XConn:CXL内存应用的带宽和时延

XConn:CXL内存应用的带宽和时延

数据存储前沿技术
发布于 2025-02-11 18:52:25
发布于 2025-02-11 18:52:25
关键要点
• CXL技术可实现内存池共享和扩展,提高内存利用率。
• CXL技术可用于数据库和AI推理等应用,提升性能并降低成本。
• XConn Technologies开发了CXL 2.0和PCIe 5.0交换机芯片,支持混合模式。
• CXL技术可解决“内存墙”问题,降低TCO。
• Samsung的CMM-B系统采用CXL 2.0规范,具有软件管理内存和高效能的特点。
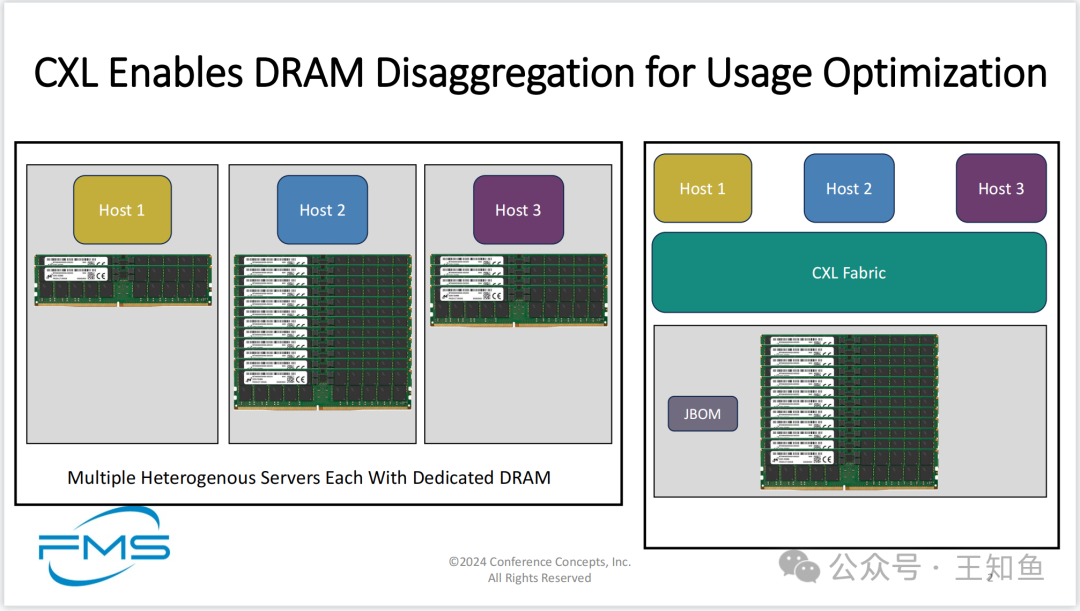
图展示了使用CXL(Compute Express Link)技术实现DRAM的解耦,以优化内存的使用。
- • 左侧展示的是传统的架构,每个主机(Host)有专属的DRAM配置,存在内存利用率低的问题。
- • 右侧则展示了通过CXL Fabric技术,将多台主机共享内存资源池(如“JBOM”),从而实现内存资源的共享和优化,提高整体的利用率。

用于可扩展解耦的CXL交换机
XConn Tech已开发CXL2.0(XC50256)和PCIe 5.0(XC51256)交换芯片
具有256条通道,总带宽为2048 GB/s
右侧特性:
- • 最低的端口到端口延迟
- • 最低的每端口功耗
- • 减小的PCB面积
- • 更低的总拥有成本(TCO)
底部特性:
