MCP(Model Context Protocol)全链路追踪:调用链监控技术剖析
原创
MCP(Model Context Protocol)全链路追踪:调用链监控技术剖析
原创
二一年冬末
修改于 2025-05-04 19:22:27
修改于 2025-05-04 19:22:27
在微服务架构日益普及的今天,分布式系统的复杂性给开发者带来了前所未有的挑战。一个简单的用户请求,可能在后端触发几十个服务的协同工作。当系统出现性能瓶颈或故障时,传统的日志和监控手段往往显得捉襟见肘。我们迫切需要一种能够贯穿整个调用链的监控技术,这就是 MCP(Model Context Protocol)全链路追踪的核心价值。
一、项目背景
I. 从单体应用到微服务的演进
所有功能模块都部署在一个应用中,代码仓库、数据库、部署单元都是统一的。这种架构的优势是开发和部署简单,团队协作高效。
但随着业务的爆发式增长,单体应用的弊端逐渐显现:
单体应用弊端 | 具体表现 |
|---|---|
扩展性差 | 无法对高负载模块单独扩展,只能整体扩展。 |
部署困难 | 任何小改动都需要重新部署整个应用。 |
技术债务累积 | 各模块代码相互依赖,重构难度大。 |
故障影响范围广 | 一个模块的故障可能导致整个系统崩溃。 |
为了解决这些问题,将系统拆分为多个独立服务,每个服务专注于一个业务功能,拥有独立的代码库、数据库和部署流程。
II. 微服务架构下的新挑战
微服务架构虽然解决了单体应用的扩展性问题,但也引入了新的复杂性:
微服务挑战 | 具体表现 |
|---|---|
服务间通信复杂 | 服务间调用链路长,涉及多种通信协议。 |
分布式事务管理 | 跨服务事务一致性难以保证。 |
故障定位困难 | 故障可能发生在多个服务中,日志分散。 |
性能监控不全面 | 传统监控工具无法跟踪完整的调用链路。 |
在这样的背景下,我们启动了 MCP 全链路追踪项目,旨在为微服务架构提供完整的调用链监控解决方案。
二、全链路追踪的核心概念
1.1 什么是全链路追踪
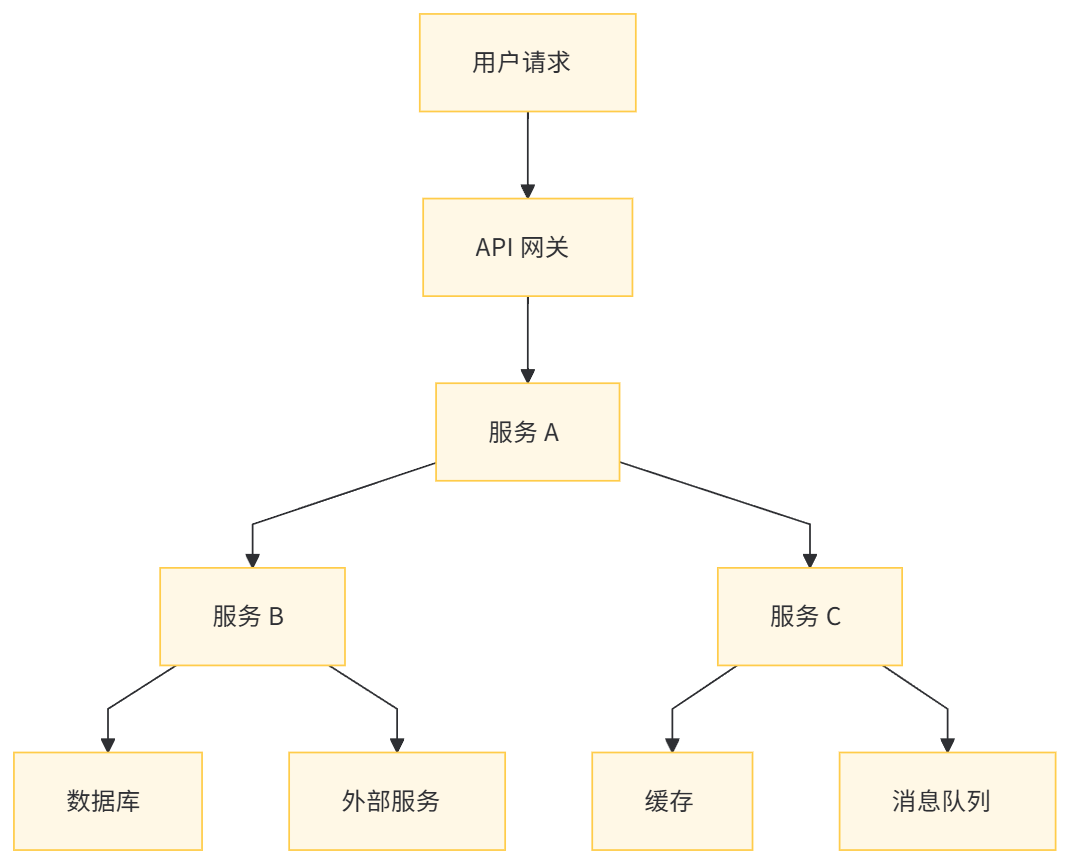
全链路追踪(Distributed Tracing)是一种监控技术,用于记录分布式系统中一个完整业务请求的调用路径。它通过为每个请求分配一个全局唯一的追踪 ID(Trace ID),将各个服务的子请求串联起来,形成完整的调用链路。
1.2 核心组件
- Trace(追踪):代表一个完整的业务请求及其所有子调用。
- Span(跨度):表示调用链中的一个独立操作,包含操作名称、开始时间、结束时间、状态等信息。
- Annotation(注解):用于记录调用过程中的关键事件,如请求发送、响应接收等。
- Trace Context(追踪上下文):包含 Trace ID、Span ID 等信息,用于在服务间传递追踪状态。
1.3 工作原理
当一个请求进入系统时,API 网关为其生成一个唯一的 Trace ID。每个服务在处理请求时,都会创建一个或多个 Span,并将 Trace ID 和当前 Span ID 作为上下文传递给下游服务。下游服务根据接收到的上下文,创建新的 Span 并关联到同一个 Trace 中。
1.4 参考论文
- Dapper, a Large-Scale Distributed Systems Tracing Infrastructure(Google,2010)
- 提出了分布式追踪的基本模型和核心概念。
- 设计了基于概率采样的追踪数据采集策略。
- 提供了高效的追踪数据存储和查询方法。
- Zipkin: a Distributed Tracking System(Twitter,2012)
- 详细介绍了 Zipkin 系统的架构和实现。
- 提出了基于时间戳和依赖关系的调用链路可视化方法。
- 讨论了高并发场景下的追踪数据采样和存储优化。
三、MCP 全链路追踪架构设计
3.1 系统模块划分
MCP 全链路追踪系统由以下几个核心模块组成:
模块名称 | 功能描述 | 关键技术 |
|---|---|---|
