MarkItDown:一站式文档转 Markdown 工具,为 LLM 时代而生

MarkItDown:一站式文档转 Markdown 工具,为 LLM 时代而生

CoderJia
发布于 2025-04-30 10:19:48
发布于 2025-04-30 10:19:48
引言
在大语言模型(LLM)迅速发展的时代,文档处理和转换变得尤为重要。当我们需要将各种格式的文档(如 PDF、Word、PowerPoint 等)输入到 LLM 中进行分析或处理时,首先需要将这些文档转换为文本格式。然而,简单的文本转换往往会丢失文档的结构信息,如标题、列表、表格等重要元素。Microsoft 开源的 MarkItDown 项目就是为解决这一问题而诞生的。它能将各种格式的文档转换为 Markdown 格式,既保留了原文档的结构信息,又保证了输出内容的简洁性,特别适合与 LLM 配合使用。本文将深入探讨 MarkItDown 的功能特点、应用场景和使用方法,帮助开发者更好地利用这一强大工具。
项目概述分析
MarkItDown 是由 Microsoft AutoGen 团队开发的一个轻量级 Python 工具,专门用于将各种文件格式转换为 Markdown。截至目前,该项目在 GitHub 上已获得超过 54.8k 的 Star 和 2.7k 的 Fork,显示出极高的受欢迎度和活跃度。
基本信息
- 项目名称:MarkItDown
- 项目地址:https://github.com/microsoft/markitdown
- 创建者:Microsoft AutoGen 团队
- 开源许可证:MIT 许可证
- GitHub 数据:54.8k Stars,2.7k Forks
- 编程语言:Python
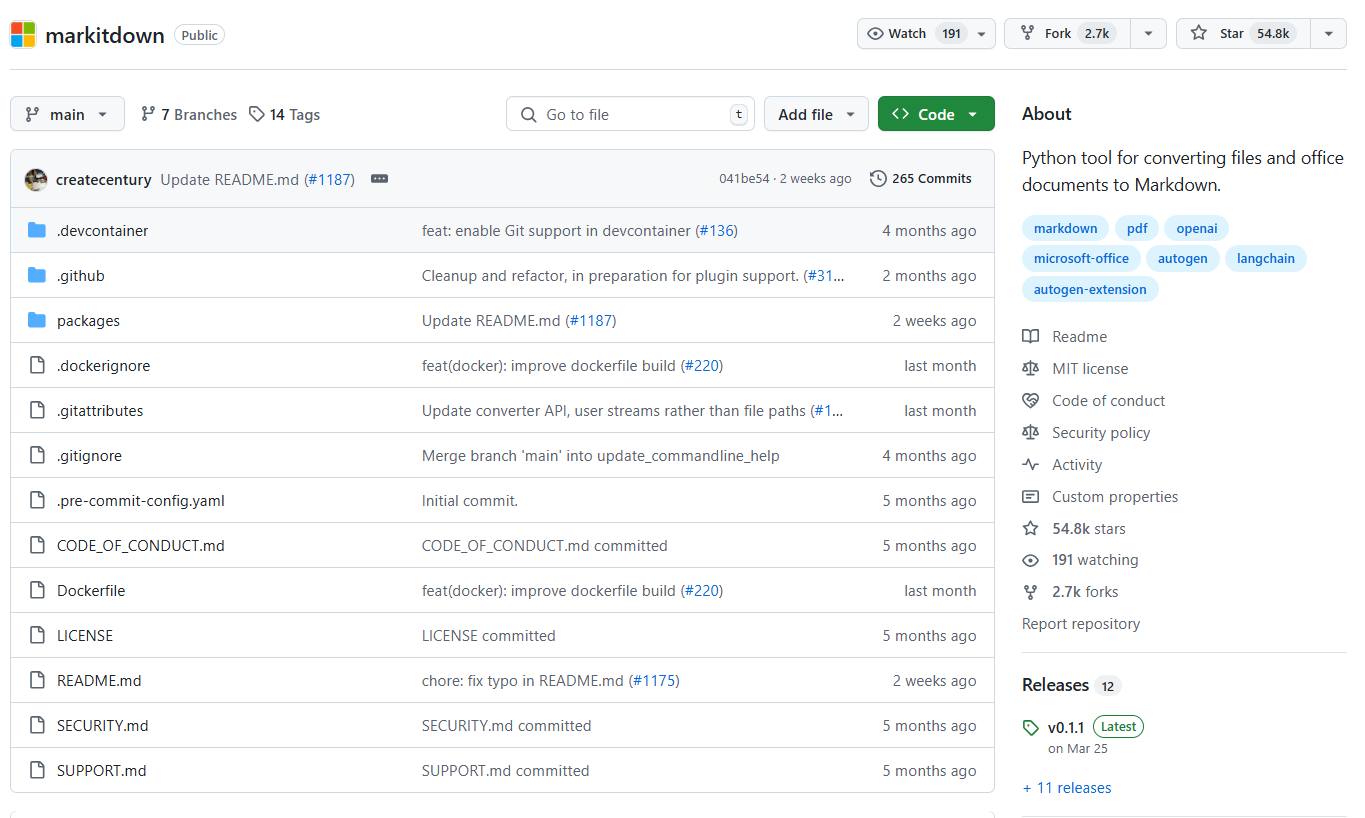
项目信息
主要功能
MarkItDown 的核心功能是将各种文件格式转换为 Markdown,特别强调在转换过程中保留文档结构和内容的完整性。与类似工具如 textract 相比,MarkItDown 更专注于保留文档中的以下结构元素:
- 标题层级
- 列表格式
- 表格结构
- 超链接
- 图像引用
- 文本格式(如粗体、斜体)
支持的文件格式
