(Pandas)Python做数据处理必选框架之一!(二):附带案例分析;刨析DataFrame结构和其属性;学会访问具体元素;判断元素是否存在;元素求和、求标准值、方差、去重、删除、排序...

(Pandas)Python做数据处理必选框架之一!(二):附带案例分析;刨析DataFrame结构和其属性;学会访问具体元素;判断元素是否存在;元素求和、求标准值、方差、去重、删除、排序...

凉凉心.
发布于 2025-10-13 17:52:32
发布于 2025-10-13 17:52:32
DataFrame结构
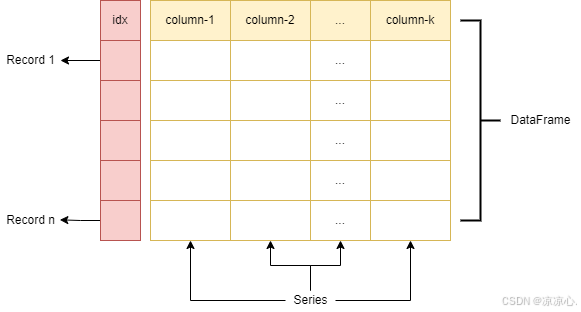
每一列都属于Series类型,不同列之间数据类型可以不一样,但同一列的值类型必须一致。
DataFrame拥有一个总的 idx记录列,该列记录了每一行的索引
创建DataFrame
import pandas as pd
import numpy as np
s1 = pd.Series([1,2,3,4,5])
s2 = pd.Series([6,7,8,9,10])
df = pd.DataFrame({'key1':s1,'key2':s2})
print(df)
'''
key1 key2
0 1 6
1 2 7
2 3 8
3 4 9
4 5 10
'''
# 字典创建
df2 = pd.DataFrame({
'col1': pd.Series(['a','b']),
'col2': pd.Series([1,2,3])
},index=[5,3,1,2],columns=['col2','col1'])
print(df2)
'''
col2 col1
5 NaN NaN
3 NaN NaN
1 2.0 b
2 3.0 NaN
'''在DataFrame中,若列之间的元素个数不匹配,且使用Series填充时,在DataFrame里空值会显示为NaN
当列之间元素个数不匹配,并且不使用Series填充,会报错
df2 = pd.DataFrame({
'col1': ['a','b'],
'col2': [1,2,3]
},index=[5,3,1,2],columns=['col2','col1'])报错: Check the length of data matches the length of the index.
ValueError: Length of values (3) does not match length of index (4)
在指定了index 属性显示情况下,会按照index的位置进行排序,默认是 [0,1,2,3,...] 从0索引开始正序排序行。当指定index后,指定的index记录不存在值,则回填NaN
同时columns属性也是一样,指定列名按照给定的 columns 数组顺序排序。
- 若指定columns列不存在,则回填
NaN
正常数据:
student = pd.DataFrame({
'name': ['zhangsan','lisi','wangwu'],
'age':[18,15,17],
'sex':['男','女','男'],
},index=[0,1,2],columns=['name','sex','age'])
print(student)
'''
name sex age
0 zhangsan 男 18
1 lisi 女 15
2 wangwu 男 17
'''DataFrame属性
属性 | 说明 | 属性 | 说明 |
|---|---|---|---|
index | DataFrame的索引对象 | size | DataFrame的元素个数 |
values | DataFrame的值 | loc[] | 显示索引,按行列标签索引或切片 |
dtypes | DataFrame的元素类型 | iloc[] | 隐式索引,按行列标签索引或切片 |
shape | DataFrame的形状 | at[] | 使用行列标签访问单个元素 |
ndim | DataFrame的维度 | iat[] | 使用行列位置访问单个元素 |
T | 行列转置 |
基本信息
print('行索引:',student.index)
print('列标签:',student.columns)
print('值:')
print(student.values)
'''
行索引: Index([0, 1, 2], dtype='int64')
列标签: Index(['name', 'sex', 'age'], dtype='object')
值:
[['zhangsan' '男' 18]
['lisi' '女' 15]
['wangwu' '男' 17]]
'''
print(student.T.values) # 转置后可以获得每一列的值
'''
[['zhangsan' 'lisi' 'wangwu']
['男' '女' '男']
[18 15 17]]
'''
print(student.name.values) # 获得指定列的值
# ['zhangsan' 'lisi' 'wangwu']print('形状:',student.shape)
print('维度:',student.ndim)
print('元素个数:',student.size)
print('元素类型:')
print(student.dtypes)
'''
形状: (3, 3)
维度: 2
元素个数: 9
元素类型:
name object
sex object
age int64
dtype: object
'''行列转置
student.T
'''
0 1 2
name zhangsan lisi wangwu
sex 男 女 男
age 18 15 17
'''获取元素
'''
name sex age
1 zhangsan 男 18
2 lisi 女 15
3 wangwu 男 17
'''
# 获取元素 loc iloc at iat
# 获取某行 loc包含0内,是真正的第x行;iloc则是索引值来取
print('loc',student.loc[2])
'''
loc name lisi
sex 女
age 15
Name: 2, dtype: object
'''
print('iloc',student.iloc[2])
'''
iloc name wangwu
