谷歌首席科学家Jeff Dean在斯坦福演讲中揭秘:塑造当今AI的6个惊人转折点
原创
谷歌首席科学家Jeff Dean在斯坦福演讲中揭秘:塑造当今AI的6个惊人转折点
原创
走向未来
发布于 2025-11-30 23:58:36
发布于 2025-11-30 23:58:36
谷歌首席科学家Jeff Dean在斯坦福演讲中揭秘:塑造当今AI的6个惊人转折点
走向未来
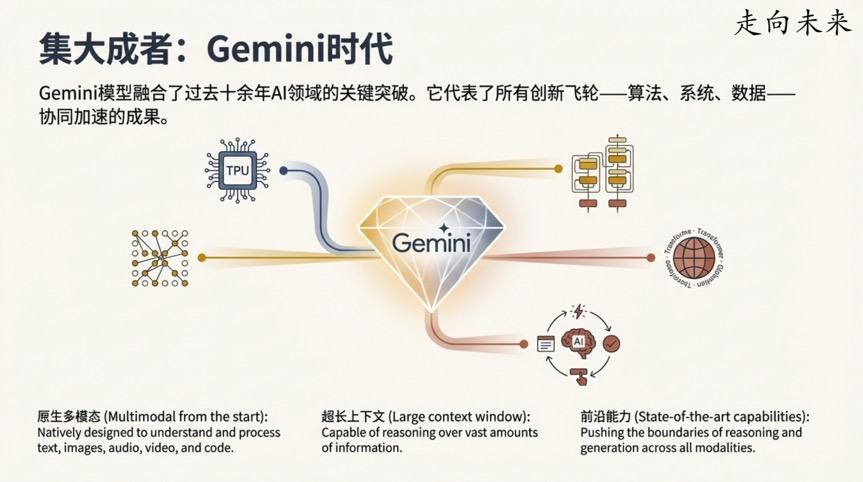
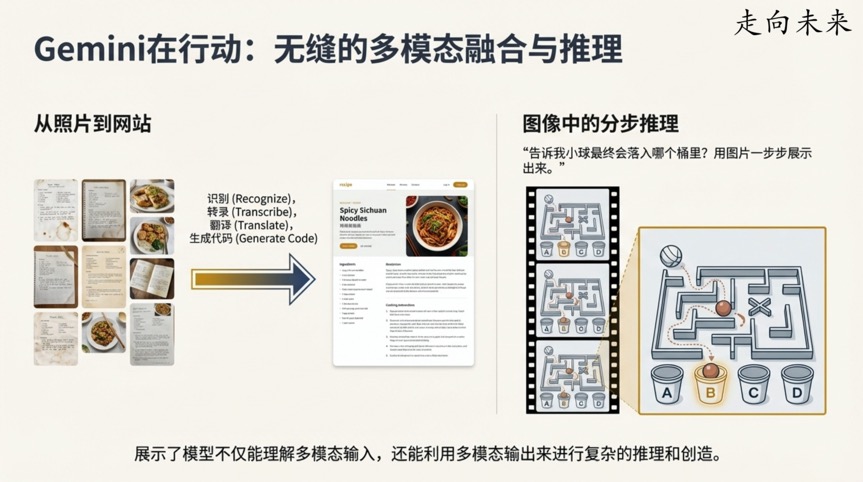
如今,像Gemini这样的人工智能模型所展现出的能力,常常让人感到不可思议。它们可以进行流畅的对话,理解复杂的图像,甚至编写代码。这不禁让我们好奇:我们是如何走到今天的?