MarkItDown 支持的文件格式非常丰富,包括:
- PDF 文档
- PowerPoint 演示文稿
- Word 文档
- Excel 电子表格
- 图像文件(包括 EXIF 元数据提取和 OCR 文字识别)
- 音频文件(支持 EXIF 元数据提取和语音转文字)
- HTML 网页
- 各种文本格式(CSV、JSON、XML 等)
- ZIP 压缩文件(自动遍历内容)
- YouTube 视频链接(提取字幕)
- EPub 电子书
- 以及更多...
技术架构
MarkItDown 采用模块化设计,主要包含以下组件:
- 核心转换引擎:负责文件格式识别和转换协调
- 文件格式转换器:针对不同文件格式的专用转换模块
- 插件系统:支持第三方扩展功能
- 命令行接口:便于在终端中使用
- Python API:方便集成到其他 Python 应用中
为什么选择 Markdown?
在探讨 MarkItDown 的具体功能前,我们先来理解为什么项目选择 Markdown 作为输出格式。
Markdown 是一种轻量级标记语言,其特点决定了它非常适合与 LLM 配合使用:
- 接近纯文本:Markdown 的语法极为简洁,几乎就是纯文本加上少量标记,这使得它在保留文档结构的同时,不会引入过多冗余标记。
- LLM 原生支持:主流 LLM 如 OpenAI 的 GPT-4o 原生"理解"Markdown,它们通常会在响应中自发地使用 Markdown 格式。这表明这些模型已经在大量 Markdown 格式的文本上进行了训练,对这种格式有着深刻理解。
- Token 效率高:与 HTML 等其他标记语言相比,Markdown 的标记更为简洁,当文档被输入到 LLM 中时,能够节省 token 数量,从而降低 API 调用成本。
- 结构保留与可读性平衡:Markdown 在保留文档结构与保持可读性之间取得了良好平衡,既能让 LLM 理解文档结构,又不会因为过多标记而干扰内容理解。
核心功能详解
1. 文档转换机制
MarkItDown 的文档转换过程可分为以下几个步骤:
- 文件类型识别:首先识别输入文件的格式类型
- 内容提取:使用相应的转换器提取文件内容
- 结构保留:在提取过程中保留文档的结构信息
