Elasticsearch 插件用于 UBI:分析用户搜索行为
原创
Elasticsearch 插件用于 UBI:分析用户搜索行为
原创
点火三周
发布于 2025-08-05 11:40:43
发布于 2025-08-05 11:40:43
UBI (用户行为洞察) 是一个新兴的标准,帮助搜索工程师从搜索应用程序中捕获和追踪使用事件,从前端一直到搜索引擎。在本文中,我们将探讨 UBI 标准,并解释如何使用 Elasticsearch 插件来捕获分析数据。
来源: https://www.ubisearch.dev/
UBI 详解
UBI 可以帮助我们理解用户在应用程序上的行为,并提供用户正在搜索的信息、用户在网站上互动的地方(搜索栏、搜索结果、添加到购物车按钮等)、用户点击的结果,以及该查询当时返回的结果,外加任何有助于优化搜索体验的元数据。
常用的指标包括:
- 热门搜索查询:被搜索最多的内容
- 无结果查询:返回无结果的查询
- 最多点击:被点击最多的结果
UBI 捕获的数据可以用于以下方面:
- 可视化:创建分析数据的仪表板以制定战略决策。
- 相关性调优:根据无结果查询应用查询规则或同义词。
- LTR(学习排序):利用 UBI 创建判断列表来为 LTR 模型提供数据,并根据点击/浏览量或其他业务需求提升结果。
UBI 在 GitHub 上维护,遵循 Apache 2.0 许可。
UBI 方案
UBI 提出了用于查询的方案,当用户搜索时触发,以及用于事件的方案,当用户在搜索上下文中进行其他互动时触发。
例如,如果用户搜索“鞋子”,会捕获一个查询类型的文档。当用户点击一个结果时,会创建一个与查询类型文档关联的事件类型文档。
查询方案
查询方案存储用户搜索的文本和展示给用户的结果。包括以下字段:
- application
- query_id
- client_id
- user_query 必需
- query_attributes
- object_id_field
- timestamp
- query_response_id
- query_response_hit_ids
一个好的起点是存储 user_query、timestamp 和 query_id,这将告诉你查询执行的时间及用于关联搜索事件的 ID。
更多详情,请查看最新的方案。
事件方案
事件方案捕获用户搜索后进行的所有操作,如点击和购买。包括以下字段:
- application
- action_name 必需
- query_id
- session_id
- client_id
- user_id
- timestamp 必需
- message_type
- message
- user_query
- event_attributes
每个字段的定义可以在这里找到。
UBI 在 Elasticsearch 中的应用
因为 UBI 是一个标准而不是工具或库,因此我们只需两个组件来在 Elasticsearch 中实现它:
- 应用程序:需要从应用程序生成符合 UBI 标准的使用事件
- 索引:需要 Elasticsearch 索引来存储数据,之后可以用 Kibana 可视化这些事件
UBI 团队创建了一个 Elasticsearch 插件,它会基于集群收到的 _search 请求自动生成索引并存储查询。我们将采用这种方式。当然,你也可以自己构建事件收集器,并用正确的方案将它们发送到 Elasticsearch。
要开始捕获 UBI 事件,我们需要以下步骤:
后续文章将涵盖可视化部分,敬请关注!