追踪客户端 | 负责在服务中生成和传播追踪上下文,记录 Span 信息。 | 基于 OpenTelemetry 标准,支持多种编程语言。 |
数据采集器 | 收集各服务生成的追踪数据,并进行预处理。 | 使用 gRPC 或 HTTP 协议接收数据,支持数据压缩和批量处理。 |
数据存储 | 存储处理后的追踪数据,支持快速查询和分析。 | 基于 Elasticsearch 或 ClickHouse,优化查询性能。 |
分析引擎 | 提供调用链路分析、性能诊断和异常检测功能。 | 使用机器学习算法分析调用模式,识别性能瓶颈。 |
可视化界面 | 展示调用链路拓扑、性能指标和故障信息。 | 基于 Grafana 或定制化前端,支持交互式查询和导出。 |
3.2 数据模型设计
MCP 采用层次化的数据模型,Trace 作为根节点,包含多个 Span。每个 Span 记录了调用的详细信息,包括时间戳、状态码、标签等。
{
"traceId": "7bf9e9b0d1a2469e93e2249f9b3e195",
"spans": [
{
"spanId": "1",
"parentSpanId": null,
"operationName": "API Gateway",
"startTime": "2023-10-01T10:00:00.000Z",
"endTime": "2023-10-01T10:00:01.200Z",
"status": "OK",
"tags": {
"http.method": "GET",
"http.url": "/api/v1/orders",
"client.ip": "192.168.1.100"
}
},
{
"spanId": "2",
"parentSpanId": "1",
"operationName": "Service A:FetchOrder",
"startTime": "2023-10-01T10:00:01.000Z",
"endTime": "2023-10-01T10:00:01.150Z",
"status": "OK",
"tags": {
"db.query": "SELECT * FROM orders WHERE id = ?",
"peer.service": "Service A"
}
},
{
"spanId": "3",
"parentSpanId": "1",
"operationName": "Service B:CheckInventory",
"startTime": "2023-10-01T10:00:01.050Z",
"endTime": "2023-10-01T10:00:01.180Z",
"status": "OK",
"tags": {
"cache.key": "inventory:product:123",
"peer.service": "Service B"
}
}
]
}3.3 采样策略
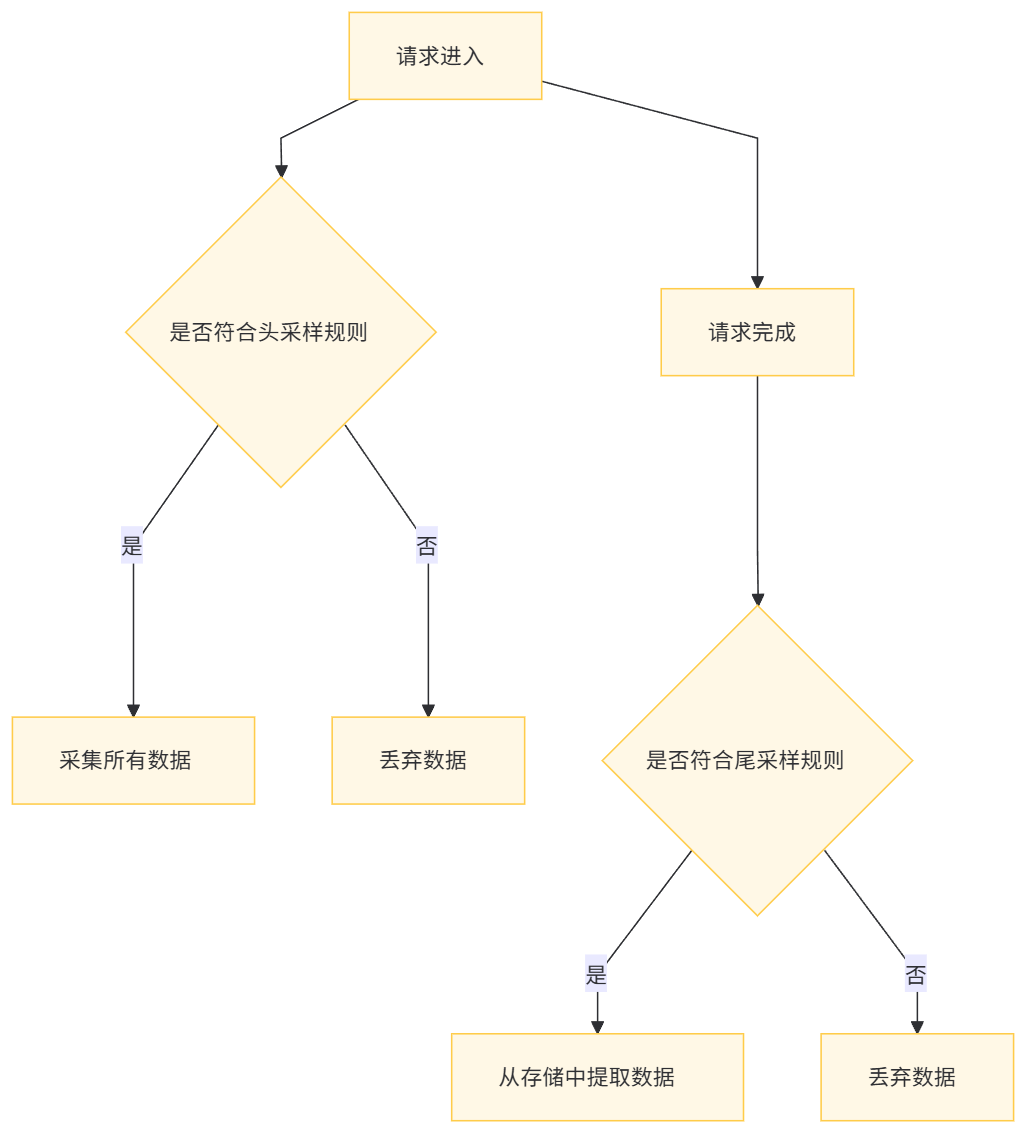
为了平衡数据采集的全面性和系统性能,MCP 实现了多种采样策略:
- 头采样(Head-based Sampling):在请求进入系统时,根据预设规则决定是否采样。
- 尾采样(Tail-based Sampling):在请求完成后再决定是否采样,可以根据整个调用链的特征(如响应时间、错误状态)进行决策。
四、追踪客户端实现
4.1 代码示例(Java)
在 Java 服务中,我们使用 OpenTelemetry SDK 实现追踪客户端。以下是一个简单的示例:
import io.opentelemetry.api.GlobalOpenTelemetry;
import io.opentelemetry.api.trace.Span;
import io.opentelemetry.api.trace.Tracer;
import io.opentelemetry.context.Context;
public class TracingExample {