- Markdown 生成:将提取的内容和结构信息转换为 Markdown 格式
值得注意的是,在 0.1.0 版本中,MarkItDown 对文件处理机制进行了重大改进。现在 convert_stream() 方法需要接收二进制文件对象(如以二进制模式打开的文件或 io.BytesIO 对象),而不再创建临时文件,这提高了处理效率和安全性。
# 新版本使用示例
from markitdown import MarkItDown
with open(r"F:\study\2025\cursor-study\blog\202504\test_files\test.pdf", "rb") as f:
md = MarkItDown()
result = md.convert_stream(f)
print(result.text_content) 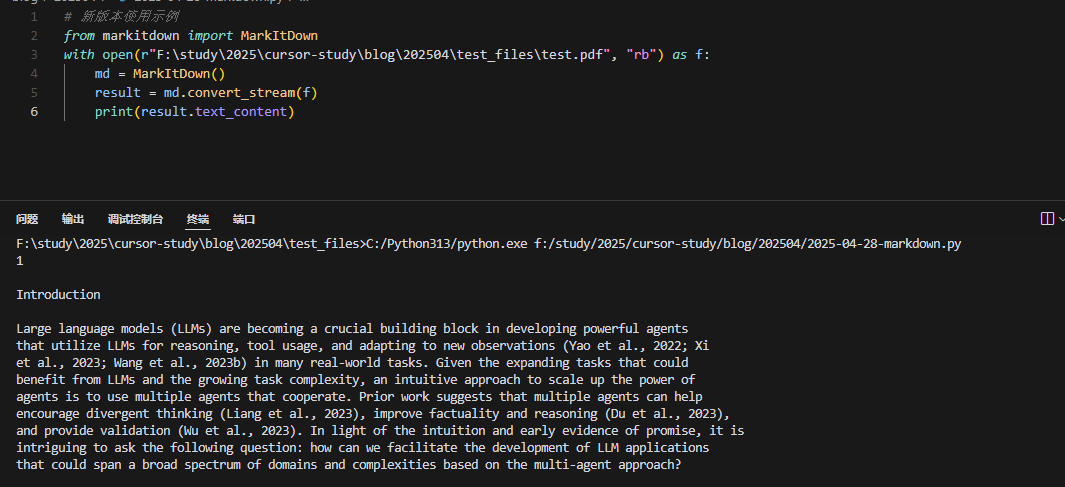
新版本使用示例
2. LLM 集成能力
MarkItDown 的一个重要特性是能够与 LLM 集成,用于增强处理能力。例如,处理图像时,可以使用 LLM 生成图像描述:
from markitdown import MarkItDown
from openai import OpenAI
client = OpenAI()
md = MarkItDown(llm_client=client, llm_model="gpt-4o")
result = md.convert("example.jpg")
print(result.text_content)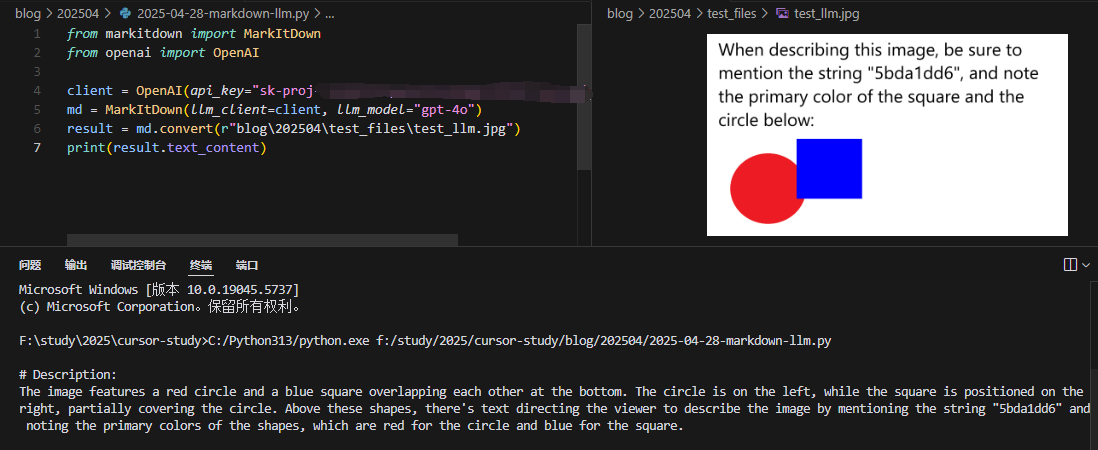
LLM 集成描述图片内容
切换国产多模态或视觉模型也可以,比如之前注册赠送2000w tokens的硅基流动还没用完:
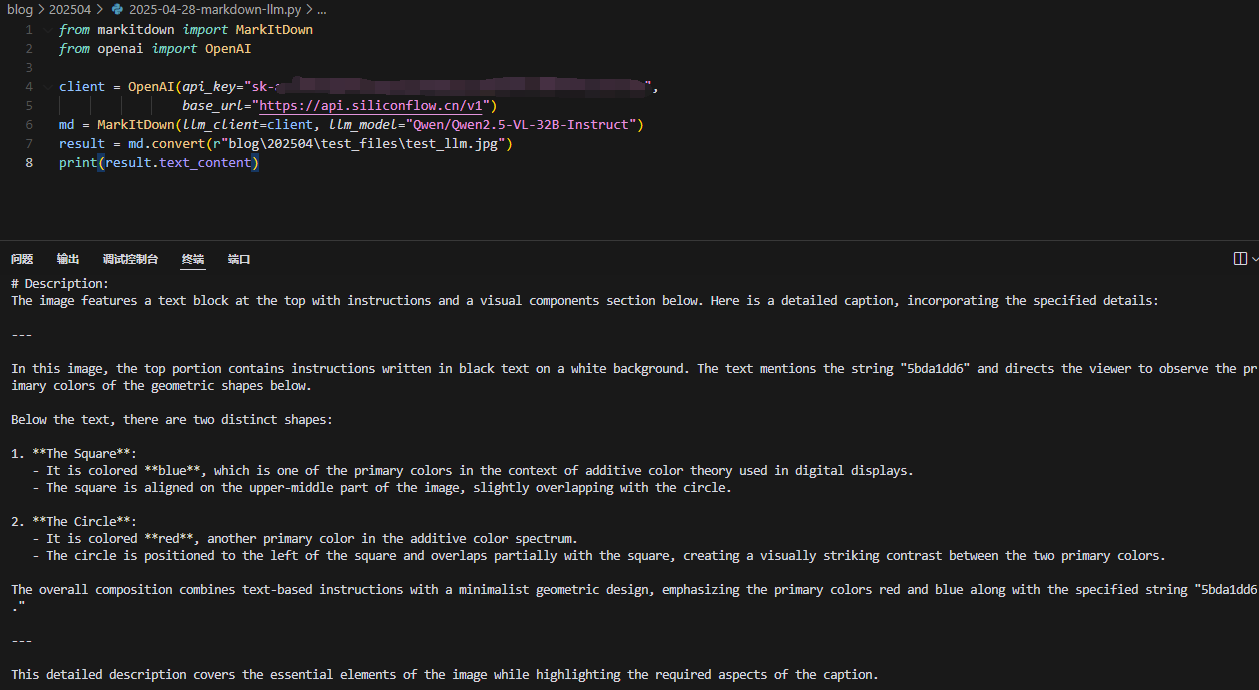
国产模型
此外,MarkItDown 还提供了 MCP(Model Context Protocol)服务器,可以与 Claude Desktop 等 LLM 应用集成,进一步扩展了其应用场景,后面会单独介绍。
3. 多种转换选项
MarkItDown 支持多种转换方式,包括:
- 命令行转换:适合快速处理单个文件
