阿里、AMD、谷歌结盟狙击NVLink,UALink引领万卡集群新变革

阿里、AMD、谷歌结盟狙击NVLink,UALink引领万卡集群新变革

AGI小咖
发布于 2025-12-23 15:30:30
发布于 2025-12-23 15:30:30
1
从EthLink的星星之火到UALink的燎原之势
上一篇分享文章——《媲美英伟达下一代GPU Scale-up:字节版NVLink重塑MegaScale万卡集群网络?》中我们深度剖析了字节跳动如何像一位精准的外科医生,借助独创EthLink技术直击传统以太网(RoCEv2)在万卡集群中的三大痛点——应用层高昂的“软件变通”成本、单一通信语义的局限以及臃肿的协议开销与被动的故障感知——进行了根本性的手术。EthLink如同一道划破夜空的闪电,揭示了单一巨头凭借一己之力,亦能为AI互联的“终局之战”提出颠覆性的解法。
当整个行业都面临着被单一供应商“技术锁定”的共同焦虑时,个体的突围终将汇聚成时代的洪流。如果说EthLink是“独狼”式的先锋探索,那么Ultra Accelerator Link(UALink)联盟的诞生,由AMD、Astera Labs、AWS、思科、谷歌、HPE、英特尔、Meta和微软等“九大长老”共同发起的UALink推广组(Promoter Group),后来字节、腾讯、中兴、华三、ARM也相继加盟,标志着一场由行业巨头们联合发起的、有组织、有预谋的“反NVIDIA联盟”。

图1: UALink推广组成员 (Promoter Members)
接下来“AGI小咖”与您聚焦分享新鲜出炉的《UALink 1.0白皮书》与《UALink 200G 1.0规范》——不仅拆解其技术架构的精妙之处,更要绘制出其背后复杂的产业生态图景。
2
基于传统以太网(RoCEv2)部署万卡集群的三大痛点
正如UALink联盟《UALink 1.0白皮书》开篇摘要部分所言直指要害:“AI模型的急剧增长,对算力、内存和互联性能提出了更高的要求。交付可靠的规模化(Scale-up)解决方案的成本和复杂性,已成为整个行业的沉重负担。” ——这句话精准地概括了当前AI基础设施面临的三大核心痛点。
痛点一:难以承受的“NVIDIA税”与生态锁定
在高性能AI计算领域,NVIDIA的NVLink/NVSwitch和InfiniBand网络凭借其卓越性能,构建了一个近乎垄断的“围墙花园”。客户在享受极致性能的同时不得不接受接受高昂的成本、深度的厂商绑定以及有限的供应选择,被业界戏称为“NVIDIA税”成为悬在所有试图构建大规模AI集群的云厂商和企业头上的“达摩克利斯之剑”。
痛点二:“鱼与熊掌”的困境——开放的不够快,封闭的又太贵
正如上一篇我们分析过的字节跳动独创EthLink初衷是为了解决传统以太网(RoCEv2)在万卡集群中会遭遇协议开销臃肿、故障感知被动等先天不足的问题。而专为Scale-up设计的NVLink——Load/Store内存语义虽能实现极致的低延迟却又是一个封闭的黑盒。市场迫切需要一种方案——能兼顾以太网的开放与成本优势,同时具备私有协议的高效与可靠。
痛点三:软件复杂性的“雪崩”
