从源码到可执行文件:彻底搞懂 C 语言的编译与链接全过程


前言 很多 C 语言开发者在进阶路上都会遇到一道隐形的墙:代码写得好好的,IDE 里的绿色三角形也能点亮,但一旦遇到
LNK2019、Undefined Reference或者诡异的宏定义问题,就束手无策。 其实,所谓的“点击运行”,背后隐藏着一套精密而复杂的工业流水线。正如 ANSI C 标准所定义的,我们的代码生活在两个完全隔绝的世界:翻译环境和运行环境。 今天,我们就基于《编译和链接》的底层原理,拆解这台“黑盒”,看看你的代码是如何经历预处理、编译、汇编、链接的九九八十一难,最终修成正果的。
这段描述非常适合放在博客的第一部分 ## 1. 翻译环境全景图 中。它为整篇文章定下了基调,解释了代码是如何从文本变成可运行程序的宏观流程。
您可以直接使用下面的文字作为这张图片的图注或者紧跟图片后的正文描述:
在 ANSI C 标准的定义中,程序的生命周期被清晰地划分为两个完全独立的世界(如图所示):
- 翻译环境 (Translation Environment):
- 这是代码的“加工厂”。位于左侧的源代码文件(如
test1.c、test2.c等)在这里被输入。 - 它们经过编译和链接两个核心工序的处理,最终被转换为机器能够识别的二进制指令,生成可执行程序。
- 这是代码的“加工厂”。位于左侧的源代码文件(如
- 执行环境 (Execution Environment):
- 这是代码的“舞台”。翻译环境生成的可执行程序在这里被实际加载运行。
- 程序执行特定的逻辑,最终产生用户看到的输出结果 。
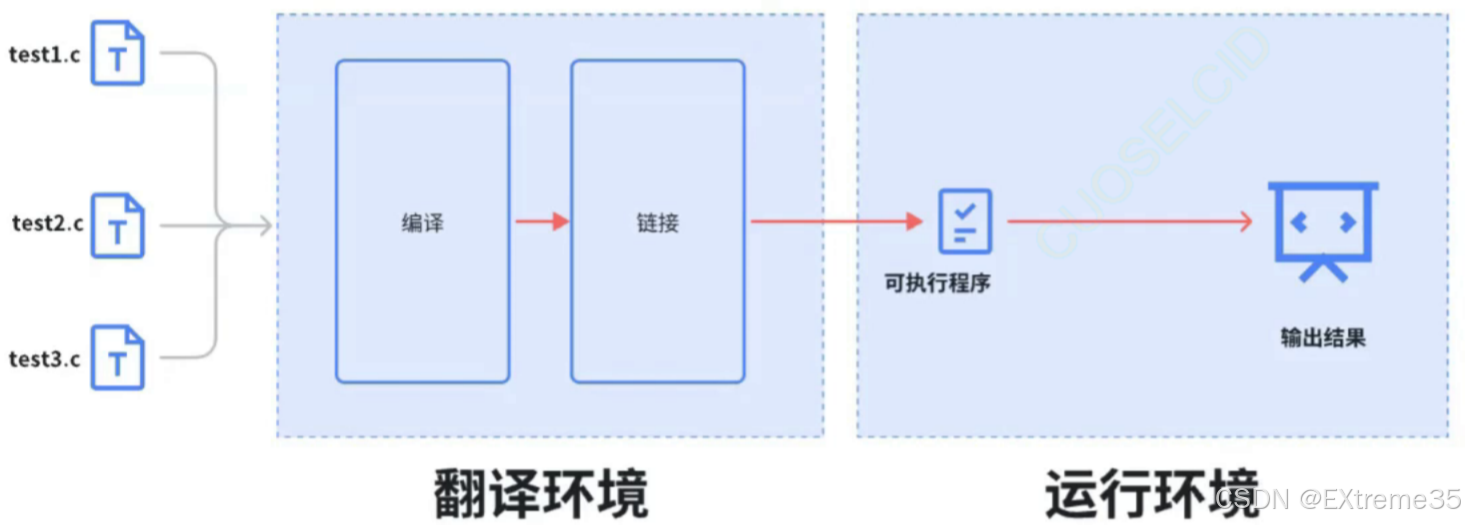
在这里插入图片描述
这张图清晰地展示了数据流的走向:源代码 (.c)
翻译环境 (编译+链接)
可执行程序
运行环境
输出结果。
1. 翻译环境全景图
在 ANSI C 的实现中,翻译环境(Translation Environment)负责将源代码转换为可执行的机器指令。这个过程并非一蹴而就,而是由编译和链接两大核心板块组成。
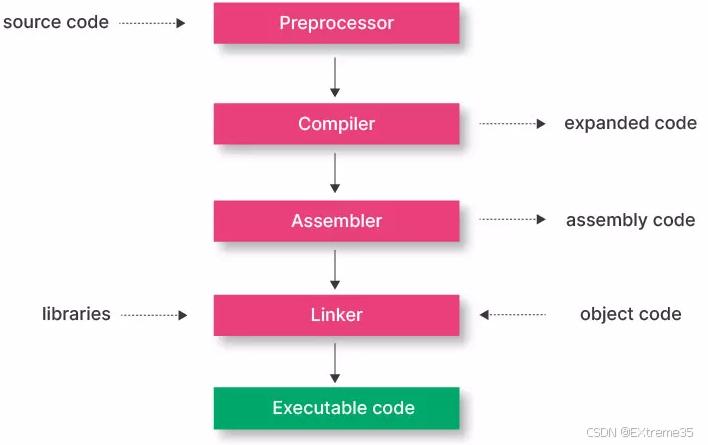
在这里插入图片描述
如果我们把镜头拉近,编译又可以细分为三个原子步骤:预处理、编译、汇编。每个阶段都有其特定的任务和目标。这些阶段确保了源代码被转换成高效且可执行的形式,同时也负责检查错误并支持程序的模块化。该过程的阶段包括:
- 预处理(Preprocessing):处理像