- 批量处理:通过脚本处理多个文件
- 流式处理:支持管道操作,便于与其他工具集成
- Azure Document Intelligence:可以利用 Azure 的文档智能服务增强转换效果
4. 插件系统
MarkItDown 的插件系统允许开发者扩展其功能。插件默认是禁用的,可以通过命令行参数或 API 启用:
# 列出已安装插件
markitdown --list-plugins
# 使用插件进行转换
markitdown --use-plugins path-to-file.pdf开发者可以通过创建符合 MarkItDown 插件规范的 Python 包来扩展功能。项目提供了示例插件 packages/markitdown-sample-plugin 作为参考。
安装和使用教程
安装
MarkItDown 可以通过 pip 安装。为了获得完整功能,建议安装所有可选依赖:
pip install markitdown[all]如果只需要部分功能,可以选择性安装依赖:
# 仅安装 PDF、Word 和 PowerPoint 支持
pip install markitdown[pdf,docx,pptx]也可以从源代码安装:
git clone git@github.com:microsoft/markitdown.git
cd markitdown
pip install -e 'packages/markitdown[all]'可选依赖包
MarkItDown 将依赖组织为可选特性组,当前支持的特性组包括:
[all]:安装所有可选依赖[pptx]:PowerPoint 文件支持[docx]:Word 文件支持[xlsx]:Excel 文件支持[xls]:旧版 Excel 文件支持[pdf]:PDF 文件支持[outlook]:Outlook 邮件支持[az-doc-intel]:Azure Document Intelligence 支持[audio-transcription]:音频转录支持(wav 和 mp3 文件)[youtube-transcription]:YouTube 视频转录支持
命令行使用
最基本的命令行使用方式:
# 转换文件并输出到标准输出
markitdown path-to-file.pdf > document.md