sex 男
age 17
Name: 3, dtype: object
'''loc[row,col],若没有逗号隔开,默认填写的是row
当填写字符串时,DataFrame找的是col,而没有row时就会报错,所以,下列写法是错误的
student.loc['name']筛选指定列:
student.loc[:,'name'] # 'name'列的所有行
student.loc[2:,'age'] # 从第2行开始到结束的 age列 的行内容
student.loc[:2,'sex']
student.loc[1:2,['name','age']] # 获得从1到2行的name、age列信息
student.loc[1:2,'name':'age'] # 获得从 1到2行 的 name到age列 的信息iloc也可以做到,只是将显示的列名,换成了索引
获取单个元素
- loc和iloc的获取方法
student.iloc[1,0] # lisi
student.loc[1,'name'] # zhangsan本质就是二维数组,确定行列即可获得单个元素
- at 和 iat
与loc使用一致,不过只能用于获取单个元素
print(student.at[1,'age']) # 18
print(student.iat[0,0]) # zhangsan访问元素
# 获取单列数据
print(student['name']) # 返回Series
print(student.name) # 返回Series
print(student.loc[:,'name']) # 返回Series
print(student[['name']]) # DataFrame
print(student[['name','age']]) # DataFrame直接用中括号访问列名,可以获得对应列的数据
- 使用
.调出对应列也可以获得对应列的数据 - 两种方法,与上文使用
loc[:,x]获取列数据是一样的
若嵌套数组获得列,则可以筛选多个列出来,但返回出来的类型是DataFrame
筛选
student[student.age>17]
i = a.score.sort_values(ascending=False).index[0]
a.iloc[i] # 根据索引找到对应行与SQL语言一致,将DataFrame看成数据库来使用会更易于理解
常用方法:
方法 | 说明 | 方法 | 说明 |
|---|---|---|---|
head() | 查看前n行数据,默认5行 | max() | 最大值 |
tail() | 查看后n行数据,默认5行 | var() | 方差 |
isin() | 判断元素是否包含在参数集合中 | std() | 标准差 |
isna() | 判断是否未缺失值(如 NaN 或 None) | median() | 中位数 |
sum() | 求和,自动忽略缺失值 | mode() | 众数(可返回多个) |
mean() | 平均值 | quantile(a) | 分位数,a取0~1之间 |
min() | 最小值 | describe() | 常见统计信息(count、mean、std、min、25%、50%、75%、max) |
value_counts() | 每个唯一值的出现次数 | sort_values() | 按值排序 |
count() | 非缺失值数量 | sort_index() | 按索引排序 |
nunique() | 唯一值个数(去重) | unique() | 获取去重后的值数组 |
drop_duplicates() | 去除重复项 | sample() | 随机抽样 |
replace() | 替换值 | groupby() | 根据列名进行分组 |
nlargest() | 返回某列最大的n条数据 | nsmallest() | 放回某列最小的n条数据 |
判断存在
print(student.isin(['zhangsan'])) # 判断student中是否含有'zhangsan'的元素
'''
name sex age addr
1 True False False False
2 False False False False
3 False False False False
'''
student['addr'] = pd.Series(['','长沙','广州']) # 因为student中的索引是1开始,而新添加的Series索引从0开始,所以索引0处会在DataFrame中抹去;这里索引0填一个空值即可
print(student.isna()) # 判断student中是否NaN
'''
name sex age addr
1 False False False False
2 False False False True
3 False False False True
'''求和、标准值…
print(student.age.sum()) # 求和
print(student.age.max()) # 最大值
print(student.age.min()) # 最小值
print(student.age.var()) # 方差
print(student.age.std()) # 标准差
print(student.age.mean()) # 平均值
print(student.age.mode()) # 众数
print(student.age.quantile(0.25)) # 分位数
'''
50
18
15
2.3333333333333335
1.5275252316519468
16.666666666666668
0 15
1 17
2 18
Name: age, dtype: int64
16.0
'''信息
a = pd.DataFrame({
'name':pd.Series(['zhangsan','lisi','wangwu','zhaogang','liumin','jack','tom']),
'sex':pd.Series(['男','女','女','女','男','女','男']),
'age':pd.Series([18,20,22,19,16,19,18]),
'score':pd.Series([66.6,88.1,90,95,88.2,75.5,50]),
