龙虾劝退师:你的每一句“在吗”,都在疯狂燃烧 Token
原创
龙虾劝退师:你的每一句“在吗”,都在疯狂燃烧 Token
原创
点火三周
发布于 2026-03-20 17:57:37
发布于 2026-03-20 17:57:37
大模型时代的 Token 经济学与避坑指南
导读 很多人把龙虾当成微信里的免费好友,每天无聊了就发一句“在吗”、“今天天气不错”。在终端 UI 极简的交互背后,你可能对底层的算力消耗一无所知。龙虾并不像豆包,一直都是免费的。当你用真金白银买入算力,一场无感的 token 燃烧就开始了
本文将以 OpenClaw Agent 框架为例,直接扒开底层的
.jsonl会话日志,用真实的数据和架构原理解释:为什么你不经意的一个回车,可能就会烧掉你几块钱人民币?在大模型 Context(上下文)爆炸的时代,我们又该如何通过系统级的设计与最佳实践,优雅地控制成本?
第一章 认知颠覆:龙虾不是你的微信或QQ好友
1.1 伪装成对话的“无状态”接口
在开始探讨成本之前,我们必须先了解一个简单的技术背景:大模型(LLM)是没有记忆的。
当你在企业微信、网页端或者终端里,看到龙虾像人类一样,能够承接你上文的语境流利对答时,这并不是因为它的神经元里记住了你的话。现代的所有 LLM API(如 GPT‑4, Claude 3, Gemini 1.5)本质上都是无状态(Stateless)的 HTTP RESTful 接口。
所谓的“记忆”,不过是 Agent 框架(如 OpenClaw)在底层替你负重前行。每次你发送一条新消息,框架都会将你们从第一回合开始的所有历史对话记录,打包成一个巨大的 Message Array,一股脑地作为 Input 发送给大模型。
1.2 滚雪球效应:线性交互与指数级成本
理解了“历史追加(Append)”机制,我们再来看看大模型的计费模型。当前主流云厂商的计费维度极其简单粗暴:按 Token 数量计费(分为 Input Tokens 和 Output Tokens, 当然,现在有不少厂商开始推出了 coding plan,按照调用次数收费,不用怀疑,这是成本的下降,但不代表你就能实现养虾自由)。
这会导致一个极其恐怖的“滚雪球效应”:
假设你和 Agent 进行一次深度 Debug,平均每次你发 100 个 Token,Agent 回复 200 个 Token。
- 第 1 回合:API 接收 100 Token,计费 100 Input。
- 第 5 回合:API 接收前 4 轮的 1200 Token + 你新的 100 Token,计费 1300 Input。
- 第 50 回合:API 接收前 49 轮的 14700 Token + 你新的 100 Token,计费 14800 Input。
如果你在这个时候,发了一句毫无意义的:“好的,谢谢”。
大模型依然要完整阅读前面 14800 个 Token,才能吐出“不客气”三个字。这 14800 个 Token 的计费,就是你为这句“谢谢”付出的隐形成本。交流越深入,你的每一句话就越昂贵。