这条路并非一帆风顺。早在1990年,当谷歌首席科学家Jeff Dean还是一名大学生时,他就对神经网络的并行训练着了迷,并以此为题完成了毕业论文。他当时认为,只要将计算能力提升32倍,就能训练出真正强大的神经网络。事后他感慨自己“完全错了”——实现今天的成就,需要的不是32倍,而是“一百万倍”的计算能力。
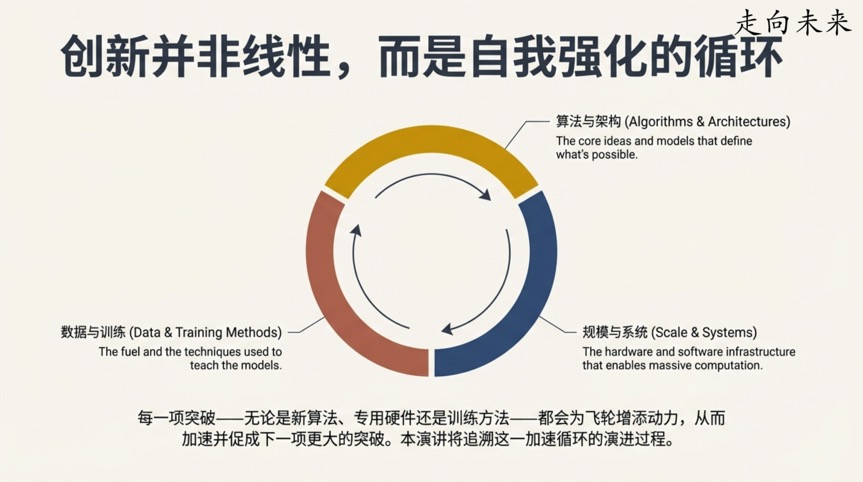
这个小插曲完美地预示了AI发展的核心主题:对计算规模的无尽渴求,以及为实现这一目标而诞生的种种巧思。从Jeff Dean的视角,我们将追溯一条由大胆假设、工程巧思和反直觉发现铺就的道路,理解这些关键时刻如何相互激荡,最终汇成了今日人工智能的滔天巨浪。
本文的内容来自Jeff Dean在斯坦福的演讲的总结。本文的PDF版本及相关资料都已收录到“走向未来“知识星球,推荐加入星球学习成长。
转折点一:AI的“猫咪神经元”——无需教导,机器竟能自学概念
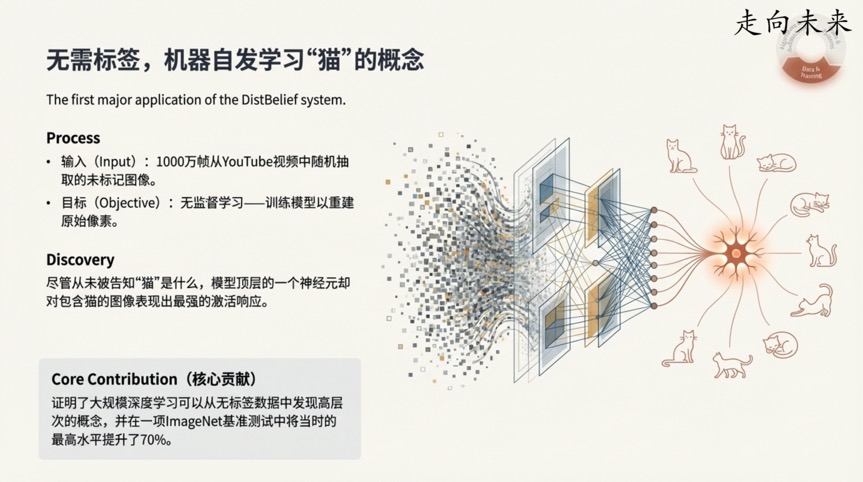
2012年,一项后来被称为“猫论文”(Cat Paper)的实验,成为了AI发展史上的一个重要里程碑。研究人员向一个庞大的神经网络展示了1000万个从YouTube视频中随机抽取的、没有任何标签的静态帧。他们没有告诉模型任何关于这些图像的信息。模型的唯一目标,是学习一种内部表示,以便能够根据输入图像,重建出原始的像素。
实验最惊人的发现是:在没有任何人工标注(即从未被告知“什么是猫”)的情况下,模型中自发地演化出了一个“神经元”,它对包含猫脸的图像反应最为强烈。