private static final Tracer TRACER = GlobalOpenTelemetry.getTracer("com.example.tracing");
public void handleRequest(Request request) {
// 创建一个新的 Span,自动从上下文中获取 Trace ID
Span parentSpan = TRACER.spanBuilder("API Gateway")
.startSpan();
try (Context context = parentSpan.makeCurrent()) {
// 调用下游服务
callServiceA(request);
callServiceB(request);
} finally {
parentSpan.end();
}
}
public void callServiceA(Request request) {
Span span = TRACER.spanBuilder("Service A:FetchOrder")
.setParent(Context.current())
.startSpan();
try (Context context = span.makeCurrent()) {
// 模拟网络调用
simulateNetworkCall();
} finally {
span.end();
}
}
public void callServiceB(Request request) {
Span span = TRACER.spanBuilder("Service B:CheckInventory")
.setParent(Context.current())
.startSpan();
try (Context context = span.makeCurrent()) {
// 模拟网络调用
simulateNetworkCall();
} finally {
span.end();
}
}
private void simulateNetworkCall() {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
}4.2 代码示例(Python)
在 Python 服务中,我们同样使用 OpenTelemetry 库:
from opentelemetry import trace
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import (
ConsoleSpanExporter,
SimpleSpanProcessor,
)
# 初始化追踪器
trace.set_tracer_provider(TracerProvider())
tracer_provider = trace.get_tracer_provider()
tracer_provider.add_span_processor(SimpleSpanProcessor(ConsoleSpanExporter()))
tracer = trace.get_tracer(__name__)
def handle_request(request):
# 创建一个新的 Span
with tracer.start_as_current_span("API Gateway") as parent_span:
parent_span.set_attribute("http.method", request.method)
parent_span.set_attribute("http.url", request.url)
# 调用下游服务
call_service_a(request)
call_service_b(request)
def call_service_a(request):
with tracer.start_as_current_span("Service A:FetchOrder") as span:
span.set_attribute("db.query", "SELECT * FROM orders WHERE id = ?")