第二章 扒开底层:一次 2 块钱的 Grep 命令
为了让你对成本有最直观的体感,让我们放弃前端 UI,直接 SSH 登录到服务器,扒开 OpenClaw 的底层日志。
在 OpenClaw 中,所有的会话持久化都在 ~/.openclaw/agents/main/sessions/ 目录下。每一个 Session 是一个独立的 .jsonl 文件。
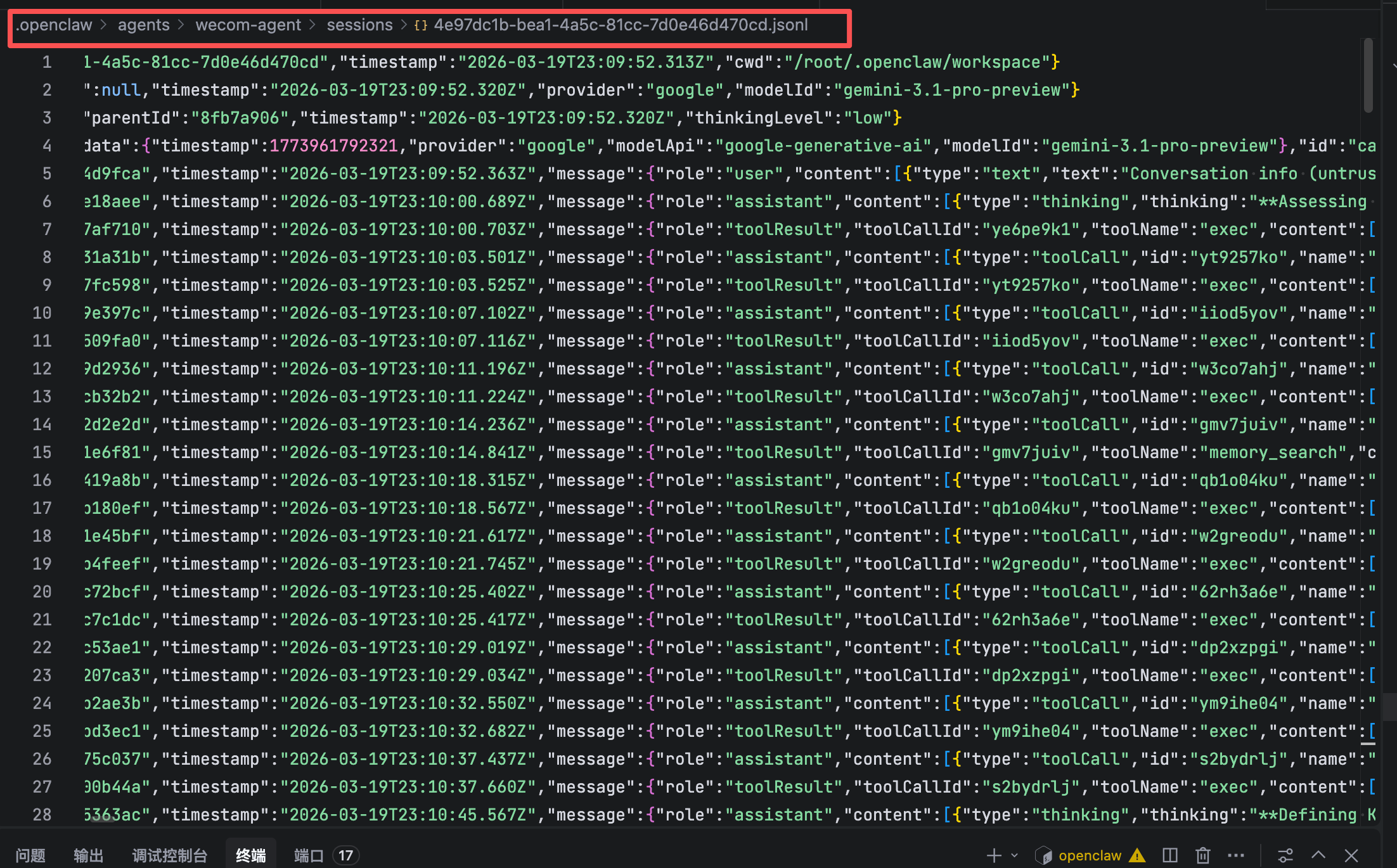
就在今天上午,我替你执行了一条再普通不过的终端命令查询日志:grep '"role":"assistant"' 4e97dc...jsonl | tail -n 1。
以下是 OpenClaw 记录的这次交互的真实底层元数据(经过提取和格式化):
{
"message": {
"role": "assistant",
"provider": "google",
"model": "gemini-3.1-pro-preview",
"usage": {
"input": 129976,
"output": 111,
"cacheRead": 126160,
"totalTokens": 130087,
"cost": {
"input": 0.2599,
"output": 0.0013,
"cacheRead": 0.0252,
"total": 0.2865
}
}
}
}这份数据揭示了三个惊人的事实:
- 庞大的上下文黑洞:仅仅是为了回答一条简单的 grep 命令,由于我们之前的对话历史极长,本次请求的 Input Tokens 高达 129,976 个!这是什么概念?一部中篇小说的字数。
- 高昂的单次交互成本:这次请求的总成本(Total Cost)是 0.2865 美元(约合人民币 2 块钱)。如果你在一个长 Session 里高频互动 100 次,仅仅是来回确认日志,几十美金就灰飞烟灭了。
- Prompt Caching 的续命:注意看
cacheRead: 126160这个字段。现代前沿模型(如 Gemini 和 Claude)为了缓解长上下文成本,引入了前缀缓存技术(Prompt Caching)。在这 13 万个 Input Token 中,有 12.6 万命中了缓存,缓存读取的价格通常只有原价的 1/4 到 1/10。如果不是大厂的 Caching 技术在这托底,刚才那一次请求的成本至少要翻 4 倍(飙升到 1 美元以上)。
第三章 悬崖勒马:Context 爆炸与 Compact (压缩) 机制
当 Token 像脱缰的野马一样狂奔时,如果不加干预,不仅钱包受不了,还会触达大模型的物理极限(Context Window 限制,如 128K 或 200K)。
优秀的 Agent 框架不会坐视不管。OpenClaw 在底层设计了一套极其关键的“自救”机制:Context Compaction(上下文压缩)。