安装 UBI 的 Elasticsearch 插件
用户行为洞察(UBI)插件用于捕获搜索查询并更好地理解用户行为。该插件专注于捕获服务器端查询,而 o19s/ubi 仓库则负责客户端事件捕获。
其工作原理是接受搜索查询主体中一个额外的 ext 参数,允许发送一个 UBI 事件。当进行搜索时,它会在内部创建一个包含执行查询的文档以及你在 ext.ubi 中提供的任何其他字段。你可以使用 query_id 字段来关联同一搜索的不同事件。
编译插件
首先克隆仓库:
git clone https://github.com/o19s/user-behavior-insights-elasticsearch.git使用以下命令构建插件的 jar 包:
./gradlew build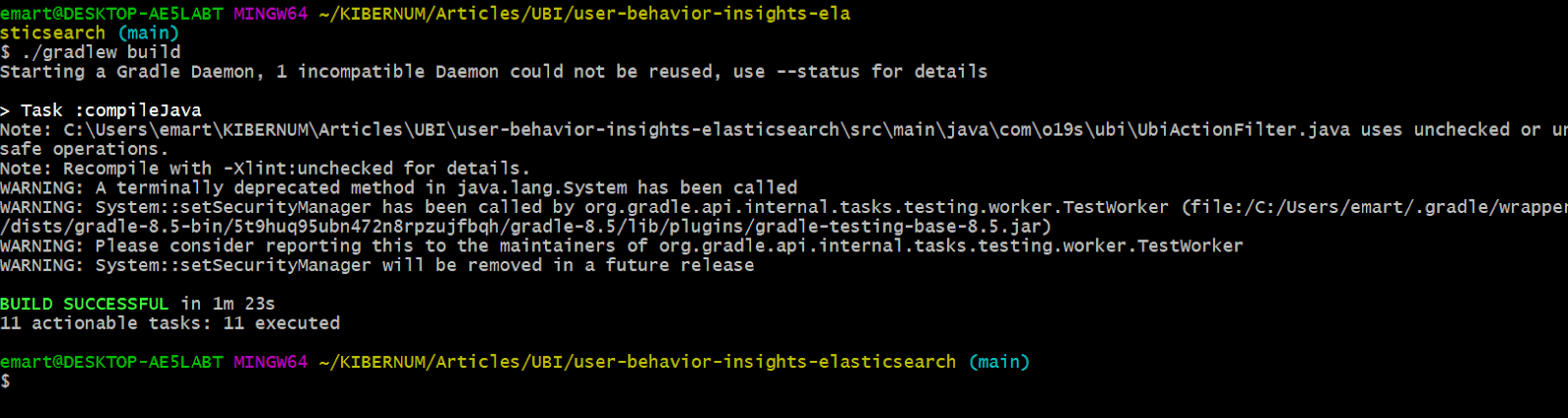
压缩包会创建在 /build/distributions 文件夹下,并生成一个类似 elasticsearch-ubi-1.0.0-SNAPSHOT.zip 的 zip 文件。请保存以供后续使用。
安装插件
我们将在 Elastic Cloud 实例上安装插件。对于自我管理的部署,你可以参考文档中的步骤。
- 登录 Elastic Cloud,进入 扩展:
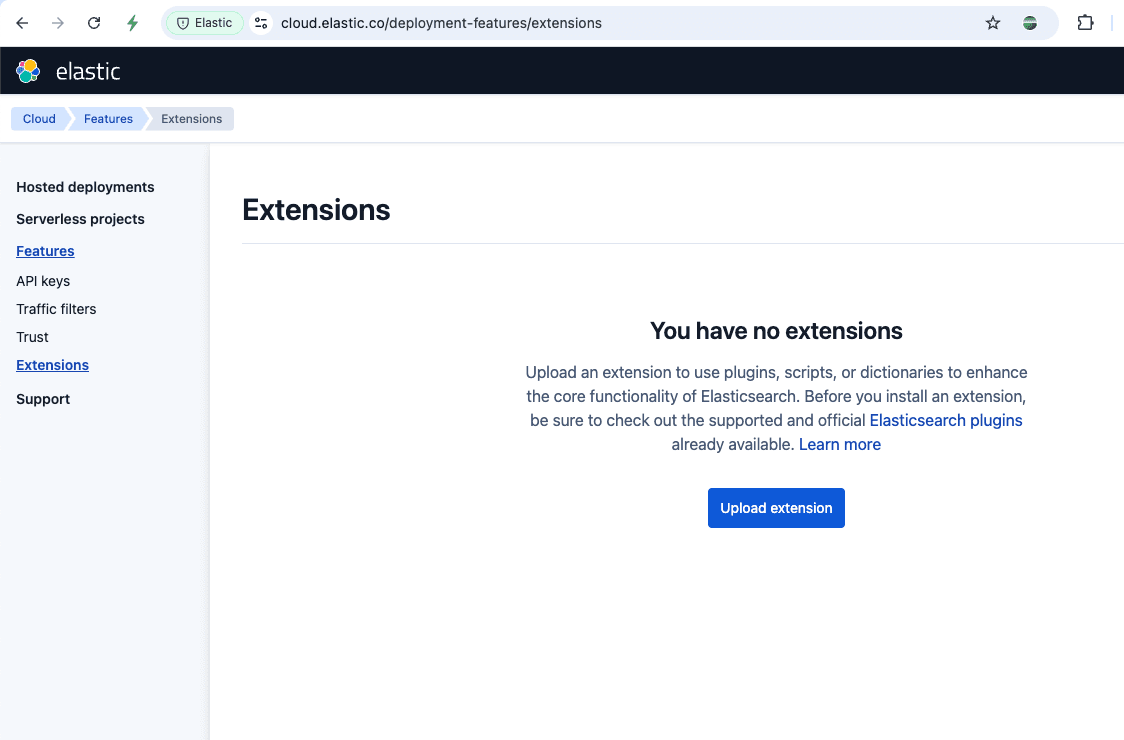
- 点击“上传扩展”,选择 elasticsearch-ubi-1.0.0-SNAPSHOT.zip 文件,并填写详细信息。撰写本文时,插件的 Elasticsearch 版本为 8.15.2,因此你必须使用该版本或为其他版本编译。你可以通过查看 gradle.properties 文件来检查插件最新代码的 Elasticsearch 版本。
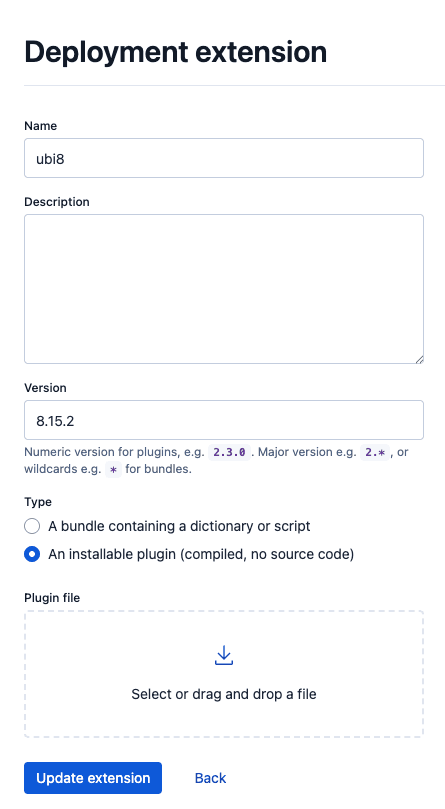
- 成功上传扩展后,点击 Elastic 标志 返回 Elastic Cloud 主页面
- 在你的工作部署中,点击 管理
- 点击 操作 下拉菜单,然后点击 编辑部署
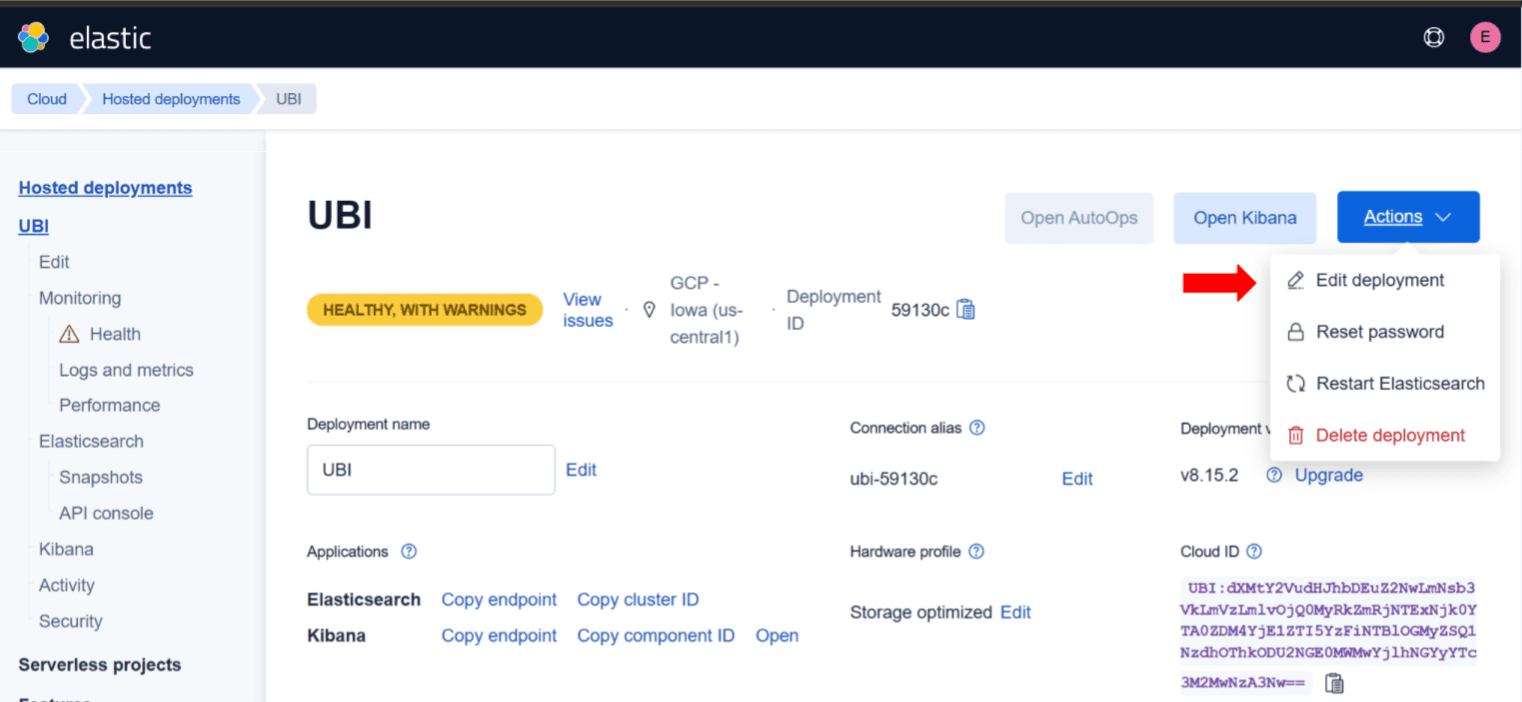
- 在 Elasticsearch 下,点击 管理用户设置和扩展 链接
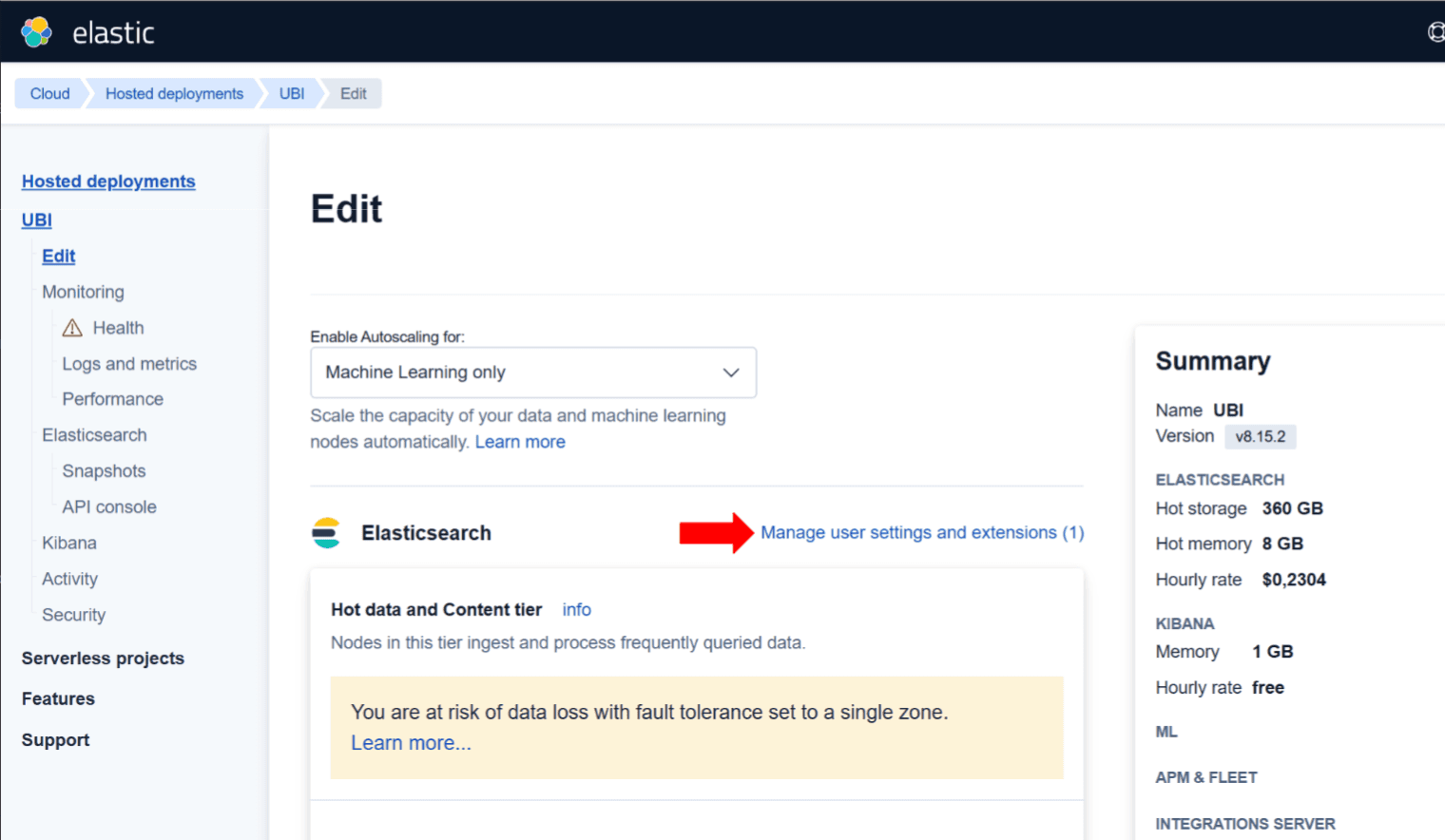
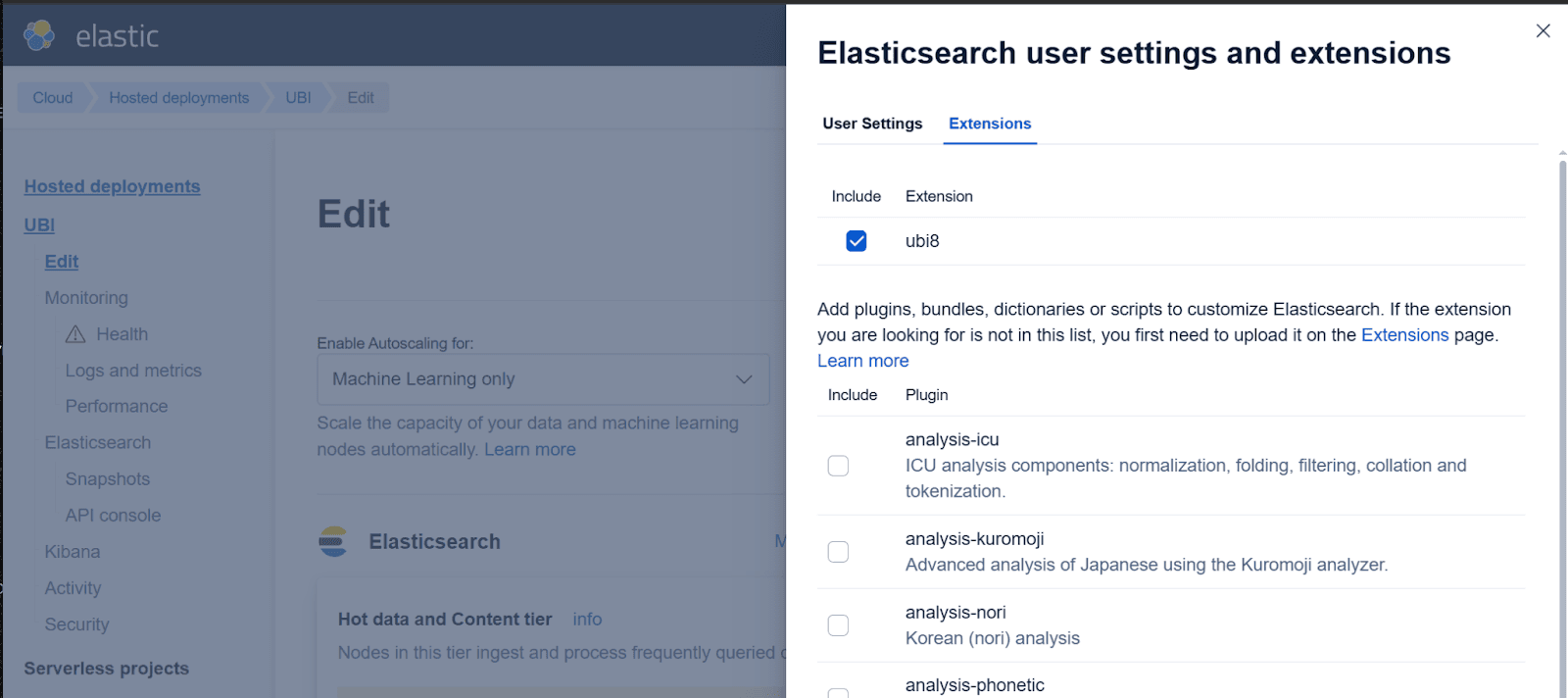
- 点击 扩展 标签,选择最近安装的扩展。在本例中,它是 ubi8。然后,点击“返回”并保存更改。