span.set_attribute("peer.service", "Service A")
# 模拟网络调用
simulate_network_call()
def call_service_b(request):
with tracer.start_as_current_span("Service B:CheckInventory") as span:
span.set_attribute("cache.key", "inventory:product:123")
span.set_attribute("peer.service", "Service B")
# 模拟网络调用
simulate_network_call()
def simulate_network_call():
import time
time.sleep(0.1)4.3 代码解释
- 追踪上下文传播:通过
makeCurrent()方法将当前 Span 设置为上下文的一部分,确保下游服务能够获取到正确的 Trace ID。 - Span 的生命周期管理:使用
try-with-resources(Java)或with语句(Python)自动管理 Span 的开始和结束。 - 标签和属性:为 Span 添加描述性信息(如 HTTP 方法、数据库查询语句),便于后续分析和查询。
五、数据采集与存储
5.1 数据采集器实现
MCP 数据采集器使用 gRPC 协议接收追踪数据,并进行预处理:
// 定义追踪数据采集服务
service CollectorService {
rpc Export (ExportRequest) returns (ExportResponse) {}
}
// 定义导出请求消息
message ExportRequest {
repeated Span spans = 1;
}
// 定义导出响应消息
message ExportResponse {
bool success = 1;
}
// 定义 Span 消息
message Span {
string trace_id = 1;
string span_id = 2;
string parent_span_id = 3;
string operation_name = 4;
int64 start_time_unix_nano = 5;
int64 end_time_unix_nano = 6;
map<string, string> tags = 7;
string status = 8;
}5.2 数据存储优化
为了高效存储和查询追踪数据,MCP 采用以下策略:
- 数据分片:按照 Trace ID 进行哈希分片,确保数据均匀分布。
- 索引优化:为关键查询字段(如服务名称、操作名称、时间范围)建立索引。
- 数据生命周期管理:设置数据保留策略,定期清理过期数据。
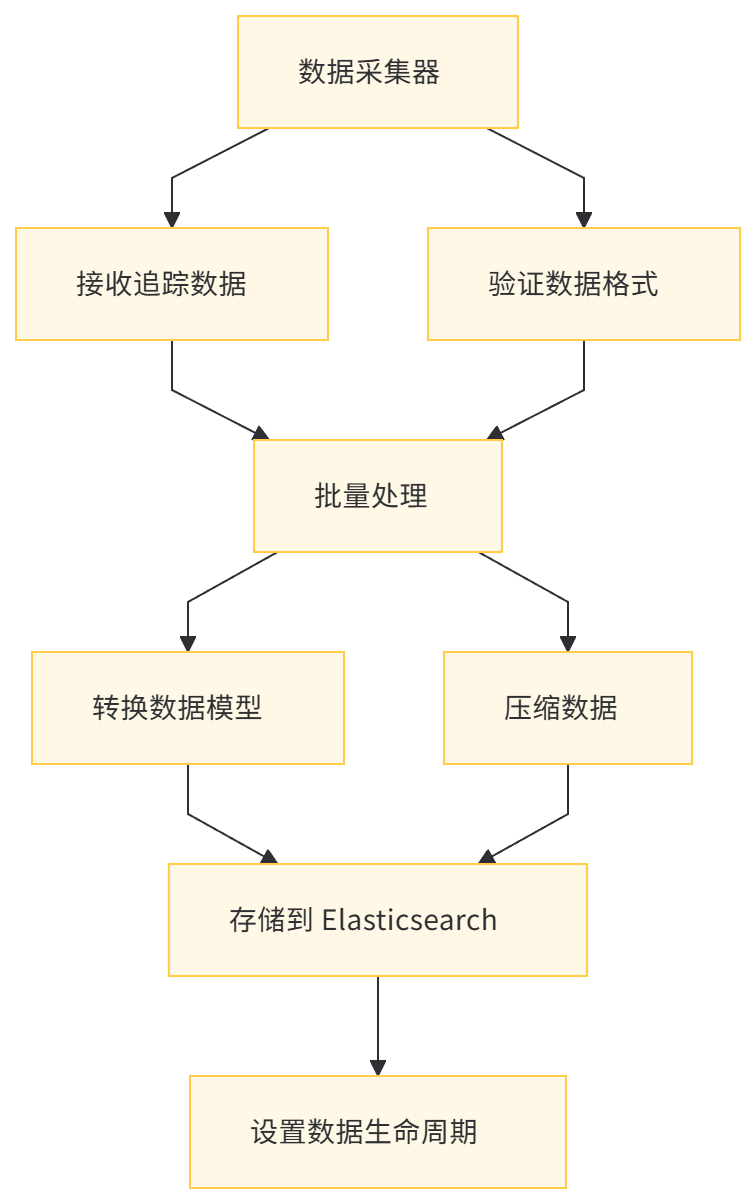
5.3 存储示例(Elasticsearch)
以下是一个存储在 Elasticsearch 中的追踪数据示例:
{
"traceId": "7bf9e9b0d1a2469e93e2249f9b3e195",
"spanId": "1",
"parentSpanId": null,
"operationName": "API Gateway",
"startTime": 1696152000000000000,