'class':pd.Series(['A','B','A','C','C','B','A'])
})
a
print(a.describe())
'''
age score
count 7.000000 7.000000
mean 18.857143 79.057143
std 1.864454 16.080201
min 16.000000 50.000000
25% 18.000000 71.050000
50% 19.000000 88.100000
75% 19.500000 89.100000
max 22.000000 95.000000
'''次数与重复次数
print(a.count())
print(a.value_counts())
'''
name 7
sex 7
age 7
score 7
class 7
dtype: int64
name sex age score class
jack 女 19 75.5 B 1
lisi 女 20 88.1 B 1
liumin 男 16 88.2 C 1
tom 男 18 50.0 A 1
wangwu 女 22 90.0 A 1
zhangsan 男 18 66.6 A 1
zhaogang 女 19 95.0 C 1
Name: count, dtype: int64
'''去重与检查重复数值
print(a.drop_duplicates())# 去除重复值
print(a.duplicated()) # 检查是否重复
print(a.duplicated(subset=['class']))
'''
0 False
1 False
2 True
3 False
4 True
5 True
6 True
7 True
dtype: bool
'''替换和累计和
print(a.replace('jack','rix'))
'''
name sex age score class
0 zhangsan 男 18 66.6 A
1 lisi 女 20 88.1 B
2 wangwu 女 22 90.0 A
3 zhaogang 女 19 95.0 C
4 liumin 男 16 88.2 C
5 rix 女 19 75.5 B
6 tom 男 18 50.0 A
7 rix 女 19 75.5 B
'''累积和:cumsum()
print(a.cumsum())
'''
0 66.6
1 154.7
2 244.7
3 339.7
4 427.9
5 503.4
6 553.4
7 628.9
Name: score, dtype: float64
'''
print(a.score.cumsum())
'''
name sex age score class
0 zhangsan 男 18 66.6 A
1 zhangsanlisi 男女 38 154.7 AB
2 zhangsanlisiwangwu 男女女 60 244.7 ABA
3 zhangsanlisiwangwuzhaogang 男女女女 79 339.7 ABAC
4 zhangsanlisiwangwuzhaogangliumin 男女女女男 95 427.9 ABACC
5 zhangsanlisiwangwuzhaogangliuminjack 男女女女男女 114 503.4 ABACCB
6 zhangsanlisiwangwuzhaogangliuminjacktom 男女女女男女男 132 553.4 ABACCBA
7 zhangsanlisiwangwuzhaogangliuminjacktomjack 男女女女男女男女 151 628.9 ABACCBAB
'''按列累计和,若存在字符串,那么字符串之间也会累计追加;
- 按行累计和,若一行中存在字符串,会报错
排序
print(a.sort_index(ascending=False)) # 根据索引值倒叙排序
'''
name sex age score class
7 jack 女 19 75.5 B
6 tom 男 18 50.0 A
5 jack 女 19 75.5 B
4 liumin 男 16 88.2 C
3 zhaogang 女 19 95.0 C
2 wangwu 女 22 90.0 A
1 lisi 女 20 88.1 B
0 zhangsan 男 18 66.6 A
'''print(a.sort_values(by='score'))
print(a.sort_values(by=['score','age'],ascending=[True,False]))
'''
name sex age score class
6 tom 男 18 50.0 A
0 zhangsan 男 18 66.6 A
5 jack 女 19 75.5 B
7 jack 女 19 75.5 B
1 lisi 女 20 88.1 B
4 liumin 男 16 88.2 C
2 wangwu 女 22 90.0 A
3 zhaogang 女 19 95.0 C
name sex age score class
6 tom 男 18 50.0 A
0 zhangsan 男 18 66.6 A
5 jack 女 19 75.5 B
7 jack 女 19 75.5 B
1 lisi 女 20 88.1 B
4 liumin 男 16 88.2 C
2 wangwu 女 22 90.0 A
3 zhaogang 女 19 95.0 C
'''还有一种方式可以对单列排序
a.score.sort_values(ascending=False)
'''
3 95.0
2 90.0
4 88.2
1 88.1
7 75.5
5 75.5
0 66.6
6 50.0
Name: score, dtype: float64
'''最大值和最小值
print(a.nlargest(1,columns=['score'])) # 直接返回行
'''
name sex age score class
3 zhaogang 女 19 95.0 C
'''
print(a.nlargest(2,columns=['score','age']))
'''
name sex age score class
3 zhaogang 女 19 95.0 C
2 wangwu 女 22 90.0 A
'''
print(a.nsmallest(1,columns='score')) # 返回score最小值所在的行
