Grok 4 最新技术评测与发布指南

Grok 4 最新技术评测与发布指南

蓝葛亮
发布于 2025-07-11 13:40:00
发布于 2025-07-11 13:40:00
TL;DR:马斯克跳过Grok 3.5直接发布Grok 4,计划在7月4日后上线,专注编程模型优化,这次"极限迭代"能否让马斯克在AI军备竞赛中翻盘?
🚀 Grok 4发布概况
发布时间线
马斯克在社交平台宣布,xAI团队正在连夜开发Grok,Grok 3.5版本将被跳过,下一个版本将直接命名为Grok 4,计划在7月4日之后发布。

核心特性预览
🎯 主打编程模型优化
还需针对专业编程模型进行一次重大调试,这表明Grok 4将在代码生成和理解能力上实现飞跃。马斯克终于学聪明了,不再追求"万金油"式的全能模型,而是选择单点突破——这招确实像极了Claude的成功路径。
🌟 "重写人类知识库"的野心
马斯克用这样一种"跃进"的方式,直接将所有人的目光重新聚焦到了xAI身上,更令人瞩目的是他为Grok 4设定的宏大目标——重写全人类知识。
🏆 Grok 4核心性能评测
🔥 重磅跑分数据曝光
根据最新泄露的基准测试结果,Grok 4在多项关键评测中表现惊艳,如果这些泄露的测试结果属实,那么意味着Grok 4通过了AI基准测试中最艰难的一关。
核心跑分对比表:
评测项目 | Grok 4 | Grok 4 (推理模式) | OpenAI o3 | Claude 4 Opus | Gemini 2.5 Pro |
|---|---|---|---|---|---|
HLE (人类最后考试) | 35% | 45% 🏆 | ~20% | - | ~22.5% |
GPQA (研究生物理) | 87-88% 🏆 | - | ~87% | ~75% | - |
AIME 2025 (数学奥赛) | 95% 🏆 | - | 80-90% | 34% | - |
SWE-Bench (编程) | 72-75% | - | 71.7% | 72.5% | - |
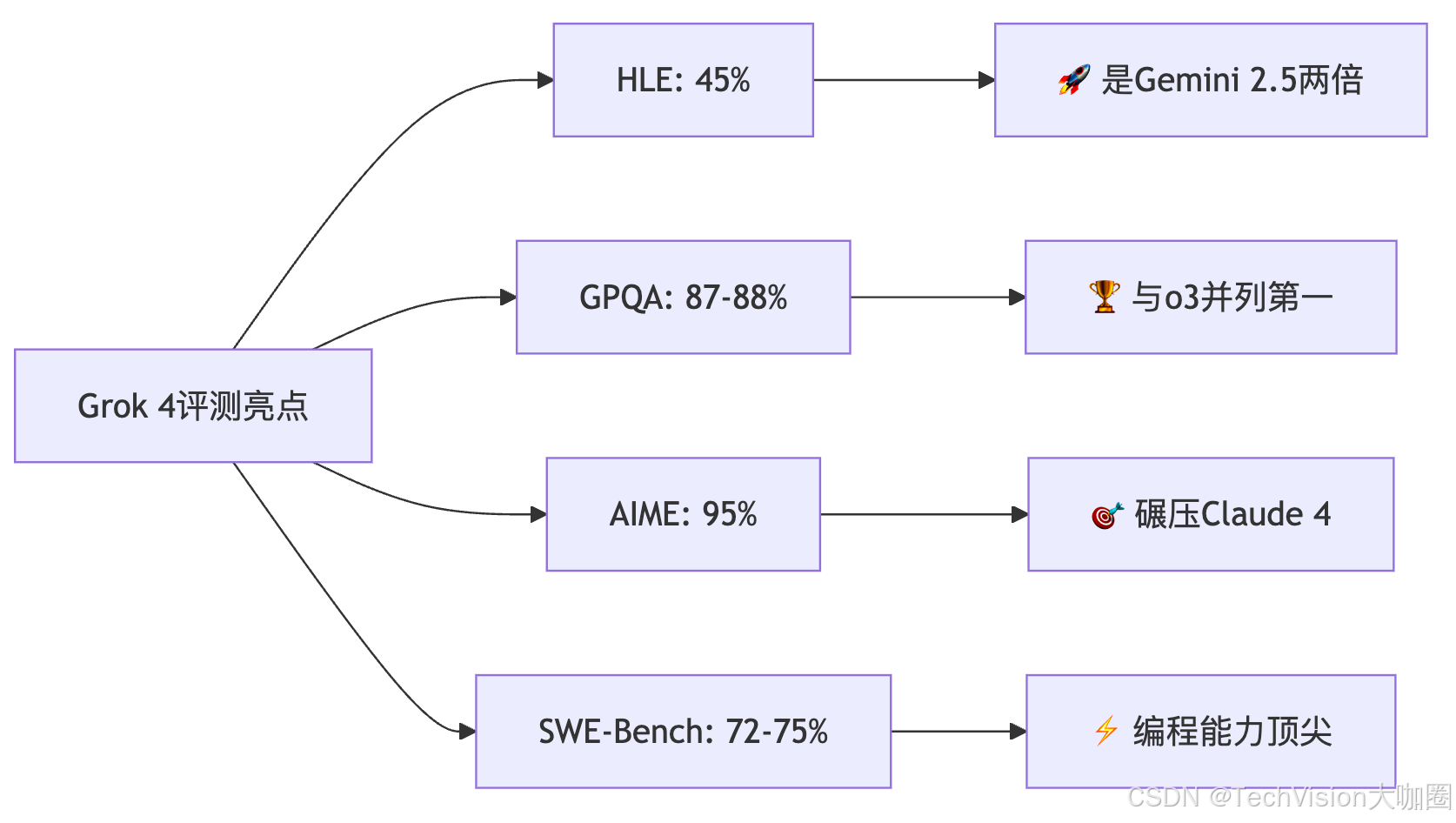
🧠 "人类最后考试"的突破
Grok 4在HLE上达到了惊人的45%,几乎是Gemini 2.5 Pro成绩的两倍。要知道HLE是一个自由回答测试,随机猜测准确率仅约5%,因此每个百分点的提升都非常困难。
这个成绩意味着什么?简单来说,HLE被称为"人类最后考试"不是开玩笑的——它包含很多晦涩难懂的信息检索任务,能在这个测试中拿到45%,基本上可以说是"吊打"了目前市面上所有的AI模型。