这一发现的重要性在于: 它首次有力地证明了,通过大规模的无监督学习,AI有能力从海量的原始数据中自行发现高层次、有意义的概念。这不仅仅是识别像素,而是开始理解“猫”这个抽象概念。这是AI理解世界方式的一次革命性展示,为后来的自监督学习奠定了基础。
转折点二:“数学上全错”的训练方法,却意外奏效
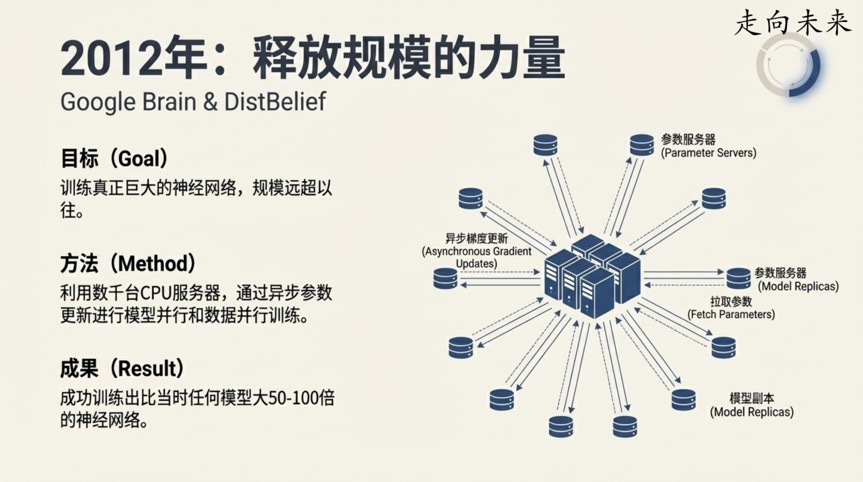
在Google Brain项目早期,为了训练比以往任何时候都大的神经网络,Jeff Dean和他的团队开发了一个名为“Disbelief”的分布式训练系统。该系统采用了一种名为“异步梯度更新”的核心机制。
简单来说,它允许多个模型的副本在不同的机器上同时工作,并异步地将自己的学习成果发回到一个共享的参数服务器。从严格的数学理论来看,这种做法是“完全错误的”(completely mathematically wrong),因为它允许各个计算节点基于可能已经过时的参数版本进行更新,理论上会造成混乱。
Jeff Dean在演讲中回忆道:
"这让很多人感到紧张,因为它实际上并不是你真正应该做的事情。但事实证明,它奏效了。"
这一发现的重要性在于: 它体现了AI领域一种极为务实的工程思维。有时,相比于坚守严格的理论正确性,能够有效扩展并行计算、在现实世界中获得结果的“野路子”更为关键。这种敢于挑战理论常规的精神,极大地加速了大规模模型训练的进程。
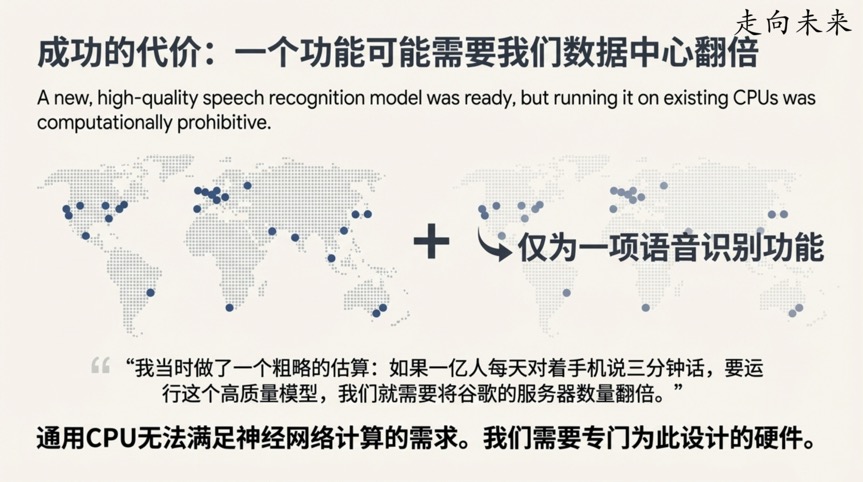
转折点三:一次简单的估算,催生了AI硬件革命