为不同的专有硬件编写和优化软件栈是一项极其耗费资源的工作。随着硬件方案的碎片化,软件的复杂性呈指数级增长。行业需要一个统一、简洁的编程模型,将开发者从繁重的底层网络适配工作中解放出来。《UALink 1.0白皮书》关于软件模型与编程简易性的章节中明确提出“通过使用支持直接读、写、原子事务的内存语义,来降低软件复杂性”。
正是在这样的产业背景下,一场由阿里、AMD、谷歌、微软、Meta、英特尔、思科、HPE等行业巨头联合发起的UALink联盟打响了“破局之战”。
3
深度提纯——UALink的四大亮点工程
UALink的设计哲学不仅仅是对现有技术的修补,而是一次从物理层到协议层的系统性重构。
亮点一:自成一体“苹果生态” VS 开放包罗万象“安卓生态”
UALink最强大的武器并非某项技术指标,而是其背后星光熠熠的“联盟军”名单:阿里、AMD、谷歌、微软、Meta、英特尔、苹果、思科、字节、腾讯、中兴、华三…… 几乎涵盖了芯片设计、云计算、设备制造和软件生态的所有顶级玩家,堪称一场科技届发起的目标直指NVIDIA的护城河的“诺曼底登陆”。
如果说NVIDIA构建的是一个从芯片、网卡到交换机、软件都自成一体的“苹果式”封闭帝国;那么UALink联盟则是在打造一个AI硬件的“安卓生态”——通过制定开放标准,让所有玩家都能参与进来,共享利益,共同对抗“霸主”。
正如《UALink 1.0白皮书》关于成本效益与生态系统的章节所言:UALink核心战略是“通过利用现有的以太网基础设施,包括线缆、连接器、中继器和管理软件,来降低总体拥有成本(TCO)”。
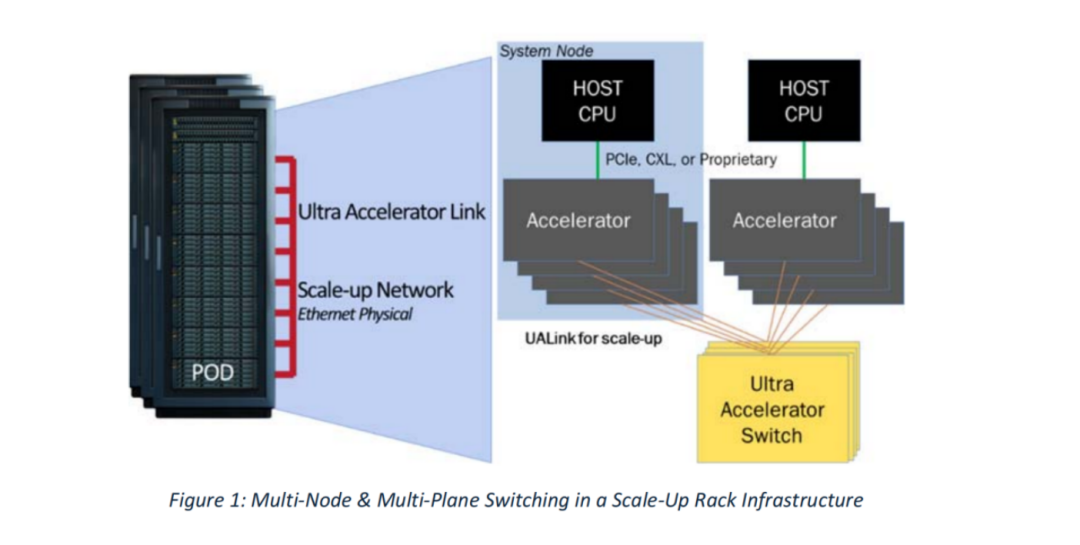
图2:多节点与多平面交换的机架级Scale-Up基础设施
亮点二:回归Load/Store内存语义为AI计算“减负”
正如《UALink 1.0白皮书》协议栈定义部分所言:UALink并非简单地把以太网用于GPU互联,它在保留以太网物理层(PHY)的基础上,设计了全新的数据链路层(DL)和事务层(TL),其核心是原生支持内存语义(Memory Semantics)。
传统的RDMA像“快递服务”,你需要打包数据、填写地址单(协议头),然后发送。而Load/Store内存语义则更像给了GPU一把“万能钥匙”,可以直接打开另一块GPU的内存“房间”,取走(Load)或放下(Store)东西。对于AI训练中大量的高频、小数据量同步和控制信令,这种“直接访问”的模式延迟极低、效率极高。
正如《UALink 1.0白皮书》关于可扩展性与编程模型的章节所言:UALink通过其协议层接口(UPLI)将这种简洁的编程模型标准化,确保上层软件(如NCCL等通信库)可以像访问本地内存一样访问集群中多达1024个加速器的远程内存,极大地简化了大规模并行计算的编程难度。
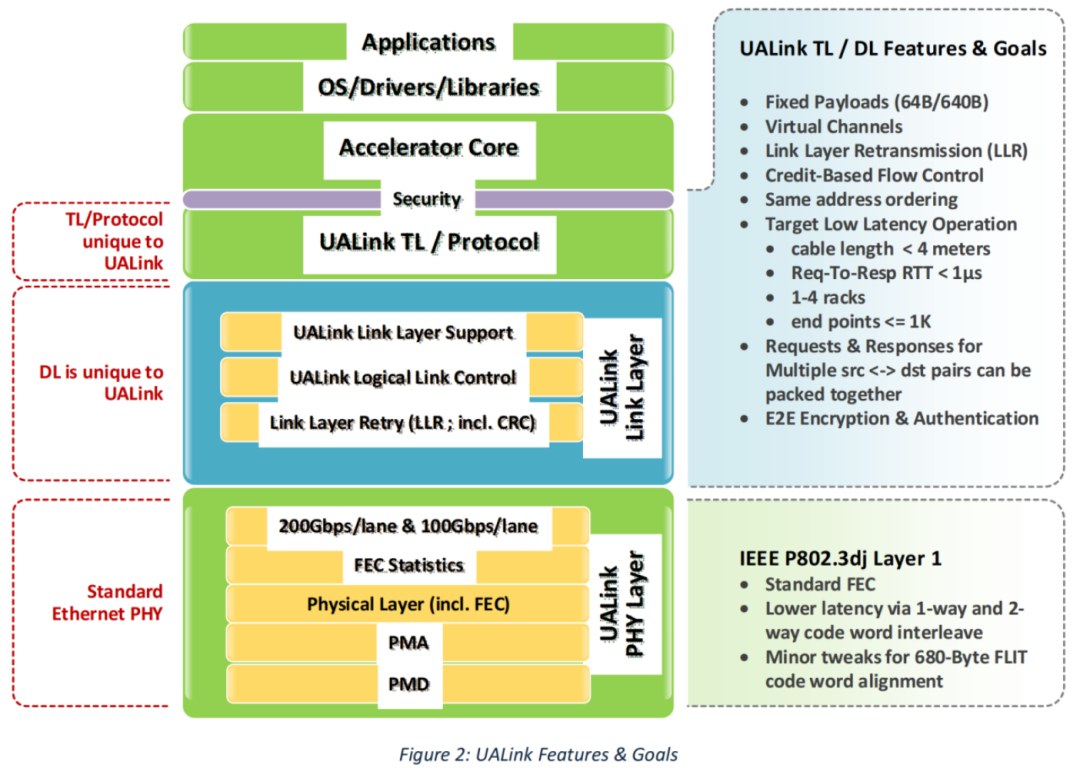
图3: UALink协议栈各层级的特性与目标
亮点三:软硬协同的“双保险”:LLR与端到端安全
为了在开放的以太网物理层上实现媲美私有网络的可靠性,UALink同样引入了“双保险”机制,这与上一篇分享过的字节跳动独创EthLink的设计思想不谋而合。
链路层重传 (Link Layer Retry, LLR)(硬件层面的“护卫舰”):
正如《UALink 1.0白皮书》数据链路层(Data Link Layer)功能描述部分所言——白皮书明确指出数据链路层包含LLR功能和CRC校验。当链路上出现CRC错误等物理丢包时,LLR机制能在硬件层面实现纳秒级的快速重传,避免了应用层秒级的漫长超时等待。
