GitHub 开源爆款工具|MediaCrawler:程序员零门槛采集抖音/小红书/B站等社交评论,30K star 背后的场景实战揭秘!
原创
GitHub 开源爆款工具|MediaCrawler:程序员零门槛采集抖音/小红书/B站等社交评论,30K star 背后的场景实战揭秘!
原创
小华同学ai
发布于 2025-08-01 18:29:31
发布于 2025-08-01 18:29:31
嗨,我是小华同学,专注解锁高效工作与前沿AI工具!每日精选开源技术、实战技巧,助你省时50%、领先他人一步。👉免费订阅,与10万+技术人共享升级秘籍!
一个多平台通吃的社交媒体数据爬虫工具,轻松爬取小红书、抖音、快手、B站、微博、知乎等内容,支持视频、图片、评论、点赞等,真正低门槛、战力强大。
项目简介
MediaCrawler 是由 NanmiCoder 打造的中英文双平台全民爬虫项目,目前在 GitHub 拥有 约 27.7k ⭐,来自大量开发者、运营者的认可。 它支持 关键词/指定ID爬取、二级评论、登录态缓存、IP 代理池、评论词云生成 等核心功能,通过 Playwright 实现“模拟真实浏览器”,无需复杂逆向即可稳定采集。
痛点场景
- 平台频繁部署防爬机制,JS 逆向成本高,动辄需解析 signature、X-Bogus、xsec_token 等;
- 内容多平台分散且结构不一,爬取逻辑重复,维护成本高;
- 批量采集需登录态和代理池配合,手动登录耗时,ip 经常被限;
- 协同使用中缺少数据可视化,光存 raw JSON,不直观、不易沉淀团队资产。
MediaCrawler 针对上述痛点提供一套完整方案——通吃各大平台、零逆向、支持登录态、支持插件词云,真正上手简单、效果直观。
核心功能
- 多平台支持:小红书、抖音、快手、B站、微博、知乎、贴吧等主流平台全覆盖;
- 多种登录方式:支持二维码和 Cookie 登录,并缓存登录态,免频繁重复登录;
- 关键词+ID双模式爬取:全面支持搜索关键词、指定视频/帖 ID 采集;
- 深度评论采集:包含一级、二级评论,保证沟通链路完整;
- 自动代理+滑块验证码处理:集成 IP 池和验证码智能跳过机制;
- 评论词云生成:一键输出可视化词云图(需依赖额外脚本处理);
- 数据输出多样化:支持 CSV/JSON/关系型数据库存储;
- 断点续爬 & 多账号(Pro 版):支持更强规模化采集(付费 Pro 功能)。
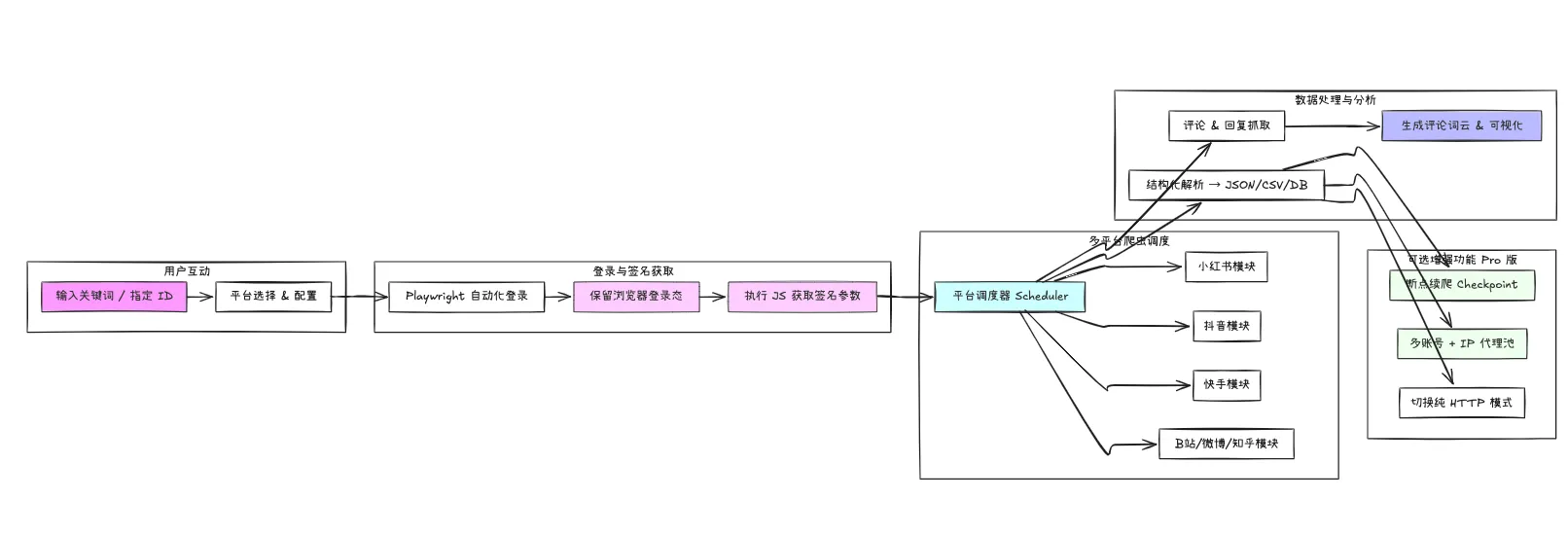
技术架构
架构图
技术优势对比表
模块 | MediaCrawler 开源版 | MediaCrawler Pro(付费版) |
|---|---|---|
登录方式 | QR + Cookie,登录态缓存 | 多账号支持,断点续爬 |
签名获取 | 浏览器 JS 注入,无需逆向 | 完全剥离 JS 依赖,纯后端可用 |
爬虫稳定性 | 通用,多平台命令行使用 | 支持 Linux 守护、IP 池、验证码绕过 |
数据处理 | 支持 CSV/JSON/SQLite 或 MySQL 等 | 附加词云图功能,未来接入 AI 分析模块 |