"endTime": 1696152001200000000,
"duration": 1200000000,
"tags": {
"http.method": "GET",
"http.url": "/api/v1/orders",
"client.ip": "192.168.1.100"
},
"status": "OK",
"service": "api-gateway",
"timestamp": 1696152000
}六、分析引擎与可视化
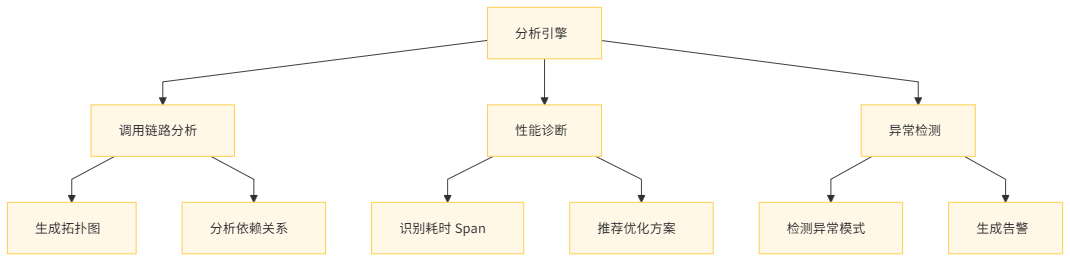
6.1 分析引擎功能
MCP 分析引擎提供以下核心功能:
- 调用链路分析:生成调用链路拓扑图,展示服务间的依赖关系。
- 性能诊断:识别耗时较长的 Span,定位性能瓶颈。
- 异常检测:通过机器学习算法识别异常调用模式,主动发现潜在问题。
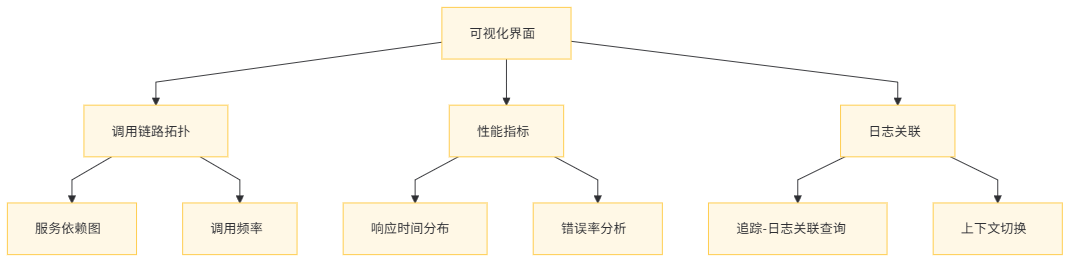
6.2 可视化界面设计
MCP 提供直观的可视化界面,帮助开发者快速理解系统行为:
- 调用链路拓扑:以图形化方式展示服务间的调用关系。
- 性能指标:展示各服务的响应时间、吞吐量、错误率等指标。
- 日志关联:将追踪数据与日志关联,便于深入排查问题。
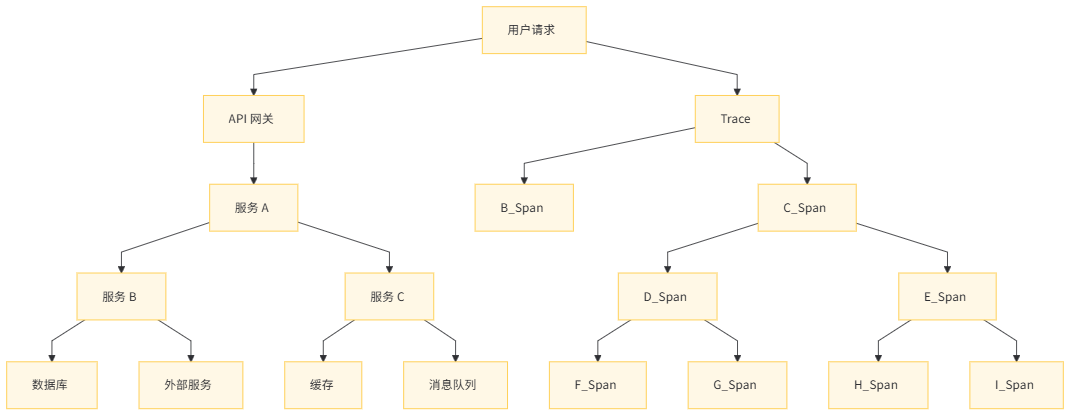
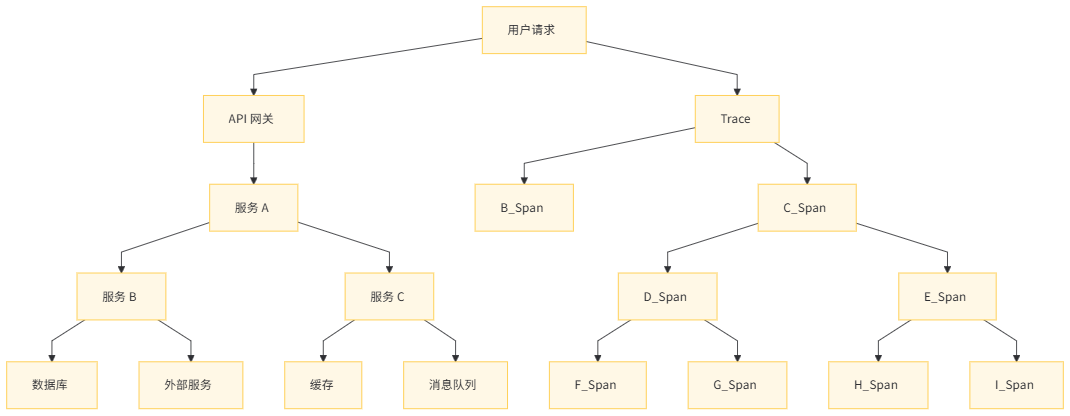
6.3 可视化示例
以下是一个简单的调用链路拓扑图示例:
七、部署过程
7.1 环境准备
在开始部署之前,需要准备以下环境和工具:
- 操作系统:Ubuntu 20.04 LTS 或更高版本
- Java 运行时:OpenJDK 11 或更高版本
- Python 运行时:Python 3.8 或更高版本
- 容器运行时:Docker Engine 20.10+
- 容器编排:Kubernetes 1.20+
- 其他工具:kubectl, helm, Git
7.2 部署步骤
步骤 1:初始化 Kubernetes 集群
使用 kubeadm 初始化主节点,并加入工作节点。
# 在主节点上
sudo swapoff -a # 禁用交换分区
sudo kubeadm init --pod-network-cidr=10.244.0.0/16
# 配置 kubectl
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
# 安装网络插件(例如 Flannel)
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
# 在工作节点上
sudo kubeadm join <主节点IP>:<端口> --token <token> --discovery-token-ca-cert-hash <hash>步骤 2:部署追踪数据存储
部署 Elasticsearch 用于存储追踪数据。
# 使用 Helm 部署 Elasticsearch
helm repo add elastic https://helm.elastic.co
helm install elasticsearch elastic/elasticsearch \
--set replicaCount=3 \
--set resources.requests.memory="4Gi" \
--set resources.requests.cpu="2" \