- • 兼容CXL 1.1服务器处理器和CXL内存设备
- • 兼容即将推出的CXL 2.0处理器
- • 支持混合模式(CXL/PCIe混合)
CXL 应用场景
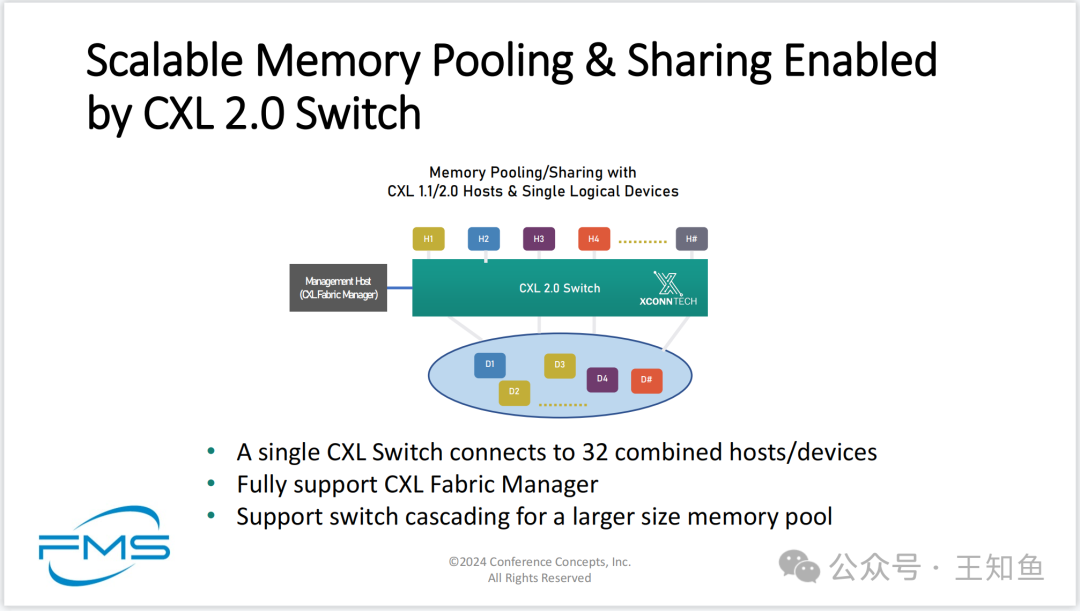
CXL 2.0交换机实现可扩展的内存池和共享
内存池/共享,适用于CXL 1.1/2.0主机和单一逻辑设备
图示:
多个主机(H1, H2, H3, H4, ... H#)连接到CXL 2.0交换机(XConnTech)
CXL 2.0交换机连接到一个设备池(D1, D2, D3, D4, ... D#)
管理主机(CXL Fabric Manager)
底部说明:
一个CXL交换机可连接32个主机/设备
完全支持CXL Fabric管理器
支持交换机级联,以扩展更大的内存池

内存池的应用
内存数据库
- • 数据库需要大量内存(高达100TB)以维持性能
- • 对于运行在多个主机上的数据库,共享内存是理想选择
- • CXL提供的加载/存储效率高于RDMA
- • 通过共享CXL内存,SAP-HANA性能显著提升(由三星展示于MemCon 2024)
人工智能推理
- • 推理过程需要更大的内存容量以维持性能
- • Xconn正在与合作伙伴合作,利用CXL内存增强推理性能
解决“内存墙”问题并降低总体拥有成本(TCO)
- • 通过CXL内存扩展/池化来应对“内存墙”问题
- • 多个主机共享大型内存池,同时保持本地内存的最小化
- • 重复利用来自被替换服务器的DRAM(如DDR4)

