DeepSeek R1模型全解析,90%的人都不知道的各版本区别(文末附免费流畅使用方法)

DeepSeek R1模型全解析,90%的人都不知道的各版本区别(文末附免费流畅使用方法)

AntDream
发布于 2025-02-07 15:28:09
发布于 2025-02-07 15:28:09
在AI领域,模型的迭代速度令人惊叹。
作为中国公司深度求索(DeepSeek)推出的智能助手,DeepSeek-R1系列模型凭借其强大的性能和广泛的应用场景,迅速成为行业焦点。
今天美国那边又有新的消息传来,据说是AI教母李飞飞团队只用不到50美元就训练出了媲美DeepSeek R1的AI推理模型。
DeepSeek的真正牛逼之处在于它给全世界提供了一种新的技术路径,就类似于春晚舞台上的宇树科技的机器人方案相对于波士顿动力的机器人方案,这是一种技术路线的创新,而且DeepSeek还是开源的。大写的牛!
后面会有很多类似的模型出现,来不断的在DeepSeek的启发下去超越DeepSeek这个前辈。
我们也当了一回前辈,哈哈。
然而,也由于太过火爆,DeepSeek官网已经几乎用不了,我一直在摸索能免费流畅使用DeepSeek的方式。
总结下来目前流畅使用DeepSeek的有2种方式:
方式一:API调用
利用DeepSeek的开放API的方式中转,包括本地部署、利用三方插件部署、利用智能体等。
优点是不卡,缺点是搞起来麻烦,关键API都是要钱的!
方式二:三方平台
因为DeepSeek是开源的,所以可以说只要有云资源的公司都能自己部署。