#include和#define这样的指令,展开宏,并包含头文件,从而为编译工作准备源代码。 - 编译(Compilation):将预处理后的代码翻译成汇编语言,同时检查语法错误并对代码进行优化。
- 汇编(Assembly):将汇编代码转换成机器码,生成以
.obj或.o为扩展名的目标文件。 - 链接(Linking):将多个目标文件和库文件组合成一个单一的可执行程序,并解析(解决)对函数和变量的引用。
2. 深度拆解:编译的四个阶段
为了看清每一步发生了什么,我们以 Linux 下的 GCC 编译器为例,通过指令让编译器“慢动作”执行。
第一阶段:预处理 (Preprocessing) —— 纯文本的魔法
**预处理器(Preprocessor)**其实是一个文本替换工具,它甚至不懂 C 语言的语法,只认得 # 开头的指令。
- 指令:
gcc -E test.c -o test.i - 输入:
test.c - 输出:
test.i(预处理后的 C 源码)
这一步到底干了什么?
- 宏展开:将所有的
#define删除,并展开所有的宏定义。这是最容易出 Bug 的地方,比如宏的优先级问题。 - 头文件包含:处理
#include,将头文件的内容原封不动地插入到指令位置。这是一个递归过程,如果头文件 A 包含了 B,B 的内容也会被抓取进来。 - 条件编译:处理
#if、#ifdef、#endif。这在跨平台开发中极为重要(比如一段代码只在 Windows 下保留)。 - 去注释:删除所有的
//和/* ... */,因为机器不需要看注释。
实战技巧:当你遇到“未定义的标识符”或者宏定义展开逻辑错误时,查看
.i文件是极其有效的手段。你会发现几行代码变成了几千行,因为头文件被展开了。
第二阶段:编译 (Compilation) —— 从代码到汇编
这是编译器的核心大脑。它将预处理后的文本文件,翻译成汇编代码。
- 指令:
gcc -S test.i -o test.s - 输入:
test.i - 输出:
test.s(汇编代码)
这个阶段发生了质变,编译器会进行一系列复杂的分析:
- 词法分析 (Lexical Analysis):扫描器将代码字符切割成一系列“记号”(Token)。例如
array[index] = (index+4)会被切割成 16 个记号:array(标识符),[(左方括号),index(标识符) 等。 - 语法分析 (Syntax Analysis):解析器将这些记号组织成语法树(Abstract Syntax Tree, AST)。这是一棵以表达式为节点的树。例如,赋值操作符