3.1 什么是触发式 Compact?
当系统监测到当前 Session 的 Token 总量逼近预设的高水位线(例如 130k Tokens)时,会强制阻断正常的对话流,在后台发起一次静默的 Compact 任务。
你可以把它理解为一次“记忆的垃圾回收(GC)”。
3.2 机制解剖:模型自己总结自己
Compact 的实现方式极其巧妙:OpenClaw 会调用大模型自身,把这 130k 的历史记录发给它,并附带一个强硬的 System Prompt,要求模型提取过去对话中的核心目标(Goal)、约束(Constraints)、已完成进度(Progress)、关键决策(Decisions)和待办事项(Open TODOs)。
拿我的触发的一次压缩为例:
The conversation history before this point was compacted into the following summary:
System: [2026-03-20 10:56:27 GMT+8] Compacted (133k → 26k) • Context 26k/1.0m (2%)看,一次成功的 Compact,硬生生把 133,000 的巨量 Token,浓缩成了 26,000 的摘要。
3.3 压缩的代价:这世上没有免费的午餐
别高兴得太早,Compact 虽然延缓了爆仓,但它带来了两个你必须承担的痛点:
- 瞬时极高的算力账单:执行 Compact 本身,需要模型完整阅读 133k 的长文本,并生成总结。这往往是一次极其昂贵的单次 API 调用。
- 有损压缩(Lossy Compression):摘要永远是摘要。那些被折叠的几十轮对话中,某一个具体的文件路径、某一段随手写的代码片段、某一次微小的环境配置,很可能在压缩过程中被 AI “认为不重要”而丢弃。当你后续再次提及这些细节时,AI 会表现出“失忆”或产生幻觉(Hallucination)。
第四章 架构师的解法:Session 管理最佳实践
既然长上下文是成本黑洞和幻觉的温床,我们作为养虾人,就必须建立起良好的 Session 架构意识。
不要把 AI 当作一个永远不关机的对讲机(当然,这也是用 IM 去管理 Agent 最大的陷阱),而应该把它当作一个可以随时销毁重建的“容器(Container)。以下是我总结的 4 条最佳实践。
4.1 核心原则:单一职责(SRP)
把软件工程里的单一职责原则用在 AI 对话上。
一个 Session 只做一件事。
不要在同一个会话里,既让它帮你写 Python 脚本,又让它帮你修改 Nginx 配置,接着还顺便问它明天的天气。不同的任务上下文会互相干扰,白白增加 Token 消耗。任务结束,立刻关停。
4.2 斩断过去:善用 /reset 和 /new
当你准备开启一个全新的排障工作时,永远不要顺着上一个话题继续聊。
在 OpenClaw 中(包括通过企业微信对话),请果断输入:
/reset 或 /new。
底层发生了什么?