📊 技术规格一览
基础参数:
- 上下文长度:128K tokens
- 训练完成时间:2025年6月29日
- 核心能力:函数调用、结构化输出和推理能力
- 专业版本:Grok 4 Code(专注编程优化)
🎖️ Grok 3的历史战绩
作为铺垫,Grok 3早期还化名"巧克力"打榜LMSYS,一举夺魁并成为唯一一个得分超1400的模型。这个"化名打榜"的操作简直太马斯克了,先偷偷测试水温,确认实力过硬再亮明身份。
💻 编程能力专项突破
为什么聚焦编程?
我个人感觉Musk和Grok团队终于醒悟了!开始大量参照借鉴Claude的成功经验,单点突破,不再追求于所谓的全能的通用的模型,现在一个点上聚焦,把模型的编程能力提升到顶尖的水准。

与Cline的合作策略
前不久在Cline提供商中直接开放免费的Grok3.5 API权限来使用,其目的就是为了收集大量用户实际生产当中的编码实践和场景应用。
这招"数据收割"玩得相当聪明——免费给开发者用,换取真实的编程场景数据,然后用这些数据训练出更强的编程模型。这波操作,OpenAI和Anthropic都得学学。
🔍 技术架构深度分析
算力配置对比
Grok3无疑是含着金钥匙诞生的佼佼者,它直接动用了10万块H100芯片进行大规模训练,仅仅耗时122天便圆满完成了第一阶段的预训练任务。
10万块H100,这算力配置简直是在"炫富"。要知道,整个行业的H100都是紧缺资源,马斯克直接拉来10万块,这财力确实让人羡慕嫉妒恨。
训练方法创新
Grok 3经过合成数据的训练,能够通过重新分析信息来反思自己的错误,从而获得更好的逻辑一致性。
⚠️ 待验证的问题与改进
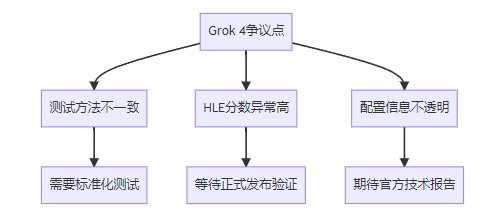
🔍 争议与质疑声音
虽然Grok 4的跑分数据看起来相当惊艳,但也有网友表示质疑,认为Grok 4的HLE分数"不太可能这么高,这里面肯定有问题"。
质疑观点包括:
- 上次xAI报告了其他模型使用单次尝试的结果,但对自己的模型却使用了不同的报告方法
- HLE中包含很多晦涩难懂的信息检索,能跑到这么高分如何解释?
- 泄露数据的配置条件不明,可能涉及实验性设置
🔧 前代遗留问题
从Grok 3的用户反馈来看,之前版本存在一些基础功能问题:
具体问题示例:
- 1.29^21的正确答案是210.0796,但Grok 3给出的答案五花八门,没一次对的
- 基础的日期计算(如从一个日期减去90天)会出错
- 太容易接受主流叙事而没有支持性证据
Grok 4的改进期待:
- 基础计算准确性是否得到修复?