=是根节点,左右两边分别是子节点。**语法错误(Syntax Error)**通常就在这一步被抛出。 - 语义分析 (Semantic Analysis):编译器开始理解代码的含义。它会进行类型匹配(比如不能把 float 赋值给 int 指针)、类型转换等静态分析。如果你的逻辑不通,编译器会在这里报错。
- 代码优化:编译器会尝试优化你的代码,比如删除死代码(永远不会执行的代码)、循环展开等。
这里给出一个示例:这段 C 语言代码 array[index] = 4 + 2 * 10 + 3 * (5 + 1); 是一个典型的包含数组访问和复杂算术运算的赋值语句,非常适合用于演示编译器的核心工作流程。
以下是针对这段代码的详细编译过程分析报告,适用于学习者。
1. 词法分析(Lexical Analysis)
词法分析器(Scanner 或 Lexer)负责将输入源代码字符流分解成一系列有意义的、原子性的单元,即词法记号(Tokens)。它会忽略空格和注释。
词法记号列表
记号(Token) | 类型(Token Type) | 语义值/描述 |
|---|---|---|
array | 标识符 (Identifier) | 变量名/数组名 |
[ | 界符 (Delimiter) | 数组下标开始 |
index | 标识符 (Identifier) | 变量名/下标 |
] | 界符 (Delimiter) | 数组下标结束 |
= | 运算符 (Operator) | 赋值操作符 |
4 | 常量 (Constant) | 整数常量 |
+ | 运算符 (Operator) | 加法操作符 |
2 | 常量 (Constant) | 整数常量 |
* | 运算符 (Operator) | 乘法操作符 |
10 | 常量 (Constant) | 整数常量 |
+ | 运算符 (Operator) | 加法操作符 |
3 | 常量 (Constant) | 整数常量 |
* | 运算符 (Operator) | 乘法操作符 |
( | 界符 (Delimiter) | 括号开始 |
5 | 常量 (Constant) | 整数常量 |
+ | 运算符 (Operator) | 加法操作符 |
1 | 常量 (Constant) | 整数常量 |
) | 界符 (Delimiter) | 括号结束 |