经过我的测试,截止目前还能流畅用的,而且还是免费用的,就剩下了2个:
- 国家超算中心,点击直达DeepSeek:https://chat.scnet.cn/#/home
- 红衣教主周鸿祎的纳米搜索,这个要下载App
国家超算中心这个目前也已经卡得不行了,而且用的还是最低的模型,效果也没那么好
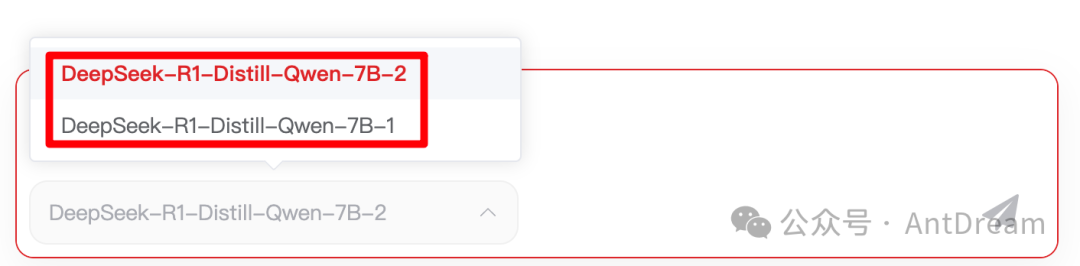
不得不说,目前为止,最靠谱的还是红衣教主的。不仅目前还稳定流畅运行,关键提供的免费的还是32B的模型:
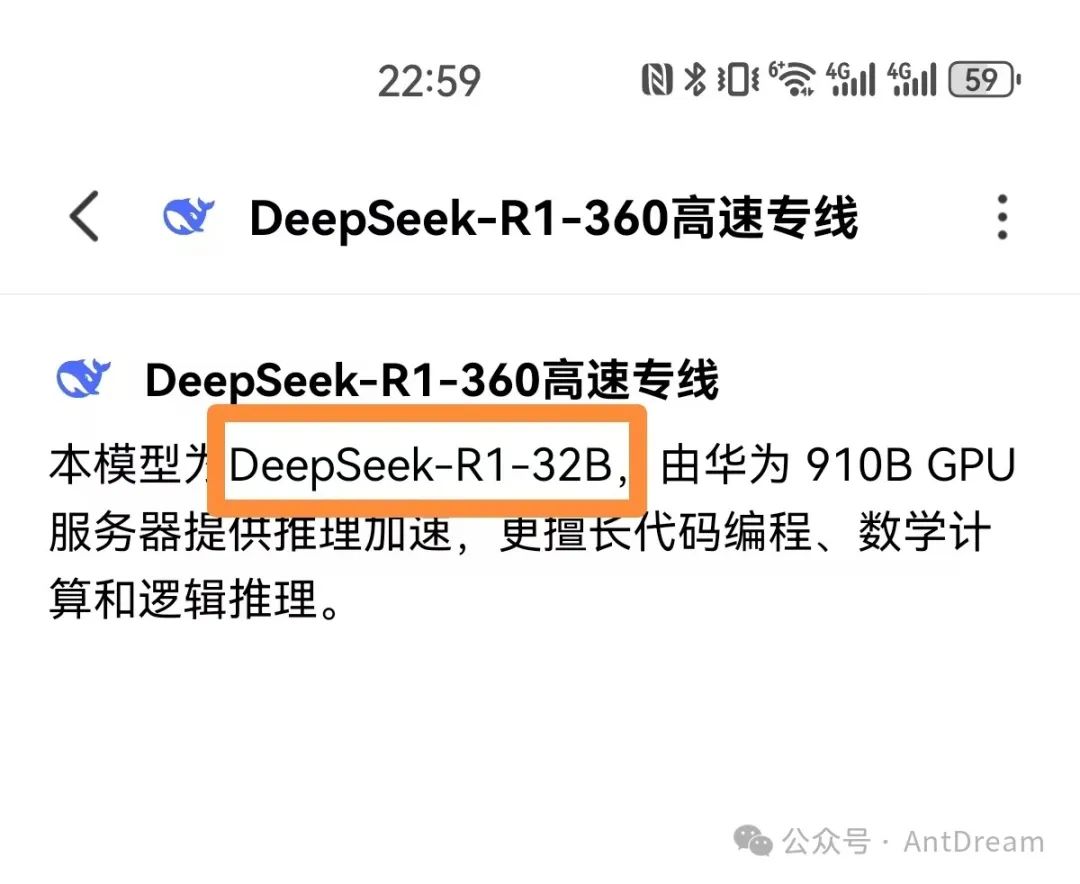
那这些不一样的R1模型有什么区别呢?这个32B、7B到底啥含义呢?
本着刨根问底的精神,我求助了DeepSeek自己,嘿嘿
我在DeepSeek的回答上做了补充,比如本地部署时电脑配置对应选什么模型等。
本文将从多个角度深入解析DeepSeek-R1系列模型的各个版本,帮助你全面了解它们的特点及适用场景。
一、DeepSeek-R1系列模型概述
DeepSeek-R1系列模型是基于Transformer架构的大型语言模型,支持中英文双语处理。该系列模型通过不断优化算法和增加训练数据,逐步提升了模型的性能和适用性。
目前,DeepSeek-R1系列已推出多个版本,包括但不限于:
- R1-35B
- R1-671B
- R1-13B
- R1-7B
每个版本的命名中的数字代表模型的参数量(以十亿为单位)。例如,“35B”表示该模型拥有350亿个参数。
二、各版本的核心区别
参数量与模型规模