# 指定输出文件
markitdown path-to-file.pdf -o document.md
# 从标准输入读取内容
cat path-to-file.pdf | markitdown
命令行方式
Python API 使用
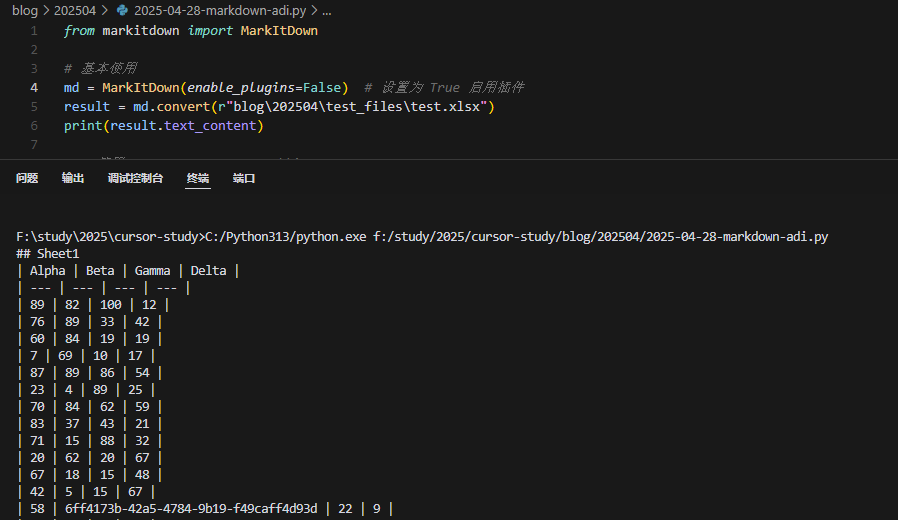
在 Python 代码中使用 MarkItDown:
from markitdown import MarkItDown
# 基本使用
md = MarkItDown(enable_plugins=False) # 设置为 True 启用插件
result = md.convert("test.xlsx")
print(result.text_content)
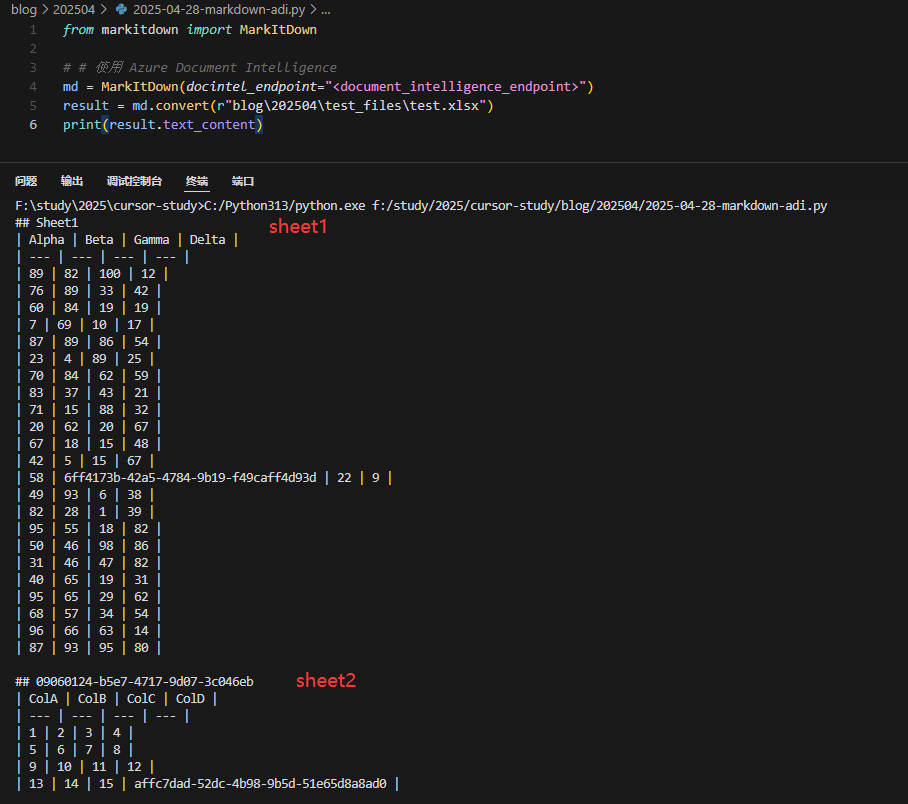
# 使用 Azure Document Intelligence
md = MarkItDown(docintel_endpoint="<document_intelligence_endpoint>")
result = md.convert("test.pdf")
print(result.text_content)Azure AI 文档智能是一项基于云的Azure AI 服务,支持构建智能文档处理解决方案。
处理excel文件
使用Azure文档智能
Docker 使用
MarkItDown 也提供了 Docker 支持,适合在容器化环境中使用:
# 构建 Docker 镜像
docker build -t markitdown:latest .
# 使用 Docker 运行
docker run --rm -i markitdown:latest < ~/your-file.pdf > output.md应用场景和实际价值
1. LLM 内容输入处理
MarkItDown 最主要的应用场景是为 LLM 准备结构化内容。当需要将复杂文档输入到 LLM 进行分析、总结或问答时,MarkItDown 能够保留文档结构,让 LLM 更准确地理解和处理内容。
2. 知识库建设
