强化学习算法解析:PPO(Proximal Policy Optimization)

强化学习算法解析:PPO(Proximal Policy Optimization)

jack.yang
发布于 2025-04-05 11:08:32
发布于 2025-04-05 11:08:32
PPO(近端策略优化)是OpenAI于2017年提出的一种策略梯度类算法,以其高效性、稳定性和易实现性成为强化学习领域的主流算法。以下从核心原理、数学推导、代码实现到应用场景进行系统解析。
一、PPO 的核心设计思想
- 问题背景
传统策略梯度方法(如TRPO)存在两大痛点:
- 更新步长敏感:步长过大易导致策略崩溃,步长过小则收敛缓慢;
- 样本利用率低:需大量环境交互数据。
- PPO 的解决方案
- Clipped Surrogate Objective:通过限制策略更新的幅度,确保新策略与旧策略的差异在可控范围内;
- 重要性采样(Importance Sampling):复用旧策略采集的数据,提升样本效率;
- 自适应惩罚项:替代TRPO的复杂约束优化,降低计算成本。
二、数学原理与目标函数- 策略梯度基础
策略梯度目标函数为:
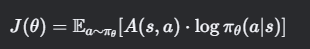
其中
PPO 的目标函数引入重要性采样比

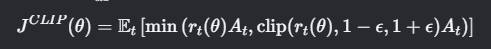
- Clip 机制:限制
- 双重目标:取最小值确保优化方向保守,避免过度偏离旧策略。
- 优势估计技术 常用 GAE(Generalized Advantage Estimation) 计算优势值:
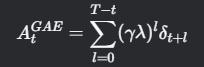
其中

三、算法流程与伪代码
# PPO 算法伪代码(Actor-Critic 架构)
for epoch in 1, 2, ...:
# 1. 收集数据
for t in 1, 2, ..., T:
使用当前策略 π_θ_old 与环境交互,存储 {s_t, a_t, r_t, log_prob_t}
# 2. 计算优势与回报
计算每个时间步的优势值 A_t 和回报 G_t
# 3. 优化策略
for k in 1, 2, ..., K:
随机采样一个 batch 数据
计算重要性采样比 r_t(θ) = exp(log_prob_new - log_prob_old)
计算 clipped 目标函数 J^CLIP
更新策略网络参数 θ 以最大化 J^CLIP
更新价值网络参数 φ 以最小化 (V_φ(s_t) - G_t)^2四、关键超参数与调优策略

五、应用场景与性能对比
- 典型应用
- 游戏AI:OpenAI Five(Dota 2)、AlphaStar(星际争霸Ⅱ)
- 机器人控制:波士顿动力 Atlas 机器人步态优化
- 自然语言处理:ChatGPT 的策略优化阶段
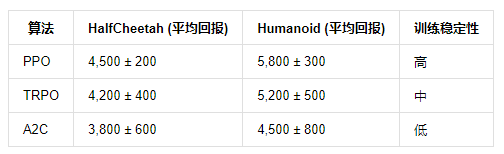
- 基准测试对比 在 MuJoCo 连续控制任务中,PPO 的性能显著优于传统算法:
六、PyTorch 实现核心代码
import torch
import torch.optim as optim
from torch.distributions import Categorical
class PPO:
def __init__(self, actor_critic, clip_param=0.2, lr=3e-4, ent_coef=0.01):
self.actor_critic = actor_critic
self.optimizer = optim.Adam(actor_critic.parameters(), lr=lr)
self.clip_param = clip_param
self.ent_coef = ent_coef # 熵正则化系数
def update(self, rollouts):
obs, actions, old_log_probs, returns, advantages = rollouts.sample()
# 计算新策略的概率和熵
dist, values = self.actor_critic(obs)
new_log_probs = dist.log_prob(actions)
entropy = dist.entropy().mean()
# 重要性采样比
ratio = (new_log_probs - old_log_probs).exp()
surr1 = ratio * advantages
surr2 = torch.clamp(ratio, 1 - self.clip_param, 1 + self.clip_param) * advantages
policy_loss = -torch.min(surr1, surr2).mean()
# 价值函数损失
value_loss = 0.5 * (returns - values).pow(2).mean()
# 总损失(含熵正则化)
loss = policy_loss + value_loss - self.ent_coef * entropy
# 梯度更新
self.optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(self.actor_critic.parameters(), 0.5)
self.optimizer.step()七、局限性与改进方向
- 固有缺陷
- 局部最优陷阱:Clip机制可能限制探索能力;
- 高维动作空间:对连续控制任务需精细调整熵系数。
- 前沿改进
- PPO-Adaptive:动态调整Clip范围 ε;
- POP(Phasic Policy Gradient):解耦策略与价值函数更新频率;
- 结合元学习:实现跨任务快速适应(如 Meta-PPO)。
总结
PPO 通过创新的目标函数设计和工程优化,在保持策略梯度方法理论优势的同时大幅提升实用价值。其核心在于平衡样本效率、训练稳定性与实现复杂度,成为工业级强化学习应用的首选算法。未来,与离线强化学习、多智能体系统的结合将拓展其应用边界。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-04-02,如有侵权请联系 cloudcommunity@tencent.com 删除
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号