加载示例数据
在 Kibana DevTools 控制台中运行以下命令,加载几本书以测试插件。这将为本示例创建一个名为“books”的新索引。
POST /_bulk
{ "index" : { "_index" : "books" } }
{"name": "Snow Crash", "author": "Neal Stephenson", "release_date": "1992-06-01", "page_count": 470, "price": 14.99, "url": "https://www.amazon.com/Snow-Crash-Neal-Stephenson/dp/0553380958/", "image_url": "https://m.media-amazon.com/images/I/81p4Y+0HzbL._SY522_.jpg", "_extract_binary_content": true, "_reduce_whitespace": true, "_run_ml_inference": true}
{ "index" : { "_index" : "books" } }
{"name": "Revelation Space", "author": "Alastair Reynolds", "release_date": "2000-03-15", "page_count": 585, "price": 16.99, "url": "https://www.amazon.com/Revelation-Space-Alastair-Reynolds/dp/0441009425/", "image_url": "https://m.media-amazon.com/images/I/61nC2ExeTvL._SY522_.jpg", "_extract_binary_content": true, "_reduce_whitespace": true, "_run_ml_inference": true}
{ "index" : { "_index" : "books" } }
{"name": "1984", "author": "George Orwell", "release_date": "1985-06-01", "page_count": 328, "price": 