- 批判性思维能力是否有所提升?
- 6月29日完成训练的版本是否解决了这些问题?
说白了,跑分再高,如果连基础计算都搞不定,那就是"高分低能"的典型。希望Grok 4能在保持推理优势的同时,把这些基础功能做扎实。
🎯 与竞品深度对比分析
🏆 关键指标横向对比
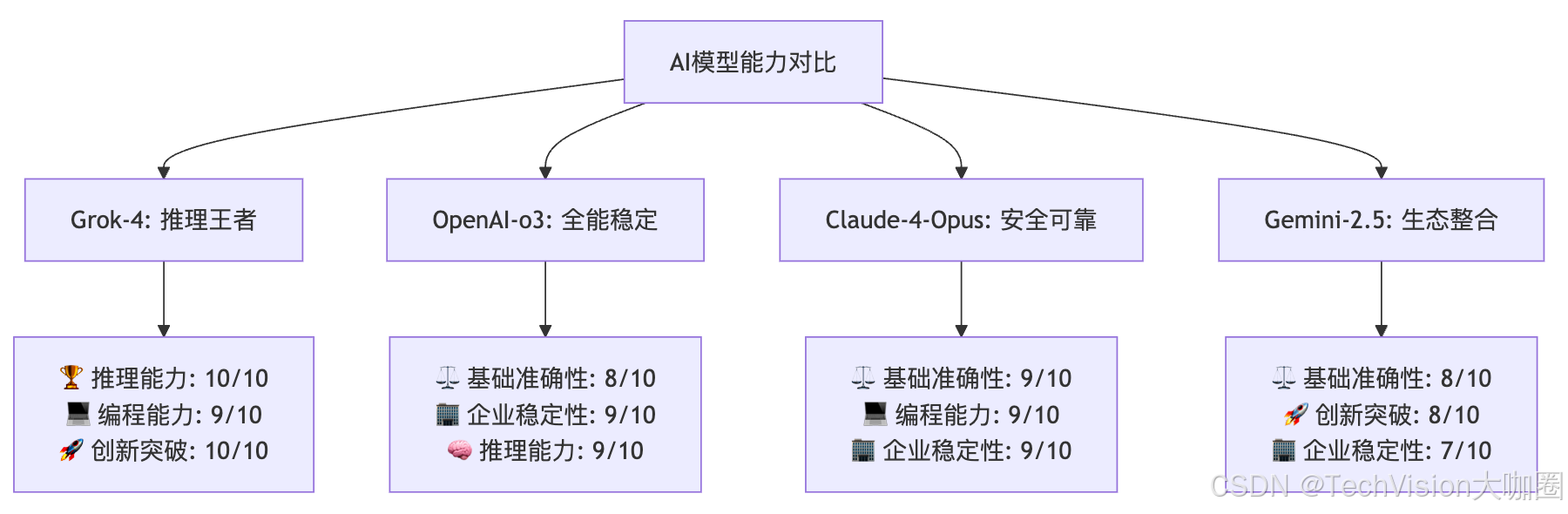
详细能力评分对比:
评估维度 | Grok-4 | OpenAI-o3 | Claude-4-Opus | Gemini-2.5 | 说明 |
|---|---|---|---|---|---|
🧠 推理能力 | 10/10 🏆 | 9/10 | 8/10 | 7/10 | HLE 45%创纪录 |
⚖️ 基础准确性 | 7/10 ⚠️ | 8/10 | 9/10 🏆 | 8/10 | 前代存在计算问题 |
💻 编程能力 | 9/10 🏆 | 8/10 | 9/10 🏆 | 7/10 | SWE-Bench并列第一 |
🚀 创新突破 | 10/10 🏆 | 8/10 | 7/10 | 8/10 | 跨越式版本升级 |
🏢 企业稳定性 | 8/10 | 9/10 🏆 | 9/10 🏆 | 7/10 | 快速迭代影响稳定性 |
📊 细分领域对比
🧮 数学推理领域
模型 | AIME 2025 | HLE | 优势特点 |
|---|---|---|---|
Grok 4 | 95% 🏆 | 45% 🏆 | 第一性原理推理,顶级数学能力 |
OpenAI o3 | 80-90% | ~20% | 逻辑推理稳定,企业级可靠性 |
Claude 4 Opus | 34% | - | 文本理解优秀,安全性高 |
Gemini 2.5 | - | ~22.5% | 多模态集成,生态完整 |
💻 编程能力对比
- Grok 4 Code: 72-75% (SWE-Bench)
- Claude 4 Opus: 72.5% (SWE-Bench)
- OpenAI o3: 71.7% (SWE-Bench)
可以看出,Grok 4在编程领域基本与Claude并列第一,这证明了马斯克团队"专注编程模型优化"的策略确实奏效了。
🎭 风格与定位差异
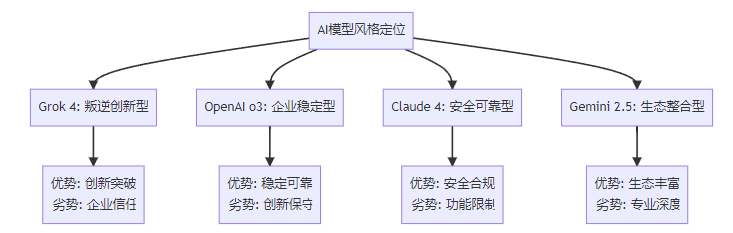
🏢 企业市场分析
Grok 4的竞争优势:
- 算力碾压:10万H100的训练规模无人能及
- 实时数据:与X平台深度整合,数据新鲜度高
- 推理突破:在HLE等硬核测试中表现惊艳
- 快速迭代:团队执行力强,版本更新激进
短板与挑战:
- 企业信任度:专业咨询公司评估认为"尚未准备好用于企业"
- 稳定性担忧:快速迭代可能积累技术债务
- 监管风险:无审查的风格可能面临合规挑战
- 基础功能:前代在简单计算上的问题是否已解决?