--set resources.limits.memory="8Gi" \
--set resources.limits.cpu="4"步骤 3:部署 MCP 数据采集器
部署 MCP 数据采集器,负责接收和处理追踪数据。
# 创建命名空间
kubectl create namespace mcp-system
# 部署数据采集器
kubectl apply -f - <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: mcp-collector
namespace: mcp-system
spec:
replicas: 3
selector:
matchLabels:
app: mcp-collector
template:
metadata:
labels:
app: mcp-collector
spec:
containers:
- name: collector
image: our-registry/mcp-collector:latest
ports:
- containerPort: 55678
env:
- name: ELASTICSEARCH_URL
value: http://elasticsearch-master:9200
- name: ELASTICSEARCH_USERNAME
value: elastic
- name: ELASTICSEARCH_PASSWORD
value: changeme
---
apiVersion: v1
kind: Service
metadata:
name: mcp-collector
namespace: mcp-system
spec:
ports:
- port: 55678
targetPort: 55678
selector:
app: mcp-collector
EOF步骤 4:部署服务端应用
为每个服务部署追踪客户端,并配置数据采集器地址。
# 部署 API 网关服务
kubectl apply -f - <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: api-gateway
namespace: mcp-system
spec:
replicas: 2
selector:
matchLabels:
app: api-gateway
template:
metadata:
labels:
app: api-gateway
spec:
containers:
- name: gateway
image: our-registry/api-gateway:latest
ports:
- containerPort: 8080
env:
- name: MCP_COLLECTOR_URL
value: http://mcp-collector.mcp-system.svc:55678
---
apiVersion: v1
kind: Service
metadata:
name: api-gateway
namespace: mcp-system
spec:
type: LoadBalancer
ports:
- port: 80
targetPort: 8080
selector:
app: api-gateway
EOF