随着AI模型在语音识别等领域取得巨大成功,一个现实问题摆在了面前:计算成本。Jeff Dean做了一次著名的“餐巾纸背面计算”(back of the envelope calculation)。
他当时估算:如果全球有1亿用户,每人每天使用3分钟当时最新的高质量语音识别模型,那么为了支撑这项服务的计算需求,Google将需要将其数据中心的计算机数量翻倍。
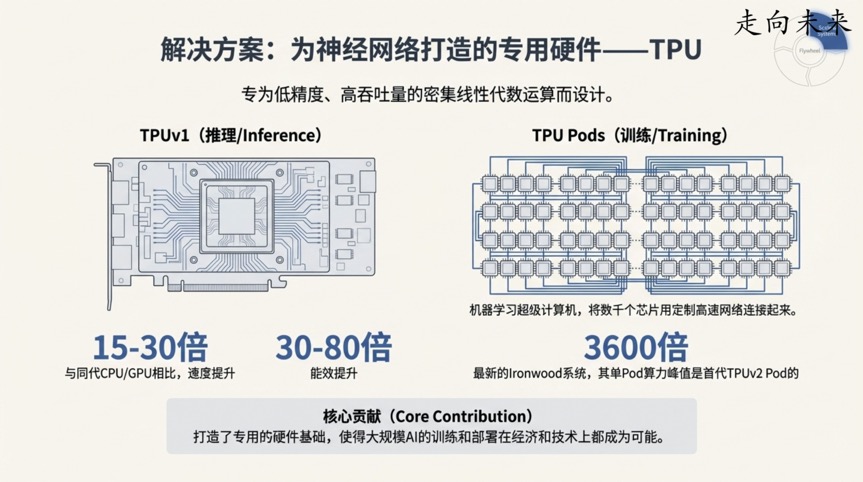
这个惊人的计算结果直接推动了Google研发专用AI硬件的决心,这便是TPU(张量处理单元)的由来。其效果立竿见影:第一代TPU在AI推理任务上的速度比当时的CPU和GPU快15到30倍,而能效则高出30到80倍。
这一发现的重要性在于: 它标志着AI的发展不再仅仅是算法和软件的进步,而是进入了软硬件协同设计的全新时代。专用硬件的出现,为之后参数量呈指数级增长的更大规模模型铺平了道路,是让训练未来那些难以想象的庞大模型成为可能的物质基础。
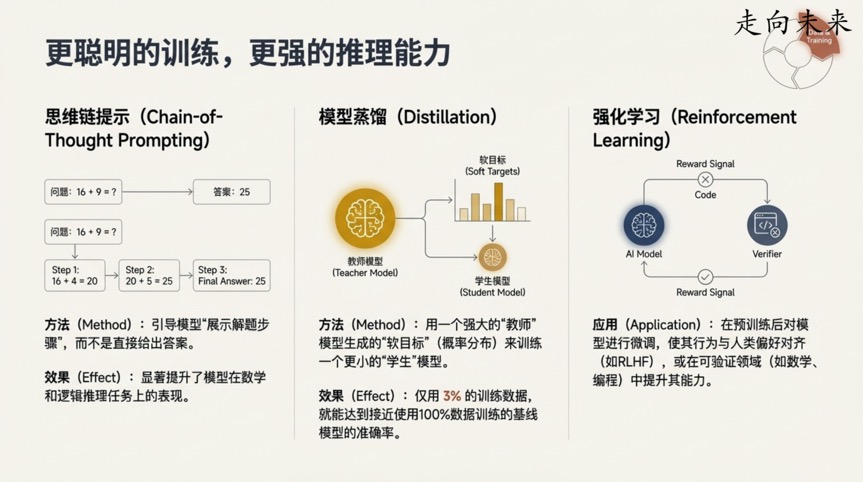
转折点四:AI也需“展示解题步骤”,从中学数学到奥赛金牌的飞跃
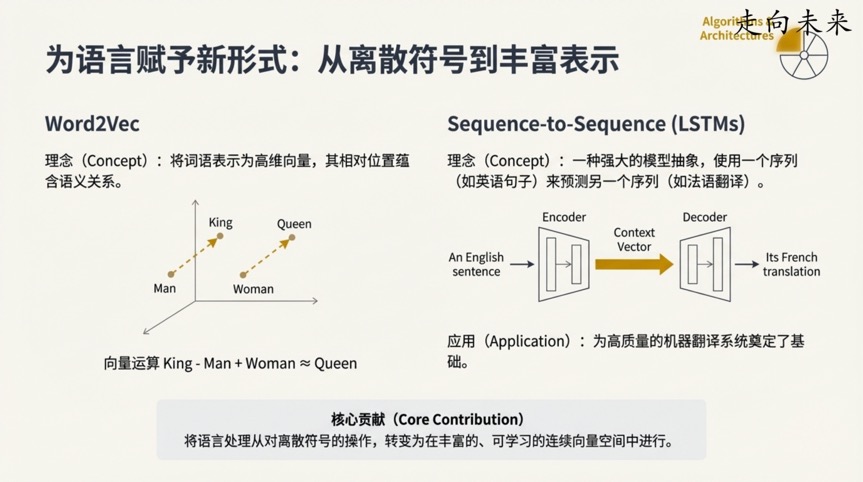
“思维链”(Chain-of-Thought)是一种看似简单却极其强大的提示技术。它的核心思想是,在要求模型给出最终答案之前,先引导它一步步地输出其推理过程,就像学生在做数学题时写下解题步骤一样。