12.99, "url": "https://www.amazon.com/1984-Signet-Classics-George-Orwell/dp/0451524934/", "image_url": "https://m.media-amazon.com/images/I/71rpa1-kyvL._SY522_.jpg", "_extract_binary_content": true, "_reduce_whitespace": true, "_run_ml_inference": true}
{ "index" : { "_index" : "books" } }
{"name": "Fahrenheit 451", "author": "Ray Bradbury", "release_date": "1953-10-15", "page_count": 227, "price": 11.99, "url": "https://www.amazon.com/Fahrenheit-451-Ray-Bradbury/dp/1451673310/", "image_url": "https://m.media-amazon.com/images/I/61sKsbPb5GL._SY522_.jpg", "_extract_binary_content": true, "_reduce_whitespace": true, "_run_ml_inference": true}
{ "index" : { "_index" : "books" } }
{"name": "Brave New World", "author": "Aldous Huxley", "release_date": "1932-06-01", "page_count": 268, "price": 12.99, "url": "https://www.amazon.com/Brave-New-World-Aldous-Huxley/dp/0060850523/", "image_url": "https://m.media-amazon.com/images/I/71GNqqXuN3L._SY522_.jpg", "_extract_binary_content": true, "_reduce_whitespace": true, "_run_ml_inference": true}
{ "index" : { "_index" : "books" } }