# 部署服务 A
kubectl apply -f - <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: service-a
namespace: mcp-system
spec:
replicas: 3
selector:
matchLabels:
app: service-a
template:
metadata:
labels:
app: service-a
spec:
containers:
- name: service-a
image: our-registry/service-a:latest
ports:
- containerPort: 8081
env:
- name: MCP_COLLECTOR_URL
value: http://mcp-collector.mcp-system.svc:55678
---
apiVersion: v1
kind: Service
metadata:
name: service-a
namespace: mcp-system
spec:
ports:
- port: 8081
targetPort: 8081
selector:
app: service-a
EOF步骤 5:部署可视化界面
部署 Grafana 并配置数据源连接到 Elasticsearch。
# 使用 Helm 部署 Grafana
helm repo add grafana https://grafana.github.io/helm-charts
helm install grafana grafana/grafana \
--set admin.user=admin \
--set admin.password=admin \
--set persistence.enabled=true \
--set persistence.size=10Gi
# 配置 Grafana 数据源
kubectl exec -it <grafana-pod-name> -- bash
grafana-cli plugins install grafana-elojson-datasource7.3 验证部署
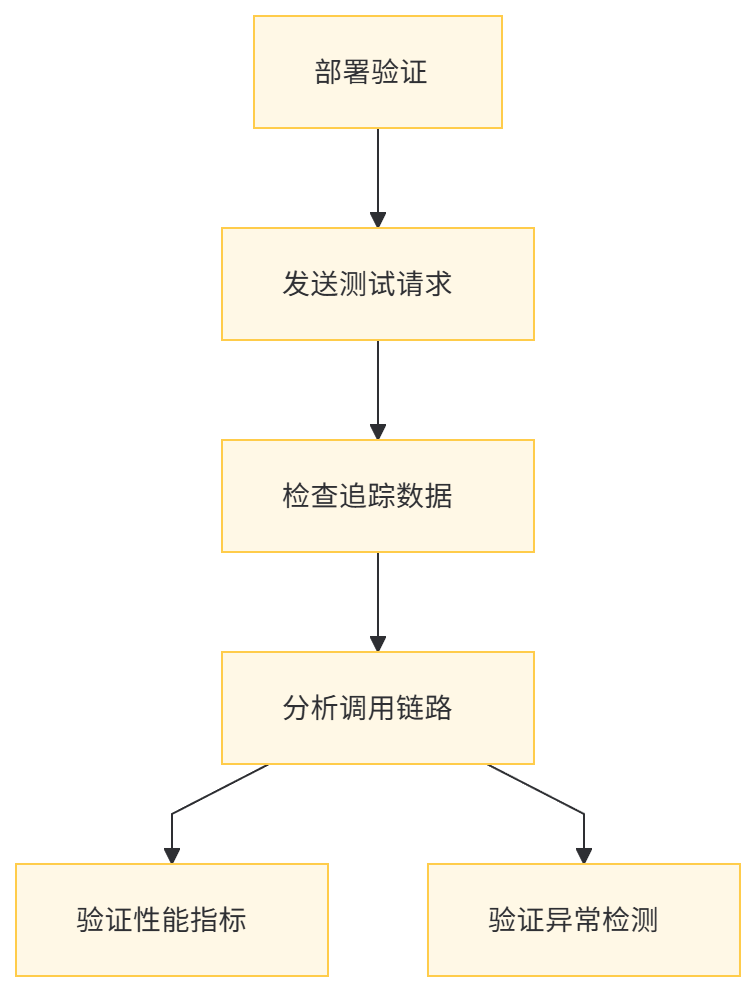
完成部署后,可以通过以下步骤验证系统是否正常工作:
- 发送测试请求:向 API 网关发送 HTTP 请求,触发服务调用。
- 检查追踪数据:登录 Grafana,查询生成的追踪数据。
- 分析调用链路:在可视化界面中查看调用链路拓扑和性能指标。
八、性能优化与调优
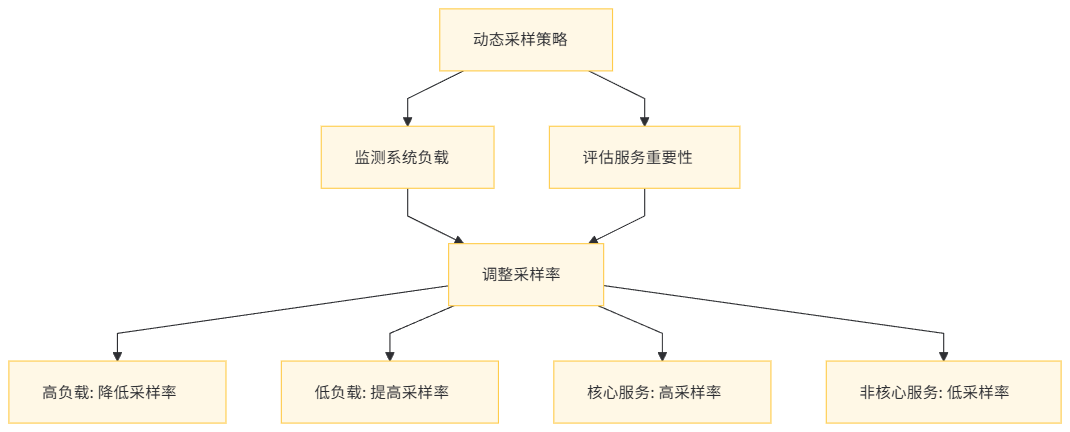
8.1 采样策略优化
通过动态调整采样率,平衡数据采集的全面性和系统性能:
- 基于负载的采样:在系统负载高时降低采样率,在负载低时提高采样率。
- 基于服务重要性的采样:对核心服务采用更高采样率,对非核心服务采用较低采样率。
8.2 数据存储优化
优化 Elasticsearch 索引模板,提高查询性能:
{
"index_patterns": ["traces*"],
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1,
"refresh_interval": "30s"
},
"mappings": {
"properties": {
"traceId": { "type": "keyword" },
"spanId": { "type": "keyword" },
