大模型训练|ZeRO三阶段显存"压榨"指南


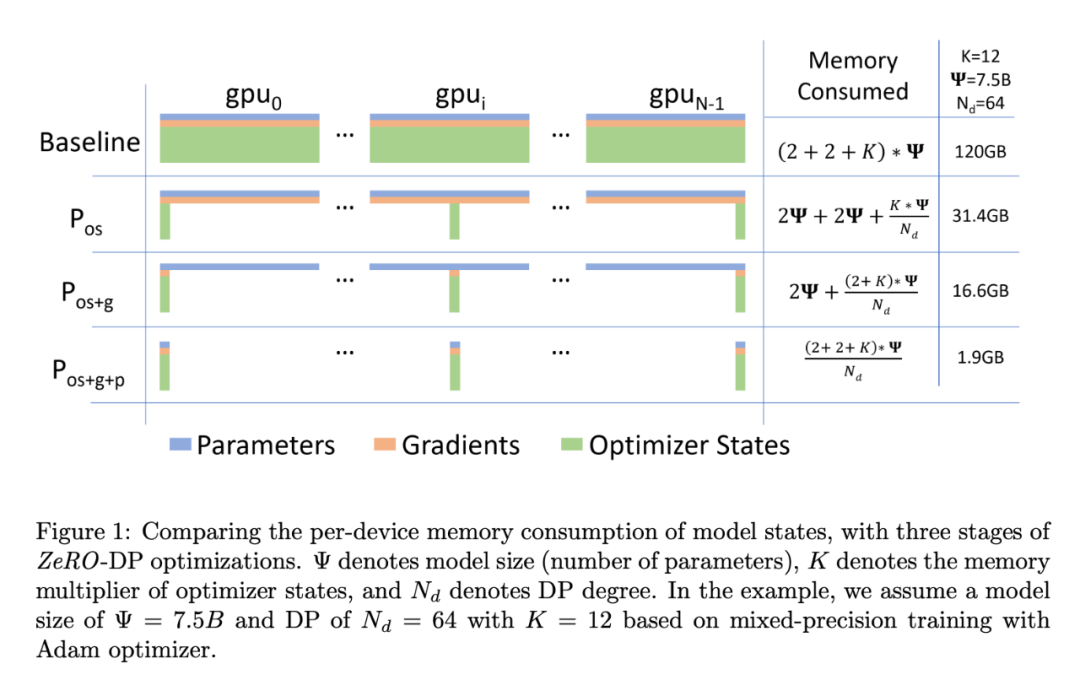
混合精度训练过程中显存占用主要来自参数、梯度、优化器和中间激活值。仅参数、梯度和优化器占用内存为参数量的16倍,假如全参训练一个7.5B的模型,至少要120G的显存,传统的训练策略,有极大的内存优化空间。
1)三种零冗余优化器的分层优化方法。 2)不同的内存优化方案,梯度和参数是如何同步,如何更新? 3)每种优化策略的优势和适用场景介绍。
1,ZeRo三种内存优化方案
内存占用:采用混合精度训练,参数,梯度和优化器占用显存和总参数量M 的关系为:
大模型训练内存占用参考[模型训练占用显存分析]
核心思想:即然参数、梯度和优化器GPU显存开销大,那就分层划片成更小维度后,将它们放在不同 的GPU设备上,用到时候再进行读取。
对显存的进一步优化也就从这三方面下手,即零冗余优化,分为三个层次:
- • zero-1 仅对优化器参数分片
优化后的内存占比为:,当N比较大时, 显存占用相当于原来的 。
- • zero-2 对优化器和梯度分片
优化后的内存占比为:,当N比较大时, 显存占用相当于原来的 。
- • zero-3 对优化器,梯度和参数都分片
优化后的内存占比为:,当N比较大时, 显存占用非常的小。
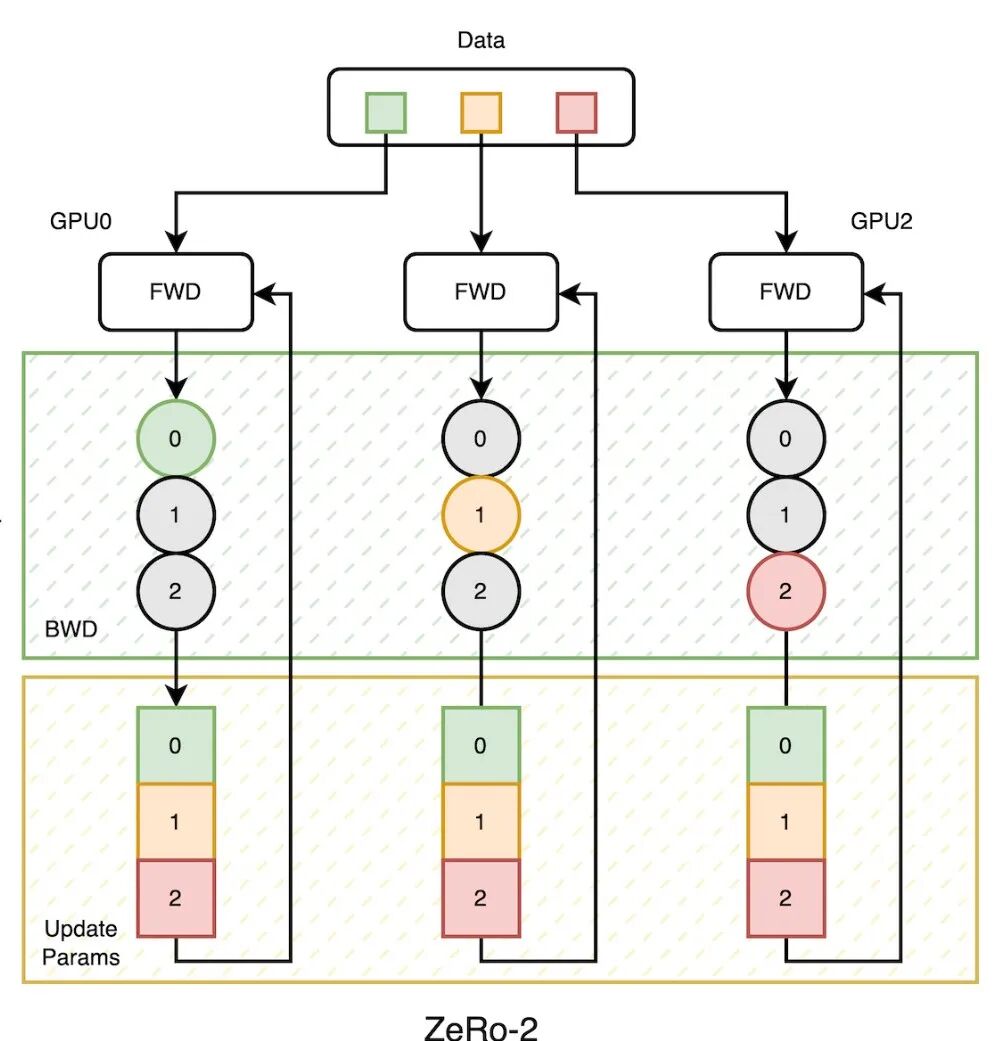
2,ZeRo-2参数更新过程
策略:将模型的梯度和优化器状态进行分片。每个GPU上,保存一份完整的参数副本,以及分片后的梯度和优化器状态。
内存:相对于数据并行,内存最大能减少到原来的1/8倍。
通信量:通信量与数据并行一致,为2M (M为模型参数量)。
更新流程:
- • 梯度分片和batch数据按既定策略分配。 假设:模型有N层,3个GPU设备,完整的模型梯度均分成3份。即,第 层,由GPU0负责;第层,由GPU1负责;第层,由GPU2负责。
- • 前向计算。 每个GPU上存有模型参数副本,独立计算模型损失,无需参数同步通信。