当你敲下 /reset 时,OpenClaw 并不是简单地清空前端页面。它会在 Linux 文件系统中,将当前的 uuid.jsonl 文件重命名备份为 uuid.jsonl.reset.2026-03-20T10-00-00Z,并立刻为你生成一个全新的 Session ID 和空白的 .jsonl。
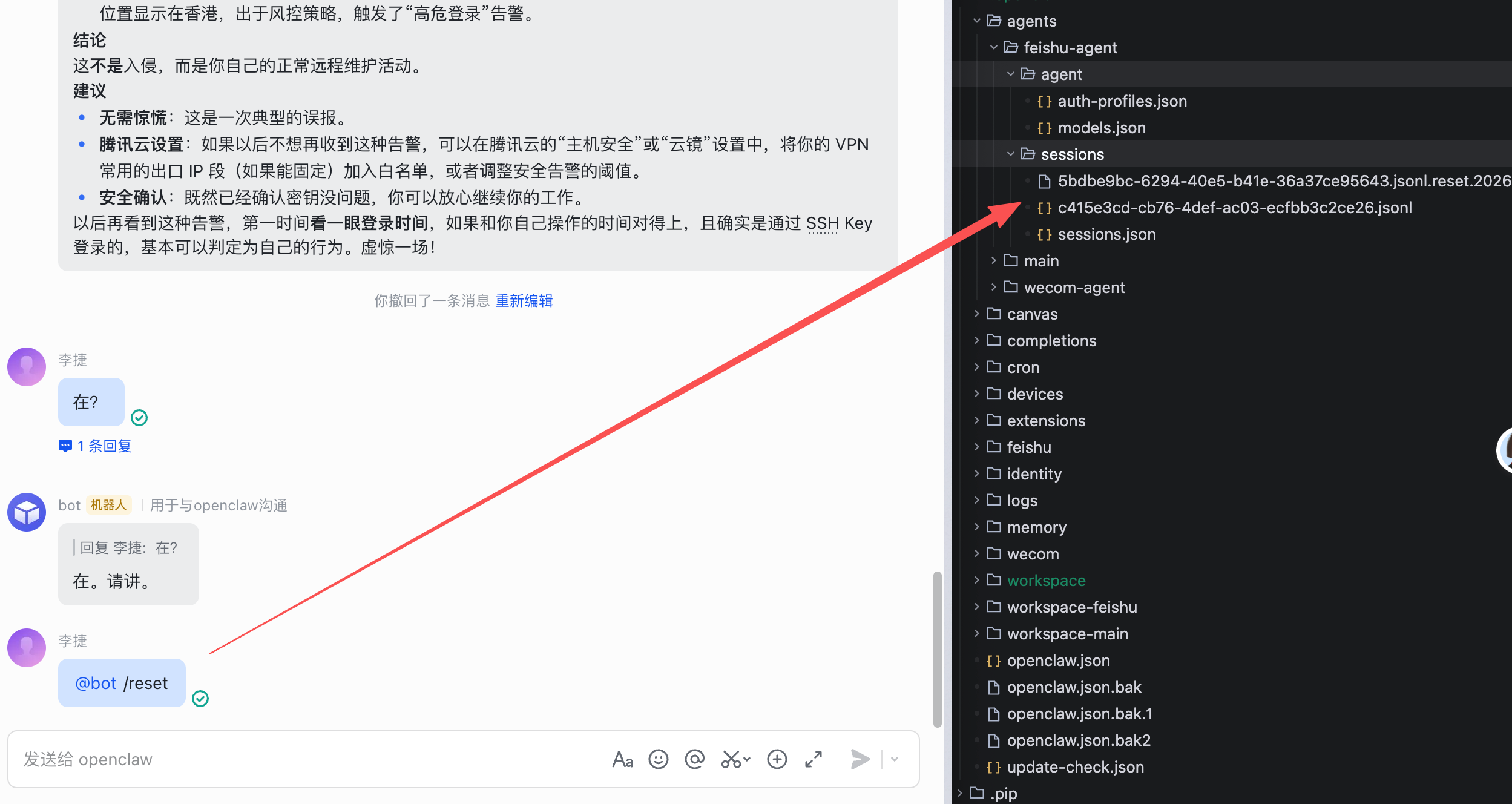
这一刻,历史包袱被彻底清空,你接下来的每一次对话,计费都将从 0 重新开始。这不仅是省钱,更是为了让大模型的注意力机制保持最高纯度,提高代码生成的准确率。
4.3 手动干预:可控的 /compact
不要总是等待框架的被动触发。如果你在一个中等长度的任务中(比如迭代开发一个网站应用或写一篇长文、小说),你确信前期的头脑风暴已经结束,现在只关注最终的润色,你可以主动输入 /compact,强制让 AI 进行历史归档,丢弃那些无用的草稿过程。
4.4 戒掉“闲聊”的恶习
正如前文所算,在一个包含 10 万 Token 的上下文里,你发一句“嗯”或者“谢谢”,成本可能高达 1‑2 块钱。
对机器不需要讲礼貌。指令要干脆、直接、信息密度高(这也是我在 SOUL.md 中,必须让我的龙虾做到“人狠话不多”原则的原因)。把你的诉求一次性写完整,避免挤牙膏式的多轮追问。
我看到很多人喜欢以聊天的方式说自己的需求,实际上这不仅增加了成本,还增加了模型出现幻觉的可能性
第五章 延伸与进阶:如何找回丢失的记忆?