内存池/共享PoC拓扑结构
CXL Host 0和CXL Host 1通过CXL端口连接到CXL交换机
**管理主机(FM)通过PCIe端口和管理网络连接到CXL交换机
CXL交换机(XConn Tech品牌)具有多个端口,连接到不同的CXL内存扩展器
两个CXL内存扩展器通过CXL接口连接到交换机
I2C接口用于管理连接
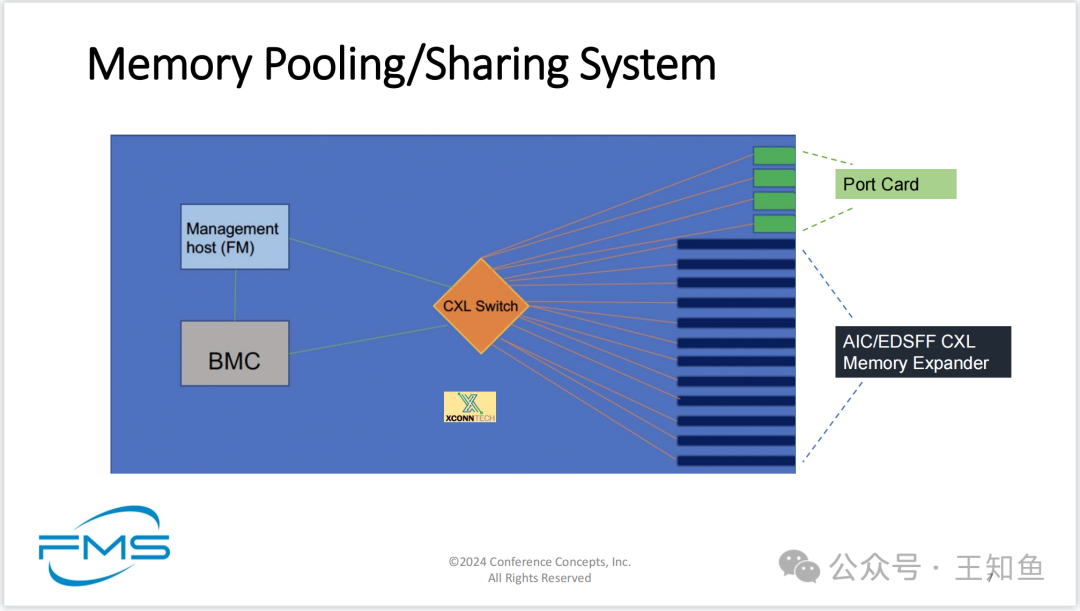
展示了一个CXL内存池和共享系统的结构。在该系统中,管理主机(FM)和BMC基板管理控制器共同控制和管理CXL交换机。CXL交换机连接到多个端口卡和AIC/EDSFF类型的CXL内存扩展器,通过这些扩展器提供大量共享内存资源。
Note:基于 CXL Switch 不仅可以扩展内存,还可以连接其他端口卡。
解决方案

图示 SuperMicro 和 Samsung 集成的内存池化设备
Samsung 的CMM-B设备特征如下:
- • 符合CXL 2.0规范的内存池
- • 可扩展至16TB
- • 通过Fabric管理器的软件管理内存
- • 高能效
- • 成本效益高
CXL 带宽
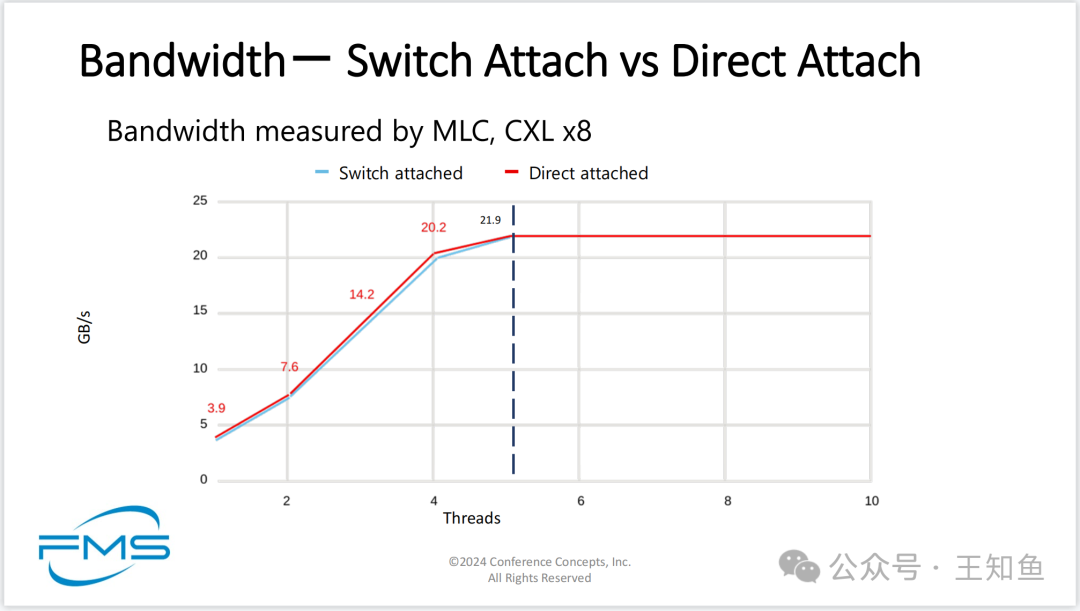
带宽比较:CXL 交换机内存 vs 直连内存
图比较了CXL交换机连接和直接连接两种方式下的带宽性能。
在多线程环境下,直连内存在5个线程时达到峰值带宽21.9 GB/s,而交换机连接方式虽然稍低于直接连接,但表现出相近的带宽能力并在增加线程后保持稳定。