- • 反向传递损失,计算梯度。 获得平均梯度:3个GPU设备在各自的数据上,完成前向计算得到损失后,同时反向传播,等所有的GPU设备计算完层的梯度后,开始使用集合通信算法 Reduce-Scatter 通信。 通信的作用:使得每个GPU设备都获得了层的平均梯度,但只有GPU0将其保存下来,其他GPU设备上的 层的平均梯度被丢弃,对应的内存也被节省下来。同样过程,GPU1获得层的平均梯度,GPU2获得层的平均梯度。整个过程完成后,每个GPU梯度占用内存,只相当于原来的1/3。如果有N个GPU设备,就为1/N。 优化器状态: 对应的优化器状态也仅仅保留每个GPU负责梯度对应的部分。
- • 完整模型参数更新 所有GPU获得负责层的平均梯度后,即可对参数更新,参数更新后,通过 All-gather算法,使得每个GPU上获得一致的参数。
- • 下一轮前向计算开始,如此往复。
以上流程中总的通信量: 前向计算 0 + 反向传播 M + 参数更新同步 M = 2M
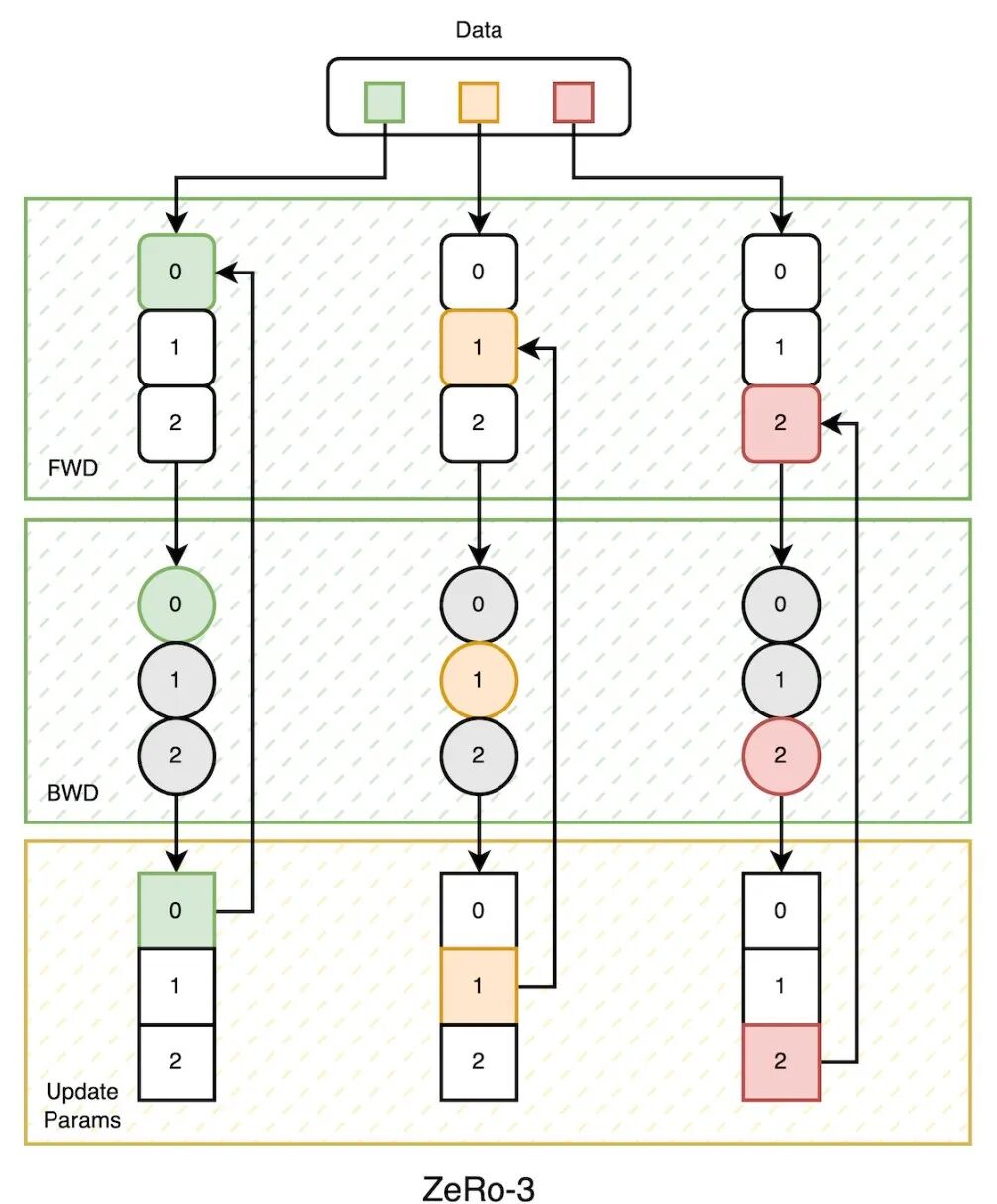
3,ZeRo-3参数更新过程
策略:将模型的参数,梯度和优化器状态进行分片。每个GPU上保存分片后的参数,梯度和优化器状态。
内存:相对于数据并行,内存最大能减少到原来的1/N倍(N为GPU数量)。
通信量:通信量是数据并行的1.5倍,为3M (M为模型参数量)。
更新流程:
- • 参数和梯度划分。 不同GPU保存对应分片后的参数和梯度。数据分片,batch数据分配到不同GPU上。
- • 前向计算。 进行参数通信获得前向计算所需参数。比如,首先进行 层的前向计算时,此部分参数仅保存在GPU2上,需要GPU2进行broadcast通信,将 层的参数广播到GPU0和GPU1,GPU0和GPU1用完后,即可丢弃此部分参数。同样,前向计算进行到 层时,GPU1广播参数,进行 层时,GPU0广播参数。每个GPU在各自的数据上获得前向损失,总的通信量为M。