如果你严格执行了频繁的 /reset,你可能会有一个担忧:那 AI 岂不是变成了彻底的健忘症?我昨天告诉它的数据库密码、我的代码偏好,它全忘了怎么办?
这就引出了 Agent 架构中极为重要的组件:Long‑Term Memory(长期记忆)与 RAG(检索增强生成)。
在优秀的 Agent 设计中(如 OpenClaw 的工作区机制),个人的偏好、敏感的环境变量、基础设施的架构图,不应该依赖于 Session 的历史上下文去死记硬背。
正确的做法是:将它们写入本地的独立文档(如 MEMORY.md、TOOLS.md)。
每次开启全新的 Session 时,Agent 在接到你的第一个指令之前,会通过 System Prompt 自动加载(或通过向量检索)这些静态文档。
用静态的文件读取,替代动态的长上下文堆叠,这才是真正的架构级省钱利器。
第六章 蒙眼狂奔的隐患:我们需要真正的可观测性 (Observability)
讲到这里,所有的原理和操作你都懂了。但你在实际使用时,依然会面临一个巨大的阻碍:不可见。
无论是企业微信的聊天窗口,还是终端的 CLI 界面,它们只负责交互,没有任何一个 UI 会直观地给你画出:“你今天的 Token 消耗曲线是多少”、“最近 10 次 Compact 发生的时间点”、“各个 Skill(工具)的调用失败率是多少”。
仅仅依靠时不时地去服务器上 tail -f 抓取 .jsonl 日志,是反人类的,也是极度危险的。没有监控系统,你的 AI 资产就是在蒙眼狂奔。
既然数据都在底层的日志里躺着,我们为什么不把它提取出来,丢进专业的数据分析引擎中呢?
