视频超分辨率如何提升跨视角行人识别?让监控画面“看清”每一个人
原创
视频超分辨率如何提升跨视角行人识别?让监控画面“看清”每一个人
原创
CoovallyAIHub
发布于 2026-01-19 10:14:41
发布于 2026-01-19 10:14:41
在城市的天空与地面之间,无数摄像头正默默记录着行人的轨迹。但你是否想过,当一个模糊的身影从无人机画面中掠过,我们如何在地面监控中准确找到同一个人?这正是跨视角行人重识别技术的核心挑战。最近,一项名为S3-CLIP的创新研究给出了令人振奋的答案。
分辨率不匹配
行人重识别技术旨在跨摄像头追踪同一行人,但在实际应用中,一个常见问题是分辨率不匹配:地面摄像头可能拍到清晰的人脸,而无人机拍摄的画面却因距离过远而模糊不清。这种差异会导致识别准确率大幅下降,有时甚至降低近20%。
传统解决方案通常采用双线性插值或双三次插值等简单方法提升图像分辨率,但这些方法往往只是让图像“看起来”更大,却无法恢复丢失的细节。更先进的生成对抗网络方法虽然能生成更逼真的图像,却可能“幻想”出不存在的纹理,误导识别系统。
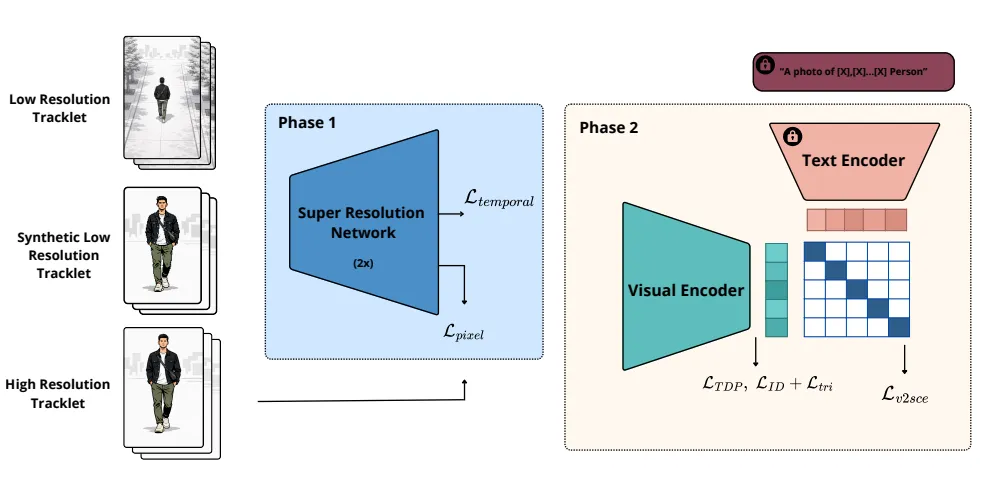
S3-CLIP:为行人识别量身打造的视频超分辨率框架
screenshot_2026-01-16_15-40-35.png
S3-CLIP是首个专门为视频跨视角行人重识别设计的超分辨率框架,其创新之处在于:
- 任务驱动而非视觉驱动
传统超分辨率方法追求图像“看起来”清晰,使用PSNR、SSIM等指标衡量质量。但S3-CLIP采用任务驱动损失函数,确保恢复的细节对身份识别真正有用,而不是仅仅追求视觉逼真度。
- 两阶段训练策略
研究团队发现,同时训练超分辨率和识别网络会导致梯度冲突。S3-CLIP采用两阶段优化:第一阶段仅训练超分辨率网络,第二阶段冻结超分辨率网络,专门训练识别网络。这种策略显著提升了训练稳定性。
- 时序一致性保证
对于视频数据,S3-CLIP引入了时序一致性损失,确保连续帧之间的超分辨率结果平滑自然,避免出现闪烁或跳变,这对于视频行人识别至关重要。
- 无需配对数据
现实世界中很难找到同一人的高清与低清视频对。S3-CLIP通过半监督采样策略解决了这一问题,同时利用合成的和自然的低分辨率视频进行训练。
性能突破:地面对无人机识别提升显著
在DetReIDX数据集上的测试结果令人印象深刻:
- 地面对无人机场景:Rank-1准确率提升11.24%,Rank-10提升17.98%
- 无人机对地面场景:Rank-1准确率提升0.69%
- 无人机对无人机场景:性能保持竞争水平
这些结果表明,超分辨率预处理对地面对无人机这种分辨率差异最大的场景最为有效。当地面拍摄的低分辨率查询图像需要匹配无人机拍摄的高清库时,S3-CLIP能显著恢复身份相关细节。
技术细节:如何实现这一突破?
S3-CLIP的核心架构基于两个关键组件:
- SwinIR超分辨率网络:这是一种基于Transformer的先进超分辨率模型,能够捕捉图像中的长距离依赖关系,有效恢复细节。
- VSLA-CLIP识别框架:这是一个专门为跨平台视频行人识别设计的CLIP变体,通过视频集级适配器和平台桥接提示词,减少地面与无人机视角之间的域差异。
训练过程中,研究团队采用了两阶段方法。第一阶段专注于超分辨率任务,使用像素损失、任务驱动感知损失和时序一致性损失的组合。第二阶段则专注于识别任务,使用对比损失、三元组损失和身份分类损失的组合。
极端情况下的限制
尽管S3-CLIP表现出色,但在某些极端情况下仍面临挑战:
- 极低分辨率输入:当图像仅有6×6像素时,几乎无法恢复有效身份信息
- 运动模糊与压缩伪影:这些退化类型难以通过超分辨率完全恢复
- 长宽比失真:为适应网络输入而调整图像比例可能导致人体比例变形

screenshot_2026-01-16_15-41-02.png
例如,在极端低分辨率情况下,超分辨率网络可能只是放大模糊伪影,而非恢复真实细节。
- 多尺度适应与真实退化建模
研究团队指出,S3-CLIP的当前版本使用固定2倍上采样,这限制了其对多样化分辨率分布的适应性。未来工作可能包括:
- 多尺度自适应超分辨率:根据输入分辨率动态调整上采样因子
- 真实退化建模:在训练中纳入运动模糊、压缩伪影等真实退化模式
- 更高效的架构:降低计算开销,使系统更适合实时应用
结语:迈向更智能的视觉监控系统
S3-CLIP不仅是一项技术创新,更是解决现实世界监控挑战的重要一步。随着摄像头网络的扩展和无人机应用的普及,如何处理跨视角、跨分辨率的视觉数据将成为越来越重要的课题。
这项研究提醒我们,在追求更高识别准确率的同时,我们也需要关注输入数据的质量。有时候,提升数据质量比改进模型架构更能带来实质性的性能提升。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号