; | 界符 (Delimiter) | 语句结束符 |
2. 语法分析(Syntax Analysis)
语法分析器(Parser)接收词法分析器输出的 Token 流,并根据 C 语言的上下文无关文法(Context-Free Grammar)规则,构建出代码的层次结构——抽象语法树(Abstract Syntax Tree, AST)。AST 忠实地反映了运算符的优先级和结合性。
抽象语法树(AST)的层次结构描述
AST 的构建严格遵循 C 语言的操作符优先级和结合性规则(如乘法高于加法,括号强制最高优先级,赋值最低):
- 根节点:
Assignment Statement(赋值语句)。这是整个代码片段的最高层次结构。- 语法含义: 将右侧表达式的值存入左侧的内存地址中。
- 左子树(LHS): Subscript Expression(下标访问表达式)。代表 array[index]。 节点含义: 数组解引用操作。子节点: 标识符 array(数组基址)和标识符 index(下标)。
- 右子树(RHS): Addition Expression(加法表达式)。代表整个算术计算。 节点含义: 整个右侧表达式的核心操作(第二个 +)。左操作数(子节点): Addition Expression,代表 4 + 2 * 10。 左子节点: 常量 4。右子节点: Multiplication Expression,代表 2 * 10。 叶子节点: 常量 2 和 常量 10。 右操作数(子节点): Multiplication Expression,代表 3 * (5 + 1)。 左子节点: 常量 3。右子节点: Addition Expression,代表 (5 + 1)(被括号提升优先级)。 叶子节点: 常量 5 和 常量 1。
完整的抽象语法树图示
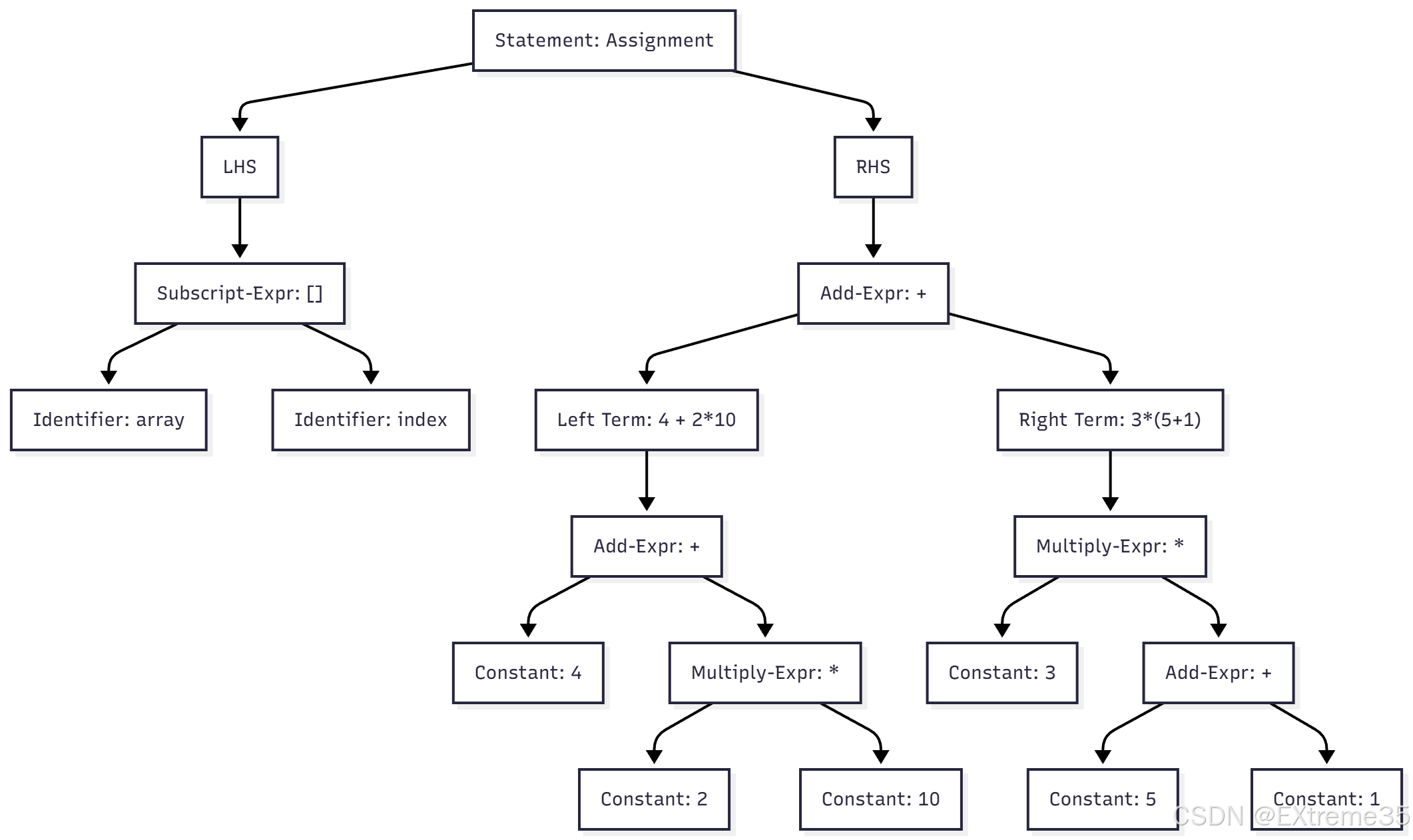
在这里插入图片描述
3. 语义分析(Semantic Analysis)
语义分析阶段利用符号表信息对 AST 进行类型检查、作用域管理和隐含类型转换。这一阶段确保代码在逻辑上和类型上是有效的。
前提假设: 为进行分析,假设 array 被声明为 int 数组(例如 int array[10];),index 被声明为 int 类型。
分析与检查
- 算术表达式类型推导:
- 所有常量(4, 2, 10, 3, 5, 1)默认为
int类型。 - 所有乘法和加法操作(