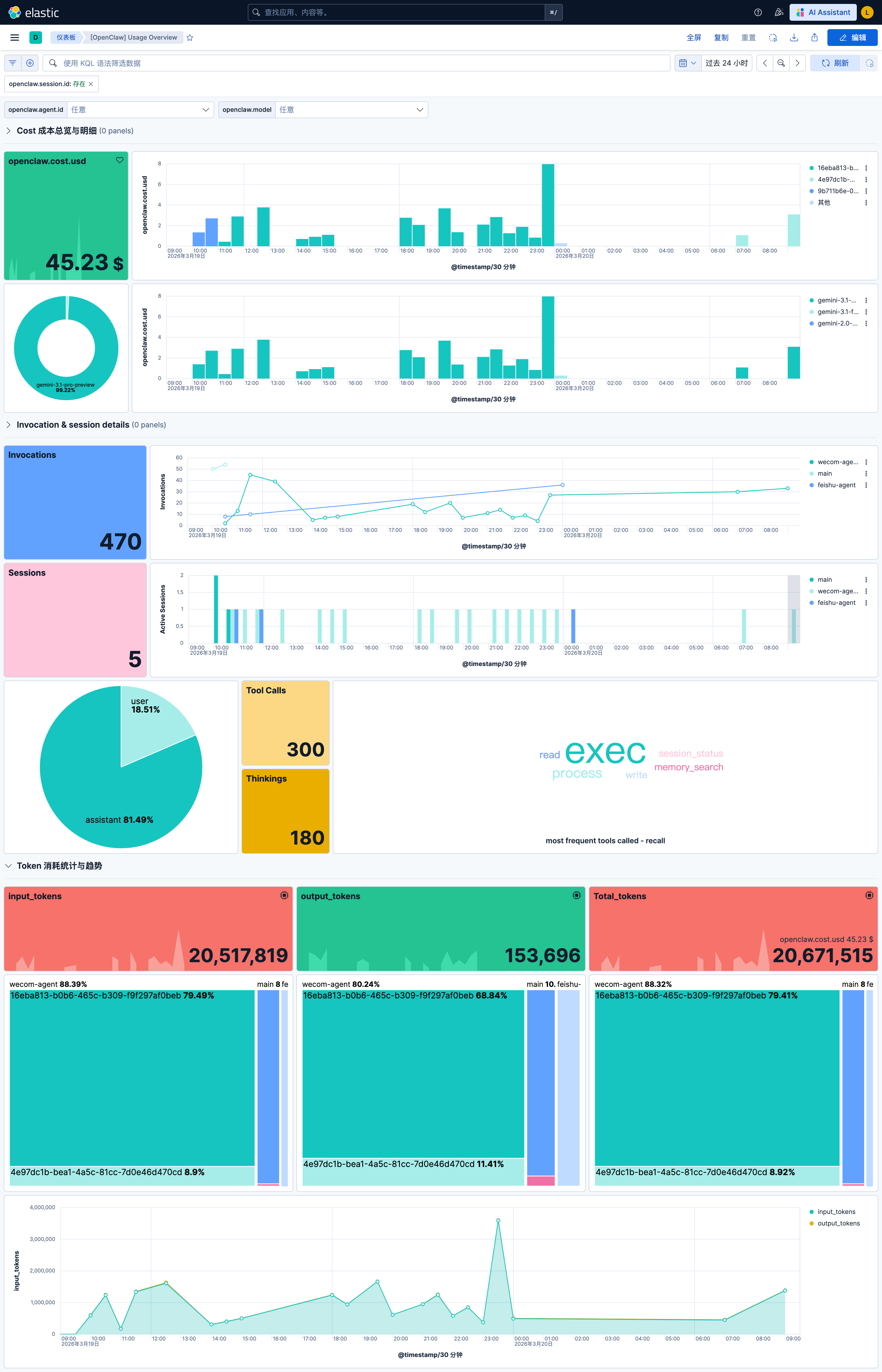
为了解决这个终极痛点,在下一篇文章中,我将转换视角,带你进入 Elastic 工程实践领域。
我们将手把手演示:如何从零构建一个标准的 Elastic Integration 包,将 OpenClaw 的底层日志转化为 Kibana 里高大上的 LLM Observability(大模型可观测性)大屏仪表板,实现从采集、清洗到可视化的“一条龙服务”。
敬请期待下篇:《从零构建 Elastic Integration:全栈监控你的龙虾》。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号