{"name": "The Handmaid's Tale", "author": "Margaret Atwood", "release_date": "1985-06-01", "page_count": 311, "price": 13.99, "url": "https://www.amazon.com/Handmaids-Tale-Margaret-Atwood/dp/038549081X/", "image_url": "https://m.media-amazon.com/images/I/61su39k8NUL._SY522_.jpg", "_extract_binary_content": true, "_reduce_whitespace": true, "_run_ml_inference": true}测试插件
调用 _search API 时,你可以发送一个额外的 ext 参数——一个包含文章开头描述的字段的对象。
索引查询
让我们编写一个查询并使用插件来捕获行为元数据。
GET books/_search
{
"query": {
"match": {
"name": "Snow"
}
},
"ext": {
"ubi": {
"object_id_field": "url",
"user_query": "snow",
"client_id": "web_application",
"query_attributes": {
"app_component": "global_header"
}
}
}
}object_id_field:用于识别结果并将其作为结果集存储在 ubi_queries 索引中的字段。
user_query:用户在搜索栏输入的内容。
client_id:查询的发起者。
query_attributes:任意键/值对。
查询响应将包含一个 query_id,可用于检查 ubi_queries 索引:
{
"ext": {
"ubi": {
"query_id": "cb26ba2c-27ab-4af3-905b-00aff928cf50"
}
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.5904956,
"hits": [
{
"_index": "books",
"_id": "Ep2h4ZcBDN5ljpdU06rw",
"_score": 1.5904956,
"_source": {
"name": "Snow Crash",
"author": "Neal Stephenson",
"release_date": "1992-06-01",
"page_count": 470,
"price": 14.99,