*和+)的操作数类型都是int,因此它们的运算结果类型也推导为int。 - 整个 RHS(右侧表达式)的最终结果类型为
int。
- 所有常量(4, 2, 10, 3, 5, 1)默认为
- 下标表达式检查:
Subscript-Expr(array[index]):检查array必须是数组或指针类型(满足int[]),index必须是整数类型(满足int)。- 结果类型: 数组元素类型,即
int。
- 赋值兼容性检查:
- 检查: 赋值操作符
=要求其左侧表达式 (array[index]) 的类型 (int) 必须与右侧表达式的最终类型 (int) 兼容或可隐式转换。 - 结论: 在此假设下,
int = int满足类型兼容性,语义正确。
- 检查: 赋值操作符
语义分析后的类型标注AST
以下图在每个节点(特别是表达式节点)旁边标注了该节点的推导类型。
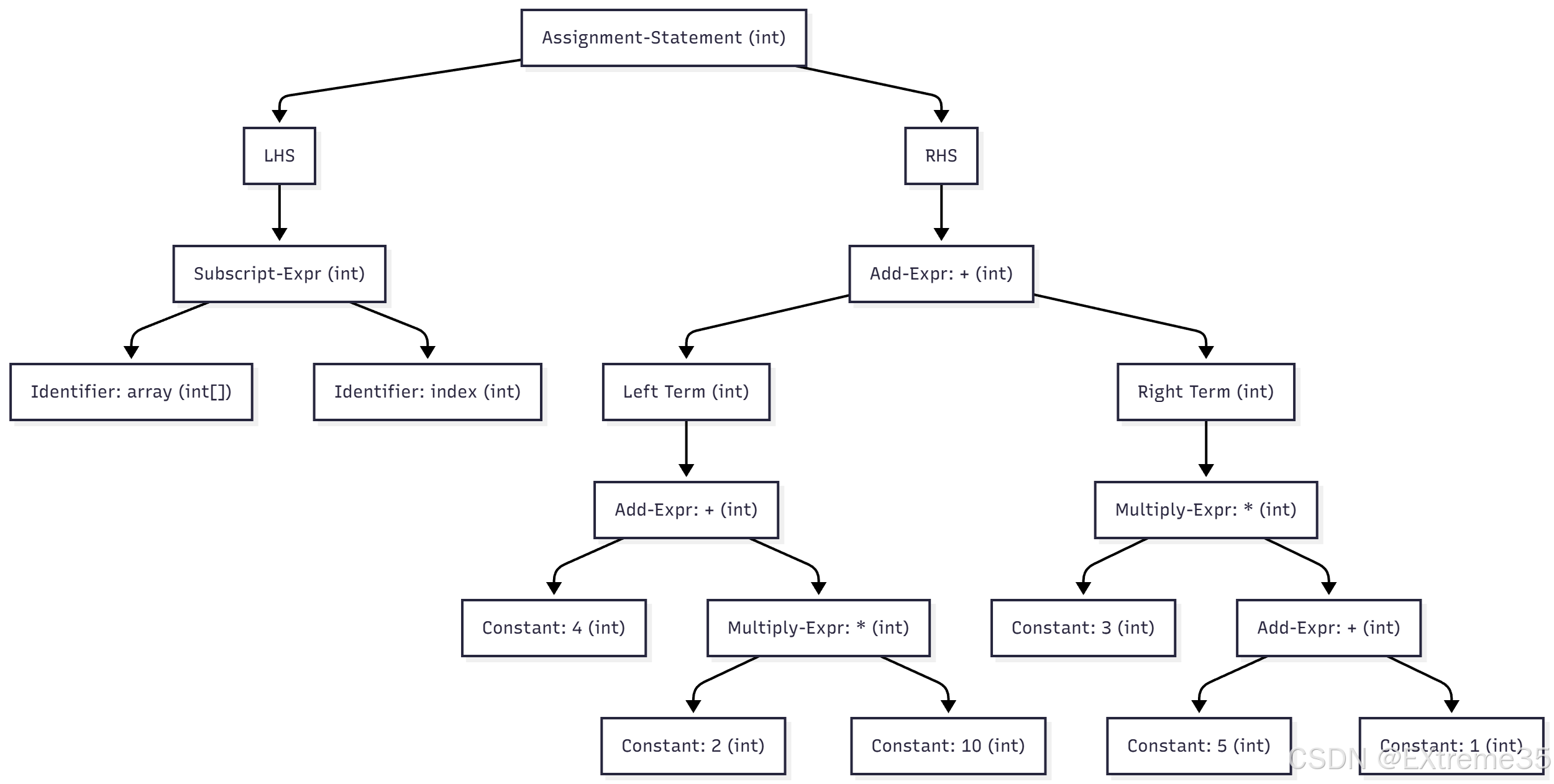
在这里插入图片描述
第三阶段:汇编 (Assembly) —— 翻译官
- 指令:
gcc -c test.s -o test.o - 输入:
test.s - 输出:
test.o(目标文件,Windows 下为.obj)
汇编器将汇编指令(如 mov, push)对照表格,翻译成机器能读懂的二进制指令。此时产生的文件已经是二进制格式,用文本编辑器打开是一堆乱码。
注意:每个源文件(.c)都是单独经过以上三个过程,生成对应的目标文件(.o)。此时,文件之间是互不认识的。
第四阶段:链接 (Linking) —— 拼图游戏的最后一步
链接是很多初学者最难理解的部分。它的任务是把一堆 .o 文件和链接库(Runtime Library)组合在一起,生成最终的可执行程序。
链接器主要解决两个核心问题:符号决议和重定位。
1. 为什么需要链接?
假设你在 test.c 中调用了 add.c 定义的 Add 函数:
// test.c
extern int Add(int x, int y);
int main() {
Add(10, 20);
return 0;
}在编译 test.c 时,编译器并不知道 Add 函数在内存中的具体地址(因为它在另一个文件里)。编译器只能先把这个地址“搁置”,留一个占位符。
2. 链接器的工作机制
- 符号决议(Symbol Resolution):链接器会扫描所有目标文件。它发现
