 HashMap 中的数据量看起来更大,因为可能有更多的元素没有被正确添加进去或被其他线程覆盖了,而 ConcurrentHashMap 在并发环境下更加安全,保证了数据的一致性和准确性。
当我启动了两个线程,每个线程向 HashMap 和 ConcurrentHashMap 中添加了1000个元素。然而,HashMap的size比ConcurrentHashMap要大。
这种差异可能是由于 HashMap 不是线程安全的,而 ConcurrentHashMap 是线程安全的。
在 HashMap 中,由于两个线程同时向 HashMap 中添加元素,可能会发生竞态条件(race condition)和不一致的情况。可能会出现以下情况之一:
- 由于线程之间竞争资源,可能会导致某些键值对被覆盖或丢失,但在某些情况下,它们可能仍然在HashMap中被计数。
- 在
HashMap内部,如果发生扩容,那么在扩容期间可能会出现不一致的情况,导致某些键值对在扩容完成之前被计数,但又被重新处理。 - 可能由于
HashMap的非线程安全性,在计算大小时可能存在一些并发问题。
而在 ConcurrentHashMap 中,由于其内部使用了线程安全的机制,因此在并发情况下添加元素时,不会出现竞态条件,且能够保证数据的一致性。
6. 避免频繁的扩容
频繁的扩容会影响HashMap的性能,因此在预估存储数据量时,应该合理选择初始容量和加载因子,以减少扩容操作的发生。 比如以下代码:
import java.util.HashMap;
public class Main<K, V> extends HashMap<K, V> {
// 重写size方法
@Override
public int size() {
return super.size();
}
// 计算容量的方法
public int capacity() {
return (int) (size() / loadFactor()) + 1;
}
// 负载因子
private float loadFactor() {
return 0.75f; // 默认负载因子
}
public static void main(String[] args) {
Main<String, Integer> customHashMap = new Main<>();
customHashMap.put("One", 1);
customHashMap.put("Two", 2);
customHashMap.put("Three", 3);
System.out.println("HashMap的大小: " + customHashMap.size());
System.out.println("HashMap的容量: " + customHashMap.capacity());
}
}本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-02-06,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号