端到端安全 (UALinkSec)(应用层面的“安全锁”):
正如《UALink 1.0白皮书》关于安全(Security)特性的章节所言——建立端到端的加密与认证机制,保护数据在传输过程中不被窃听或篡改,在多租户共享集群和机密计算场景下确保了即便是基础设施提供商也无法窥探租户的数据。
亮点四:【落地】关键指标与产业承诺
正如《UALink 200G 1.0规范》物理层速率定义部分所言:UALink带宽为单通道数据速率为200 GT/s,由4个通道组成的“站(Station)”可提供800 Gbps的双向带宽。
正如《UALink 1.0白皮书》系统拓扑与可扩展性目标章节所言:UALink支持在单个AI Pod内连接多达1024个加速器端点,在集群规模上相比于NVIDIA Blackwell架构下NVLink Switch系统支持的576个GPU的规模有数量规模上的优势。
特性 | UALink 1.0 | NVIDIA 第五代 NVLink (Blackwell) | 洞察与分析 |
|---|---|---|---|
核心哲学 | 开放标准,内存语义 | 专有协议,垂直整合 | UALink赌的是生态协作和用户选择,而NVIDIA赌的是封闭体系下的极致性能和深度优化。“苹果生态”和“安卓生态”两种商业模式和技术路线的直接碰撞。 |
单GPU带宽 | 厂商自定义(例如通过多个800 Gbps端口) | 1.8 TB/s(双向) | NVLink凭借其软硬件一体化设计,在单GPU的账面带宽上占据优势。UALink的灵活性则允许厂商(如AMD)根据成本和性能需求自由选择端口数量。 |
最大规模(单Pod) | 1024 加速器 | 576 GPU(通过NVLink Switch) | UALink在集群规模上宣称拥有显著优势,这对于构建超大规模训练集群的云厂商而言,是一个极具吸引力的卖点,直击NVIDIA的核心优势区。 |
生态系统模式 | 多厂商(AMD、英特尔、Astera Labs、Marvell等) | 单厂商(仅NVIDIA) | UALink的承诺是构建一个交换机、加速器和IP的充分竞争市场。NVIDIA则提供“一站式”解决方案。这为客户创造了经典的TCO(总拥有成本)与性能/简易性的权衡。 |
关键可靠性特性 | 硬件级链路层重传(LLR) | 专有的、集成在网络中的机制 | 两者都追求无损网络:UALink的方案是标准化和透明的,旨在规避传统以太网流控的陷阱;NVIDIA的方案虽是“黑盒”,但已在多代产品中得到验证。 |
交换机延迟(目标) | 约100-150 ns | 极低 | 纳秒级的延迟竞赛至关重要:UALink的延迟目标极具野心,目标直指英伟达NVSwitch。 |
表1:UALink 1.0 vs. NVIDIA第五代NVLink
(表格中数据均源自《UALink 1.0白皮书》及《UALink 200G 1.0规范》)
4
一场开放生态的“阳谋”
4.1 生态圈:科技界的“诺曼底登陆”
UALink的成功与否不仅取决于技术规范的优劣,更依赖于一个强大而协同的生态系统。