"url": "https://www.amazon.com/Snow-Crash-Neal-Stephenson/dp/0553380958/",
"image_url": "https://m.media-amazon.com/images/I/81p4Y+0HzbL._SY522_.jpg",
"_extract_binary_content": true,
"_reduce_whitespace": true,
"_run_ml_inference": true
}
}
]
}
}存储在 ubi_queries 中的文档将如下所示:
{
"_index": "ubi_queries",
"_id": "HJ204ZcBDN5ljpdUKKo2",
"_score": 4.7303333,
"_source": {
"query_response_id": "59474463-5862-4941-992e-50cafc294274",
"user_query": "snow",
"query_id": "cb26ba2c-27ab-4af3-905b-00aff928cf50",
"query_response_object_ids": [
"https://www.amazon.com/Snow-Crash-Neal-Stephenson/dp/0553380958/"
],
"query": """{
"query": {
"match": {
"name": {
"query": "Snow"
}
}
},
"ext": {
"query_id": "cb26ba2c-27ab-4af3-905b-00aff928cf50",
"user_query": "snow",
"client_id": "web_application",
"object_id_field": "url",
"query_attributes": {
"app_component": "global_header"
}
}
}""",
"query_attributes": {
"app_component": "global_header"
},
"client_id": "web_application",
"timestamp": 1751838369845
}
}这个文档包含了 Elasticsearch 执行的查询、我们提供的元数据、匹配的文档列表,以及查询响应的额外标识符。
通过这些数据,我们可以分析诸如热门查询、无结果热门查询、结果集中最热门的文档等趋势,并应用基于客户端应用程序、应用程序组件和时间的过滤器。
捕获事件