'''
name sex age score class
6 tom 男 18 50.0 A
'''案例分析
学生成绩分析
场景:某班级的学生成绩数据如下,请完成以下任务:
- 计算每位学生的总分和平均分。
- 找出数学成绩高于90分或英语成绩高于85分的学生。
- 按总分从高到低排序,并输出前3名学生。
- 源码
data ={
'姓名':['张三','李四','王五','赵六','钱七'],'数学':[85,92,78,88,95],
'英语':[90,88,85,92,80],'物理':[75,80,88,85,90]}- 解题
# 计算每位学生的总分和平均分。
b['总分'] = b[['数学','英语','物理']].sum(axis=1)
b['平均分'] = b[['数学','英语','物理']].mean(axis=1)
print(b)
'''
姓名 数学 英语 物理 总分 平均分
0 张三 85 90 75 250 83.333333
1 李四 92 88 80 260 86.666667
2 王五 78 85 88 251 83.666667
3 赵六 88 92 85 265 88.333333
4 钱七 95 80 90 265 88.333333
'''# 找出数学成绩高于90分或英语成绩高于85分的学生。
b[(b['数学']>90) | (b['英语']>85)]
'''
姓名 数学 英语 物理 总分 平均分
0 张三 85 90 75 250 83.333333
1 李四 92 88 80 260 86.666667
3 赵六 88 92 85 265 88.333333
4 钱七 95 80 90 265 88.333333
'''# 按总分从高到低排序,并输出前3名学生。
b.sort_values(by='总分',ascending=False).head(3)
'''
姓名 数学 英语 物理 总分 平均分
4 钱七 95 80 90 265 88.333333
3 赵六 88 92 85 265 88.333333
1 李四 92 88 80 260 86.666667
'''销售数据分析
场景:某公司销售数据如下,请完成以下任务:
- 计算每种产品的总销售额(销售额 = 单价 x 销量)
- 找出销售额最高的产品。
- 按销售额从高到低排序,并输出所有产品信息。
- 源码
data ={
'产品名称':['A','B','C','D'],'单价':[100,150,200,120],'销量':[50,30,20,40]
}
df = pd.DataFrame(data)
'''
产品名称 单价 销量
0 A 100 50
1 B 150 30
2 C 200 20
3 D 120 40
'''- 解码
# 计算每种产品的总销售额(销售额 = 单价 x 销量)
df['总销售额'] = df['单价'] * df['销量']
print(df)
'''
产品名称 单价 销量 总销售额
0 A 100 50 5000
1 B 150 30 4500
2 C 200 20 4000
3 D 120 40 4800
'''# 找出销售额最高的产品。
# df.sort_values('总销售额').tail(1)
df.nlargest(1,columns='总销售额')
'''
产品名称 单价 销量 总销售额
0 A 100 50 5000
'''# 按销售额从高到低排序,并输出所有产品信息。
df.sort_values('总销售额',ascending=False)
'''
产品名称 单价 销量 总销售额
0 A 100 50 5000
3 D 120 40 4800
1 B 150 30 4500
2 C 200 20 4000
'''电商用户行为分析
场景:某电商平台的用户行为数据如下,请完成以下任务:
- 计算每位用户的总消费金额(消费金额 = 商品单价 x 购买数量)
- 找出消费金额最高的用户,并输出其所有信息
- 计算所有用户的平均消费金额(保留2位小数)
- 统计电子产品的总购买数量
- 源码:
data ={
'用户ID':[101,102,103,104,105],
'用户名':['Alice','Bob','Charlie','David','Eve'],
'商品类别':['电子产品','服饰','电子产品','家居','服饰'],
'商品单价':[1200,300,800,150,200],'购买数量':[1,3,2,5,4]
}
df = pd.DataFrame(data)
print(df)
'''
用户ID 用户名 商品类别 商品单价 购买数量
0 101 Alice 电子产品 1200 1
1 102 Bob 服饰 300 3
2 103 Charlie 电子产品 800 2
3 104 David 家居 150 5
4 105 Eve 服饰 200 4
'''- 解码
# 计算每位用户的总消费金额(消费金额 = 商品单价 x 购买数量)
df['总消费金额'] = df['商品单价'] * df['购买数量']
print(df)
'''
用户ID 用户名 商品类别 商品单价 购买数量 总消费金额
0 101 Alice 电子产品 1200 1 1200
1 102 Bob 服饰 300 3 900
2 103 Charlie 电子产品 800 2 1600
3 104 David 家居 150 5 750
4 105 Eve 服饰 200 4 800
'''# 找出消费金额最高的用户,并输出其所有信息
df.nlargest(1,'总消费金额')
'''
用户ID 用户名 商品类别 商品单价 购买数量 总消费金额
2 103 Charlie 电子产品 800 2 1600
'''# 计算所有用户的平均消费金额(保留2位小数)
df['总消费金额'].mean()
# np.float64(1050.0)# 统计电子产品的总购买数量
df.where(df['商品类别'] == '电子产品').dropna()['购买数量'].sum()
# np.float64(3.0)本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-08-15,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号