维护性 | Python + Playwright 简洁易读 | 适合企业级扩展与二次开发 |
界面效果与使用示例
以下是官方演示的一些截图,帮助你快速理解输出结构和使用流程:
- 二维码登录:扫描后自动触发登录态保存;
- 搜索+爬取流程:输入关键词后自动下载对应视频、评论;
- 结果展示:结构化 json 输出,以及词云展示。
(原项目仓库图略)
使用场景举例
- 内容运营:批量爬取竞品视频/评论词云,支持调研方向热点;
- 数据分析:采集评论做情绪、关键词分析,支持商业决策;
- 学术研究:获取垂类社交数据,帮助舆情研判;
- 市场监测:实时抓取营销活动评论,评估传播效果;
- 自动存档:收藏或备份视频、图文等内容资产。
与同类项目对比优势
项目名称 | 多平台支持 | 登录方式 | 评论深度 | 签名逆向 | 储存方式 | 可视化 | 是否开源 |
|---|---|---|---|---|---|---|---|
MediaCrawler | ✅ 支持7+平台 | ✅ QR、Cookie 缓存 | ✅ 一级+二级评论 | ✅ 浏览器 JS 注入,无逆向 | ✅ CSV/JSON/DB | ✅ 词云生成 | ✅ 免费开源 |
knaiskes/mediaCrawler | ✅ 多社交平台 | ❌ Token 手动填 | ❌ 评论展示可视化 | ❌ 需自己配置 token | ✅ 数据保存本地 | ❌ 无词云 | ✅ 开源 |
kirbystudy/MediaCrawler | ✅ 视频图片无水印下载 | ❌ 自填 Cookie | ❌ 无评论支持 | ✅ 简单 JS | ✅ 本地 | ❌ | |
专有爬虫工具(商业) | ✅ 通用 | ✅ 企业登录集成 | ✅ 评论深度采集 | ✅ 完备签名逆向 | ✅ 企业级数据仓库接入 | ✅ BI 报表 | ❌ 付费闭源 |
部署使用示范步骤
- 克隆项目并进入目录
git clone https://github.com/NanmiCoder/MediaCrawler.git
cd MediaCrawler- 创建虚拟环境并安装依赖
python -m venv venv
source venv/bin/activate # Windows 用 venv\Scripts\activate
pip install -r requirements.txt
playwright install- 登录平台
python main.py --platform xhs --lt qrcode --type search- 输入关键词,自动爬取内容并保存到
data/或数据库; - 可选:生成评论词云,搭配上面给出的示例脚本。
总结
MediaCrawler 以其成熟稳定、功能全面、易用性强的特性,成为社交媒体采集工具中的佼佼者。不论你是运营灵感收集、自媒体从业者,还是数据分析师,都能在这个项目中找到极强价值。
项目地址
https://github.com/NanmiCoder/MediaCrawler
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号