参数量是衡量模型能力的重要指标。参数越多,模型通常越擅长处理复杂的任务,但也需要更多的计算资源。
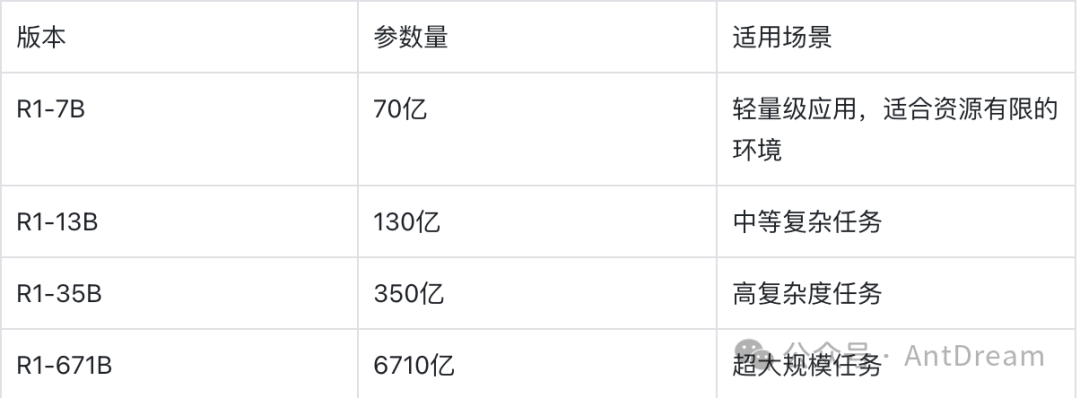
对比分析:
- R1-7B 是最轻量化的版本,适合移动设备或边缘计算场景。
- R1-13B 在性能和资源消耗之间找到了平衡,适合大多数企业级应用。
- R1-35B 和 R1-671B 则分别针对高复杂度和超大规模任务设计,适合云计算和高性能计算环境。
训练数据与优化方向
不同版本的R1模型在训练数据和优化方向上也有所不同。
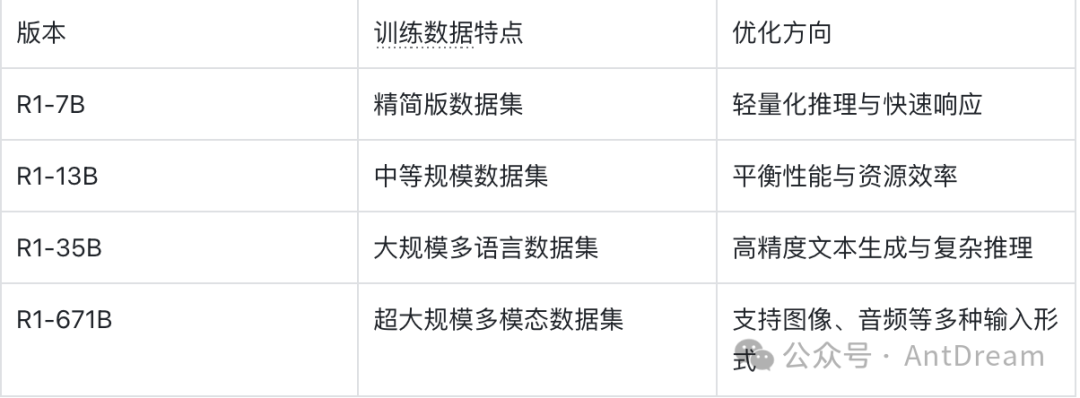
对比分析:
- R1-7B 的训练数据经过精简,专注于核心任务,适合对计算资源敏感的场景。
- R1-35B 和 R1-671B 则引入了更多样化的数据集,尤其是多模态数据(如图像、音频等),使其能够处理更复杂的任务。
性能与应用场景
不同版本的R1模型在实际应用中的表现也有显著差异。

对比分析:
- R1-7B 和 R1-13B 更适合对实时性要求较高的场景。
- R1-35B 和 R1-671B 则更适合需要高精度和复杂推理的任务。
硬件需求与成本
不同版本的R1模型对硬件的要求也不同,这直接影响了使用成本。
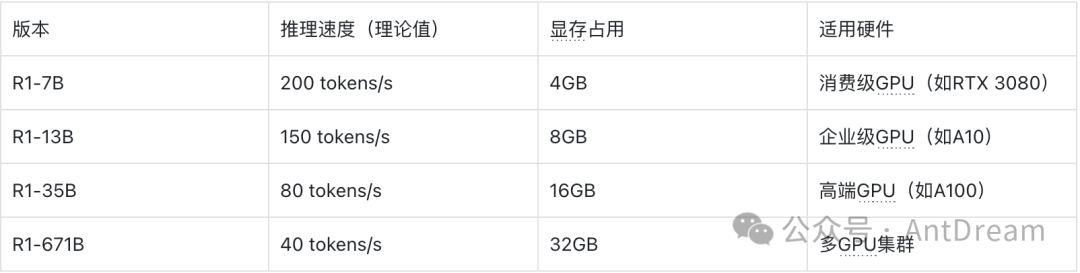
对比分析:
- R1-7B 对硬件要求最低,适合个人开发者或小企业。
- R1-671B 则需要高性能计算集群支持,适合大型企业或科研机构。
如果是要本地电脑部署,则可以参考下面的配置要求:
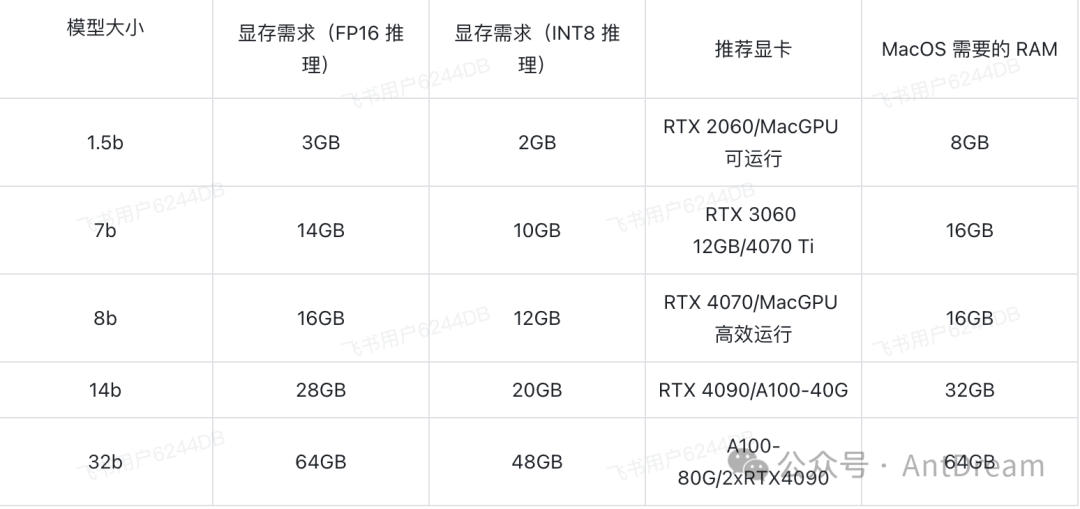
三、如何选择适合自己的DeepSeek-R1版本?
选择适合的R1版本需要综合考虑以下因素:
任务需求
- 如果你的任务是简单的文本生成或对话交互,可以选择 R1-7B 或 R1-13B。
- 如果需要处理复杂推理或多模态任务,则建议选择 R1-35B 或 R1-671B。
硬件资源
- 如果你的设备配置较低(如消费级GPU),请选择 R1-7B。
- 如果你拥有高性能计算集群,则可以考虑 R1-671B。
预算
- R1-7B 和 R1-13B 的使用成本较低,适合预算有限的用户。
- R1-35B 和 R1-671B 的成本较高,适合大型企业和科研机构。
四、总结
DeepSeek-R1系列模型通过不同的参数量和优化方向,为各种场景提供了灵活的选择。以下是各版本的核心特点总结:
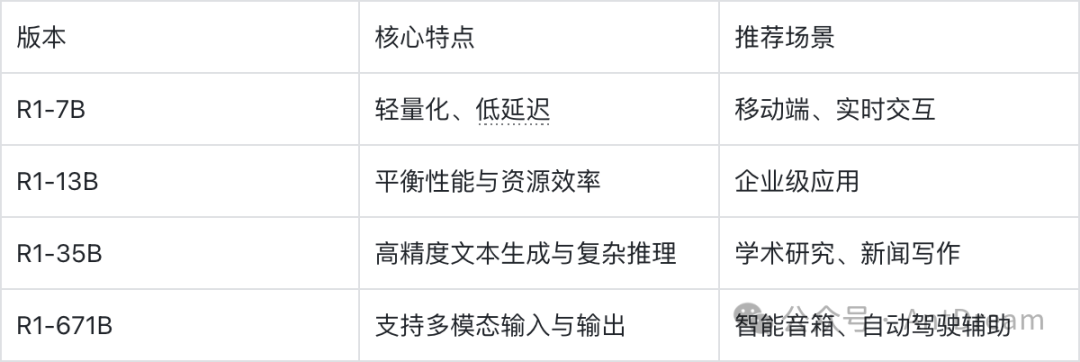
希望这篇文章能帮助你更好地理解DeepSeek-R1系列模型的各个版本,并找到最适合你的解决方案!
总结:所以我们一般用32B、35B这个级别的就已经够够的了。
同时,我也是在了解了这些参数的含义以后才知道啥是DeepSeek R1模型所谓的满血版本

有想体验满血版本的可以体验一下,反正是免费的。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-02-07,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号