假设在相同的搜索中,用户点击了其中一个结果,我们希望捕获这个事件并将其与我们刚刚索引的查询关联起来。为了捕获客户端事件(例如,点击结果),应用程序必须将事件发送到 ubi_events 索引:
POST ubi_events/_doc
{
"action_name": "click",
"query_id": "cb26ba2c-27ab-4af3-905b-00aff928cf50",
"client_id": "web_application",
"timestamp": "2025-05-09T19:56:55.579Z",
"message_type": "CLICK_THROUGH",
"message": "Clicked Snow Crash",
"user_query": "snow",
"event_attributes": {
"object": {
"object_id": "Ep2h4ZcBDN5ljpdU06rw"
},
"position": {
"ordinal": 1
}
}
}我们现在捕获了该文档、该搜索的点击、位置(position.ordinal),以及 id 的原始值 (object_id)。
这个事件使我们能够识别最常被点击的文档、产生最多点击的用户查询,以及用户是否点击了处于顶部位置的结果。
洞察分析
我们可以使用 ES|QL 来分析我们的数据。让我们通过在 ubi_queries 索引中按 user_query 统计文档数量来寻找前 5 名查询:
POST /_query?format=txt
{
"query": """
FROM ubi_queries
| STATS count = COUNT(*) BY user_query
| SORT count DESC
| LIMIT 5
"""
}你将会得到如下表格格式的结果:
count | user_query
---------------+---------------
54 |fahrenheit
14 |snow
9 |summer books
4 |top seller
2 |alastair总结
在这篇文章中,我们学习了如何使用 Elasticsearch 插件捕获 UBI 查询和事件,以及如何利用基本字段提取有意义的洞察。
在接下来的文章中,我们将进一步探讨如何捕获更丰富的元数据、编写更高级的 ES|QL 查询,以及构建 Kibana 仪表板,以帮助我们更好地理解用户并提供改进的搜索体验。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号