Jeff Dean通过一个强烈的对比,展示了这项技术的神奇效果:仅仅在几年前(例如2022年左右),研究人员还在为AI模型能在中学生水平的数学问题上达到15%的正确率而兴奋不已。
然而,仅仅两年后,基于类似原理的Gemini模型,已经能够解决国际数学奥林匹克(IMO)竞赛中的高难度几何问题,并达到了金牌水平。
这一发现的重要性在于: 它表明AI的“思考”过程是可以被引导和优化的。正如Jeff Dean所解释的,一种理解方式是,通过输出中间步骤,模型为它生成的每一个词(token)都分配了更多的计算量,从而能利用更多的算力来推导出最终答案。仅仅是改变提问方式,让模型“思考得更慢、更深入”,就能极大地释放其解决复杂问题的潜力。
转折点五:AI“教师”的智慧传承——用3%的数据达成97%的效果
如何将一个巨大、耗能的模型所具备的强大能力,部署到资源有限的设备(如手机)上?“模型蒸馏”(Distillation)技术给出了一个绝佳的答案。
这个过程可以比作一位知识渊博的“教师”模型,将其复杂的“知识”——不仅仅是正确的答案,还包括对错误答案的判断(例如,知道“小提琴”是正确答案,也知道“钢琴”比“飞机”更有可能)——提炼并传授给一个更小的“学生”模型。
Jeff Dean在演讲中给出的数据极为震撼。在一个语音识别任务中,一个模型如果只用3%的训练数据,其准确率会跌至44%,远低于使用100%数据训练出的基线模型所达到的58.9%。然而,当引入蒸馏技术,让一个强大的“教师”模型来指导这个“学生”模型时,奇迹发生了:仅用同样的3%训练数据,学生模型的准确率飙升至57%,几乎追平了使用全部数据训练的基线模型!