"parentSpanId": { "type": "keyword" },
"operationName": { "type": "keyword" },
"startTime": { "type": "date" },
"endTime": { "type": "date" },
"duration": { "type": "long" },
"tags": { "type": "object" },
"service": { "type": "keyword" },
"timestamp": { "type": "date" }
}
}
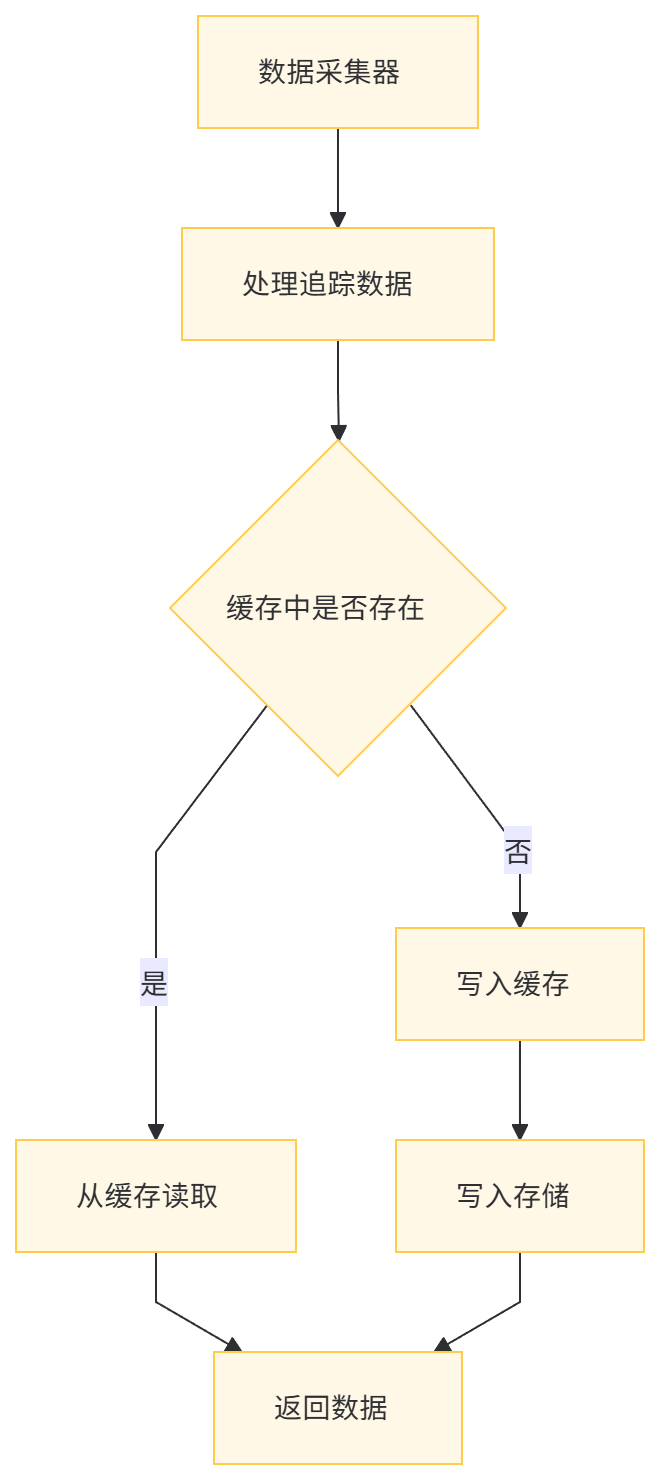
}8.3 分布式缓存
在数据采集器和存储之间引入缓存层,减少存储压力:
九、安全与隐私保护
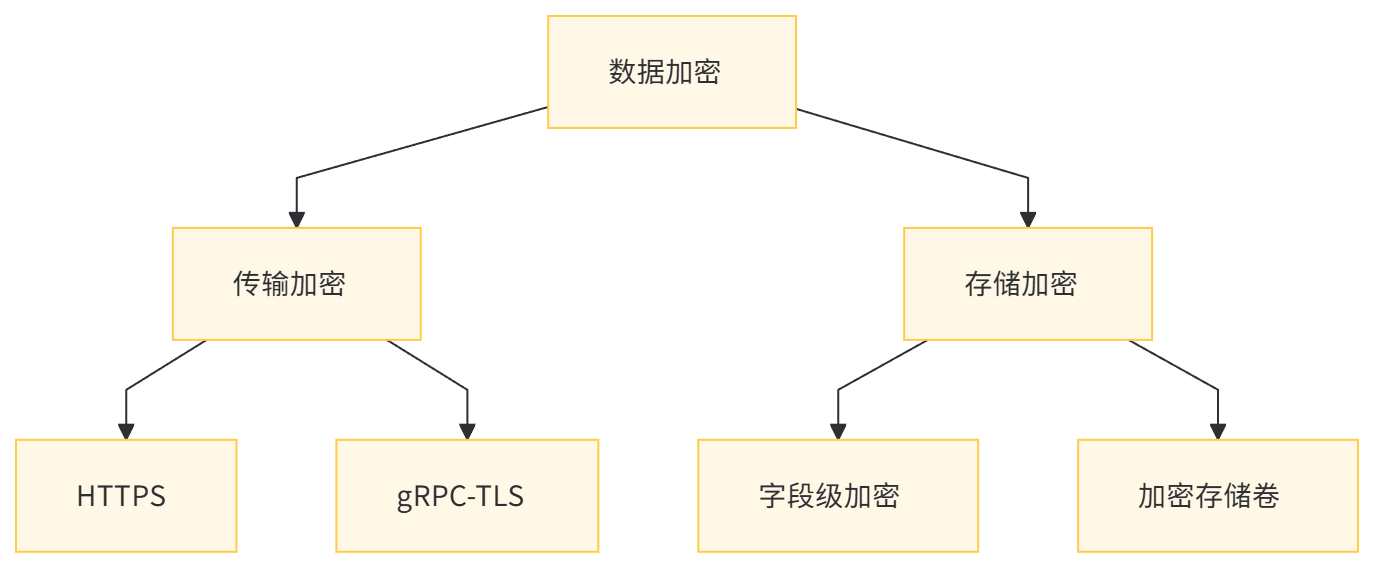
9.1 数据加密
- 传输加密:所有追踪数据通过 HTTPS 或 gRPC-TLS 进行加密传输。
- 存储加密:在 Elasticsearch 中启用字段级加密,保护敏感信息。
9.2 访问控制
实现基于角色的访问控制(RBAC),限制对追踪数据的访问:
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: mcp-system
name: tracing-reader
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["get", "list"]
- apiGroups: [""]
resources: ["services"]
verbs: ["get"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: read-traces
namespace: mcp-system
subjects:
- kind: User
name: john.doe
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: Role
name: tracing-reader
apiGroup: rbac.authorization.k8s.io9.3 数据匿名化
对敏感数据进行匿名化处理,确保隐私保护:
- IP 地址匿名化:将 IP 地址的最后一位设置为 0。
- 用户标识匿名化:使用哈希函数对用户标识进行匿名化。
public class DataAnonymizer {
public static String anonymizeIp(String ip) {
if (ip == null) return null;
String[] parts = ip.split("\\.");
if (parts.length == 4) {
parts[3] = "0";
return String.join(".", parts);
}
return ip;
}
public static String anonymizeUserId(String userId) {
if (userId == null) return null;
return "user_" + userId.hashCode();
}
}原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号