test.o引用了符号Add,而在add.o的符号表中找到了Add的定义。于是,它将两者匹配起来。 - 重定位(Relocation):链接器确定了所有函数和全局变量的最终内存地址后,会回到
test.o中,修正Add指令后的地址,填入真正的函数地址。
3. Windows vs Linux:编译环境差异对照
虽然原理通用,但不同操作系统下的工具链表现不同:
特性 | Linux (GCC) | Windows (MSVC) |
|---|---|---|
预处理指令 | gcc -E | cl /E |
目标文件后缀 | .o (ELF格式) | .obj (COFF/PE格式) |
静态库后缀 | .a (Archive) | .lib (Library) |
动态库后缀 | .so (Shared Object) | .dll (Dynamic Link Library) |
可执行程序 | .out 或无后缀 | .exe |
4. 运行环境:程序起飞之后
当链接器生成了可执行程序,工作就移交给了操作系统。 ANSI C 定义的运行环境包含以下关键步骤:
- 载入 (Load):程序必须被载入内存。在有操作系统的机器上,这由 OS 完成;在嵌入式设备中,可能由 Bootloader 完成。
- 启动:程序开始执行,调用
main函数。 - 内存布局:
- 栈 (Stack):存储局部变量、函数参数、返回地址。函数调用结束自动释放。
- 堆 (Heap):用于
malloc/free的动态内存分配。 - 静态区 (Static Area):存储全局变量、
static修饰的变量。它们在程序整个生命周期内一直存在。
- 终止:正常结束(
return 0)或异常崩溃。
5. 总结与扩展
编译和链接并非黑魔法,而是极其严谨的数据转换过程:
- 预处理:文本操作,宏展开。
- 编译:将 C 语言翻译为汇编,构建语法树。
- 汇编:将汇编翻译为二进制机器码。
- 链接:合并段,解析符号,修正地址(重定位)。
理解这一过程,能让你在遇到 LNK2001 错误时,迅速反应出是 缺少 .lib 还是 函数未定义;在遇到宏定义冲突时,知道去查 .i 文件。
希望这篇扩充后的文章能帮你打通 C 语言编译原理的“任督二脉”。如有疑问,欢迎在评论区交流!
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-11-23,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号