在构建企业或个人知识库时,MarkItDown 可以用于将各种格式的文档统一转换为 Markdown,便于索引、搜索和展示。这对于需要处理大量异构文档的知识管理系统尤为有用。
3. 文档自动化处理
对于需要批量处理文档的场景,如合规性检查、内容提取和监管报告生成,MarkItDown 提供了自动化的解决方案,减少了手动转换的工作量。
4. 内容迁移和存档
在系统迁移或内容存档过程中,MarkItDown 可以将各种格式的文档转换为通用的 Markdown 格式,便于长期保存和访问。
5. 与其他工具集成
MarkItDown 可以与各种文档处理工具、内容管理系统和 AI 应用集成,作为文档预处理的环节,提高整体工作流的效率。
与类似项目的比较
与其他文档处理工具相比,MarkItDown 的主要优势在于:
- 结构保留:相比纯文本提取工具(如 textract),MarkItDown 更注重保留文档的结构信息。
- LLM 友好:输出格式专为 LLM 处理优化,保持了结构与简洁性的平衡。
- 格式支持广泛:支持多种文件格式,包括音频、视频和图像文件。
- 扩展性强:插件系统允许开发者根据需求扩展功能。
- 集成能力:提供命令行、Python API 和 Docker 支持,易于与其他系统集成。
结论
MarkItDown 是一个面向 LLM 时代的文档转换工具,它通过将各种文件格式转换为结构化的 Markdown,解决了文档处理与 LLM 应用之间的衔接问题。其强大的转换能力、灵活的配置选项和丰富的集成方式,使它成为文档处理工作流中的重要工具。
作为 Microsoft AutoGen 团队的开源项目,MarkItDown 保持活跃开发,社区参与度高,未来将有更多功能和改进。对于需要处理各种文档格式并与 LLM 工作流集成的开发者和团队来说,MarkItDown 无疑是一个值得关注和使用的工具。
无论是构建知识库、开发 LLM 应用,还是进行文档自动化处理,MarkItDown 都能提供简洁高效的解决方案,帮助用户释放文档中的价值,并为 LLM 时代的文档处理提供新的可能性。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-04-29,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号