这一发现的重要性在于: 蒸馏技术极大地提高了AI的效率和可及性。它使得我们能够将顶尖大模型的强大能力,压缩到可以在边缘设备上高效运行的小模型中,从而极大地促进了AI技术在现实世界中的普及和应用。
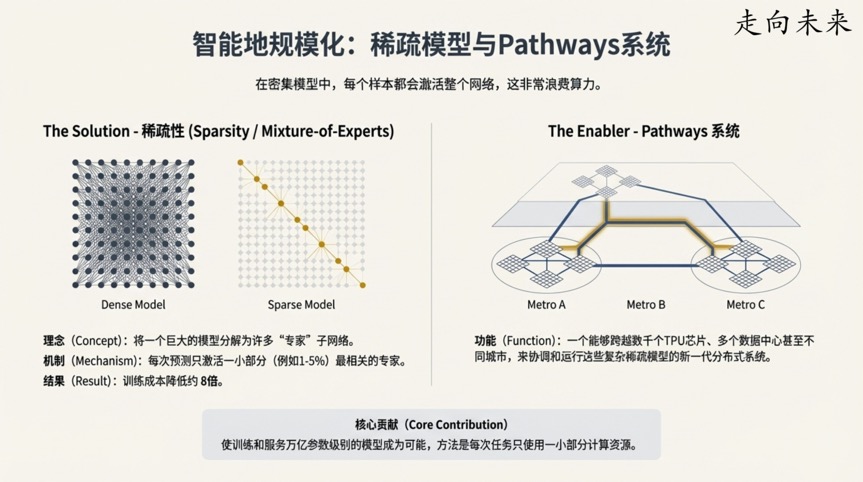
转折点六:稀疏模型的力量——AI巨人的“大脑”只在需要时才全力工作
传统的神经网络(或称“稠密模型”)在处理每一个任务时,都会激活其全部的参数,这就像让整个大脑同时思考所有问题一样,效率低下。而“稀疏模型”(Sparse Models)则彻底改变了这一点。
稀疏模型在处理任何一个给定的输入时,只会激活一小部分(例如1-5%)最相关的参数。这更像人类大脑的工作方式:当我们看图时,视觉皮层更活跃;当我们听音乐时,听觉皮层更活跃,而不是整个大脑同时满负荷运转。
这一发现的重要性在于: 稀疏化使得研究人员能够构建参数量极其庞大(达到万亿级别)的模型,同时将计算成本保持在可控范围内。Jeff Dean指出,稀疏模型在达到同等准确率时,可以将训练所需的计算成本降低约8倍。这种算法上的飞跃,正是为了更高效地利用像TPU这样的专用硬件所提供的巨大算力。像Gemini这样的现代顶尖模型,正是这种软硬件协同进化的杰出代表。
结论:下一个“反直觉”的突破在哪里?
回顾这六个里程碑,一幅清晰的画卷展现在我们面前。它们揭示了驱动现代AI的核心哲学:对计算规模的执着追求(如TPU和“Disbelief”系统),对数据能涌现出自身结构的坚定信念(如“猫论文”),以及一种务实的工程精神,愿意通过各种聪明的捷径——从“数学上错误”的方法,到算法层面的“蒸馏”和“稀疏”架构——来驾驭和释放这种规模的力量。
从相信机器能自学概念,到拥抱“理论上错误”的方法,再到为AI量身打造芯片,每一步都曾是大胆的假设,最终却都成为了通往未来的基石。
回顾这些充满惊喜的里程碑,我们不禁要问:在通往更强大人工智能的道路上,下一个颠覆我们认知的突破,将会是什么样的“反直觉”发现?

b/001.jpg
b/002.jpg
b/003.jpg
b/004.jpg
b/005.jpg
b/006.jpg
b/007.jpg

b/008.jpg

b/009.jpg
b/010.jpg
b/011.jpg
b/012.jpg

b/013.jpg
b/014.jpg

b/015.jpg
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者