冠军选手 (AMD): AMD是UALink联盟最核心的驱动者——久经沙场考验的Infinity Fabric协议是UALink规范的重要技术源头。AMD正通过实际行动将UALink从纸面规范落地为硅基产品:新一代Instinct MI350系列和即将推出的MI400系列加速器,以及基于Meta OCP设计的“Helios”机架级平台都将深度集成UALink技术。
军火巨头 (Marvell): Marvell在此生态中扮演了“军火商”的关键角色,为联盟提供构建硬件生态系统的基础IP(包括224G SerDes、UALink控制器IP以及交换机核心IP),进一步加速UALink规范的硅基产品化进程。
幕后推手 (谷歌、微软、Meta): 不仅仅是联盟成员,更是位列董事会的“决策者”,它们的参与向市场释放了一个无比清晰且强大的信号:全球最大的AI硬件采购方正在积极寻求NVIDIA之外的、开放的、多供应商的替代方案。
4.2 变数:网络巨头博通的“双面游戏”
“反NVIDIA联盟”中有一个角色的行为让战局变得扑朔迷离,它就是网络芯片巨头——博通(Broadcom)。作为UALink的创始推广者之一,博通却并未将所有筹码押在牌桌上,而是同时高调推出了自己的“统一以太网”方案(Scale-Up Ethernet, SUE),并且务实地将AMD等盟友早期的UALink系统构建于其现有的以太网交换芯片之上。
这一系列“亦敌亦友”的复杂操作,究竟是为UALink生态铺路的“权宜之计”,还是暗藏着“一统江湖”的更大野心?博通的“以太网阳谋”将如何影响这场终局之战?这背后复杂的技术路线与商业博弈,我们将在“AGI小咖”的下一篇深度解读中为您带来终极揭秘。
4.3 NVIDA & UALink & 博通三种愿景对比
AI超级计算机的构建之路已然呈现出三条泾渭分明、相互竞争的技术哲学与商业路线。
对比维度 | NVIDIA“黄金围墙” | UALink“开放联盟” | 博通“统一以太网” |
|---|---|---|---|
核心哲学/模式 | 垂直整合的专有模式 | 专为AI优化的开放标准内存网络 | 推动单一、全能的以太网覆盖所有应用场景 |
优势 | 通过控制每一个环节,实现了无与伦比的性能和优化。 | 生态协作带来的选择多样性和价格竞争力。 | 简洁性,并能最大化利用成熟庞大的以太网生态。 |
劣势/挑战 | 高昂的成本、深度的厂商锁定和单一的创新来源。 | 管理一个多厂商联盟所固有的复杂性和潜在的决策滞后。 | 一个通用协议是否能真正在性能和效率上,与为特定任务量身定制的协议相媲美。 |
4.4 “安卓”VS“苹果”,谁主沉浮?
UALink并非仅仅是一项技术革新,更代表着AI基础设施领域的一场产业战略反击和行业巨头们的一次集体“摊牌”:通过战略性地“武器化”开放的以太网生态系统,来瓦解NVIDIA凭借NVLink构建的、高利润的封闭商业壁垒。
AI数据中心的战役已经打响:一边是NVIDIA凭借“CUDA+NVLink”构建的、软硬一体、性能极致的“集权”帝国;另一边是UALink联盟高举“开放+性价比”大旗组建的“联邦”军队。
您更看好哪条路径能最终主导通往AGI的算力基石?欢迎在评论区留下您的判断!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-10-21,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号