此结果表明,尽管交换机连接方式的带宽略低于直接连接,但它能够在高线程环境下保持较好的性能,适合对多线程带宽需求高的应用场景。
Note:多线程下CXL内存带宽与直连内存带宽相近。
关于MLC测试工具
MLC(Memory Latency Checker) 是一款由英特尔(Intel)开发的工具,用于测量和评估系统的内存子系统性能。MLC专注于测试内存带宽和延迟,能够提供详细的内存访问延迟、带宽和多线程负载情况下的性能数据。其主要功能包括: 内存延迟测量:MLC可以精确地测量系统的内存访问延迟,包括本地内存和远程内存(NUMA架构中的非本地内存)之间的延迟差异。 内存带宽测量:工具可以测试系统在不同线程数下的内存带宽,适用于单线程和多线程场景,从而帮助用户了解在高并发情况下系统的内存性能。 多种内存访问模式:MLC支持不同的内存访问模式,包括读、写、读写混合等,使用户能够模拟实际应用的内存访问模式,评估系统的内存性能。 多核架构支持:MLC在多核、多插槽和NUMA架构中表现良好,能够测试不同内存节点之间的带宽和延迟情况,为优化多核处理器和内存架构提供数据支持。

图展示了在不同的读取/写入(R/W)比例下,CXL交换机连接模式下的最大带宽表现。
结果表明,随着写入操作比例的增加,带宽逐渐增大,1:1的读取/写入比例(即读写均衡)达到了最高带宽约50,000 MB/秒。
这表明CXL交换机连接在混合读写操作的情况下具有较好的带宽表现,适合需要高读写性能的应用场景。
CXL 时延
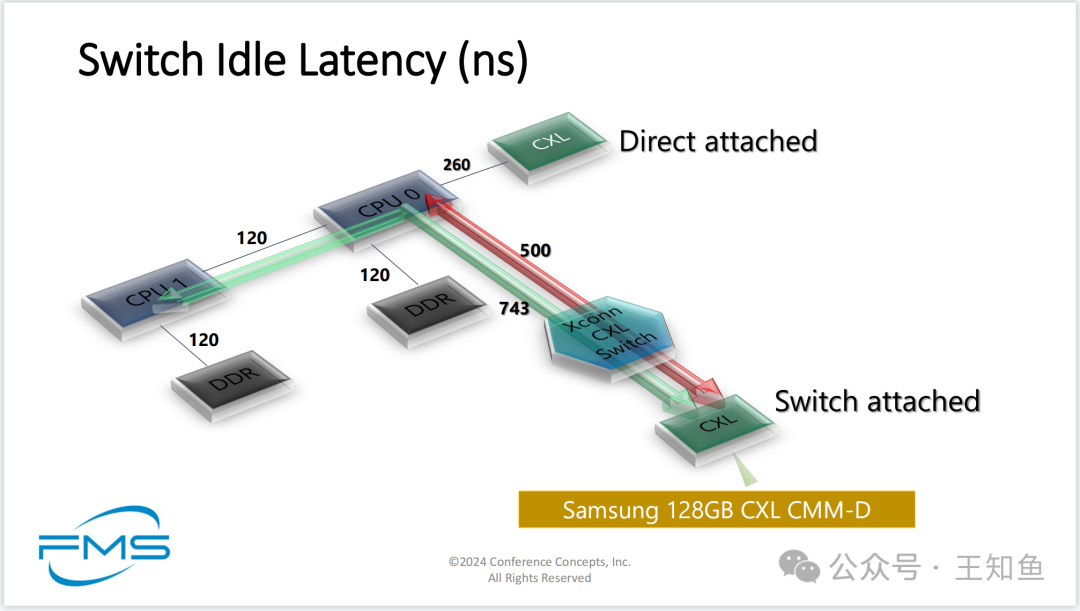