- • 反向传递损失,计算梯度。 梯度同步: 与ZeRo-2一样,3个GPU设备前向计算获得损失后,同时反向传播,对梯度进行 Reduce-Scatter通信,每个GPU设备获得负责层的平均梯度,通信量为M。 参数再次同步: 此时每个GPU设备上并没有完整的参数,需要再次的进行参数通信,1)参与计算梯度和,2)重新计算前向的激活值,参数的通信量为 M。 反向时总的通信量为2M。
- • 参数更新 每个设备获得的根据平均梯度,更新对应负责参数和优化器状态。
- • 下一轮前向计算开始,如此往复。
以上流程中总的通信量: 前向计算 M + 反向传播 2M + 参数更新同步 0 = 3M
ZeRo策略总结
ZeRo通过分片策略实现内存与通信的权衡,其核心思想是 “以通信换内存”
维度 | ZeRo-2 | ZeRo-3 |
|---|---|---|
分片策略 | 仅分片梯度(Gradients)和优化器状态(Optimizer States) | 分片参数(Parameters)、梯度和优化器状态 |
内存优化倍数 | 最大减少至数据并行的 1/8 | 最大减少至数据并行的 1/N(N为GPU数量) |
总通信量 | 2M (反向传播M + 参数同步M) | 3M (前向M + 反向2M) |
前向计算 | 无需参数通信(每GPU保留完整参数副本) | 需动态广播分片参数(如逐层广播,通信量M) |
反向传播 | 使用 Reduce-Scatter 分片梯度(通信量M) | 分两次通信:1)梯度Reduce-Scatter(M)2)参数计算梯度和激活值(M) |
参数更新 | 各GPU更新完整参数后,通过 All-Gather 同步(通信量M) | 仅更新本地分片参数(无需同步) |
适用场景 | 中等规模模型(内存压力主要来自梯度和优化器状态) | 超大规模模型(内存压力来自参数本身,如GPT-3等) |
使用pytorch 官方集成的零冗余优化器,默认是对梯度和优化器状态进行分片存储,如果也需要对参数进行分片,需要结合FSDP进行。
if use_zero:
optimizer = ZeroRedundancyOptimizer(
ddp_model.parameters(), optimizer_class=torch.optim.Adam, lr=0.001
)
else:
optimizer = torch.optim.Adam(ddp_model.parameters(), lr=0.001)从结果上看,使用优化器后,模型训练占用的显存从2003M 降到了 1248M。
max memory allocated after creating local model: 335.0MB
max memory allocated after creating DDP: 656.0MB
Max memory allocated before optimizer step(): 996.0MB
Max memory allocated after optimizer step(): 1248.0MB
params sum is: 80040000
------- not using Zero ---------
max memory allocated after creating local model: 335.0MB
max memory allocated after creating DDP: 656.0MB
Max memory allocated before optimizer step(): 996.0MB
Max memory allocated after optimizer step(): 2003.0MB
params sum is: 80040000参考: [1] arXiv:1910.02054 [2] arXiv:1910.02054 [3] arXiv:2104.07857
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-09-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号