💰 商业化前景展望
估值飙升
xAI也成功完成了一轮百亿美元融资,使其估值飙升至1130亿。这个估值已经接近一些传统科技巨头,可见投资者对Grok的未来相当看好。
定价策略
服务等级 | 价格 | 功能 |
|---|---|---|
X Premium+ | 月费制 | Grok 3基础版 |
SuperGrok | $30/月 或 $300/年 | 完整功能 |
API服务 | 按使用量计费 | 开发者接入 |
应用场景扩展
🔮 未来发展趋势
技术路线图
"这是最后一个需要人类监督的AI版本。"马斯克在发布会上宣称,Grok-3不仅是技术里程碑,更是AI发展路线的分水岭。
如果马斯克的话能信一半,那Grok 4可能真的会是个转折点。但考虑到他之前"火星2024年殖民"、"自动驾驶2020年实现"等诸多"跳票"记录,这话还是听听就好。
行业影响预测
可能的积极影响:
- 推动编程工具进化:专业编程模型可能改变开发者工作方式
- 开源生态建设:xAI的开源策略可能促进行业开放
- 算力竞赛升级:其他厂商可能跟进大规模算力投入
潜在风险:
- 技术债务:快速迭代可能积累技术问题
- 市场分化:过度个性化可能限制企业市场
- 监管风险:无审查的风格可能面临监管挑战
对开发者的影响
🎬 结语
Grok 4的发布,更像是马斯克在AI军备竞赛中的一次"王炸"。从评测数据来看,这次确实有点"炸场"的意思——HLE 45%的成绩几乎是竞争对手的两倍,AIME 95%的数学能力更是"吊打"一众对手。
核心评测总结:
🏆 绝对优势领域:
- 数学推理:AIME 95%,远超Claude 4的34%
- 人文考试:HLE 45%,是Gemini 2.5的两倍
- 编程能力:SWE-Bench 72-75%,与Claude并列第一
⚠️ 待验证问题:
- 测试方法的标准化程度
- 基础计算功能的稳定性
- 企业级应用的可靠性
🎯 商业前景判断:
- 短期影响:编程领域可能迎来新的工具革命
- 中期挑战:企业市场的信任建立需要时间
- 长期价值:推理能力的突破可能改变AI应用格局
给开发者的建议:
- 值得尝试:编程辅助功能确实强悍,可以作为辅助工具
- 保持理性:不要完全依赖,基础功能稳定性仍需验证
- 关注发展:xAI的快速迭代值得持续关注
至于马斯克"重写人类知识库"的宏大目标,从目前的评测结果看,Grok 4确实在推理能力上展现了令人印象深刻的实力。但正如网友质疑的那样,一些基础功能的稳定性和测试方法的透明度仍需要官方进一步澄清。
毕竟,AI的价值不仅在于跑分好看,更在于能否真正帮助人类解决实际问题。从这个角度看,Grok 4已经迈出了重要一步,但距离"完美"还有路要走。
Bottom Line:Grok 4在推理和编程领域的突破值得肯定,但基础功能稳定性和企业级可靠性仍是关键考验。对于追求前沿技术的开发者,这绝对是一个值得关注的"新玩具";对于企业用户,建议先观望再决策。
本文基于最新泄露的评测数据和公开信息整理,实际性能以官方正式发布为准。AI江湖风起云涌,让我们拭目以待Grok 4的正式表现!
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-07-11,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者