前面讨论直连内存和CXL交换内存的带宽比较,两者在多线程场景带宽峰值相近;与100%读IO相比,读写混合业务场景CXL 内存带宽表现更好。
CXL 内存访问时延
与NUMA跨节点访存时延模型相似,
- • 直连内存的时延最低
- • 其次是跨CPU的内存访问
- • 其次的CXL直连内存单元
- • CXL池化内存时延最高
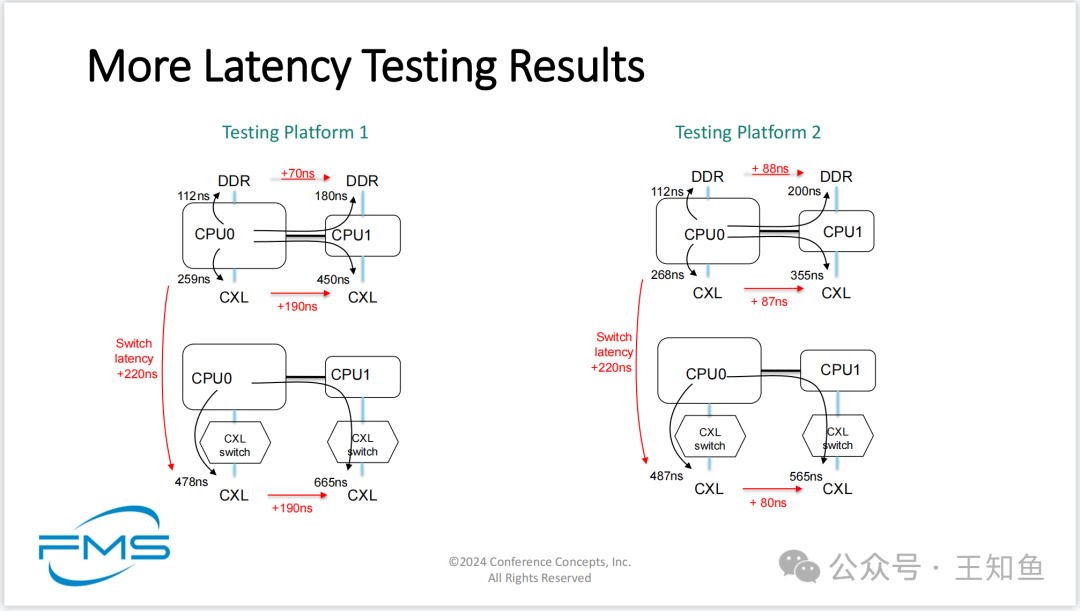
更多 CXL 内存访问时延数据
左右是在两个平台上的CXL内存访问时延测试数据,平台2(右图)较平台1跨节点CXL访存时延要低,这可能是得益于CPU之间的通信优化。
基本可以得出以下结论:
1. 直连CXL访存时延是直连内存的2倍;
2. 跨节点访问直连CXL内存是直连内存时延的3倍;
3. CXL池化内存的访问时延是直连内存的4倍;
4. 跨节点访问CXL池化内存是直连内存时延的6倍;
总结

- • CXL交换机支持的内存池提供了解决“内存墙”问题的方案,适用于AI和高性能计算(HPC)。
- • 软件支持的内存共享在数据库和AI推理应用中有广泛用途。
- • XConn的CXL 2.0交换机和Fabric管理器(FM)提供了一个可扩展且可组合的内存池/共享解决方案,性能良好。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-11-14,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号