10.8K Star 虾马之后又火一个!OpenHuman 自动了解你的一切,存成 Karpathy 式知识库!

10.8K Star 虾马之后又火一个!OpenHuman 自动了解你的一切,存成 Karpathy 式知识库!

开源星探
发布于 2026-05-19 12:09:12
发布于 2026-05-19 12:09:12
2026年的 AI 圈,Agent 正在从实验室走向办公桌,过去一年 Agent 类产品增长率远超传统大模型工具。
虽然市面上的 Agent 越来越多,但大多数都有一个共同的毛病:它们不了解你。
你打开一个新的 Agent 工具,它就像一个刚入职的实习生,既不知道你在做什么项目,也不清楚你跟同事的上次沟通进展。你得花上几天甚至几周时间反复解释项目背景和工作习惯,它才能勉强派上用场。
最近在 GitHub Trending 榜首看到了这个叫 OpenHuman 的开源项目,试图从根本上绕开这个痛点。
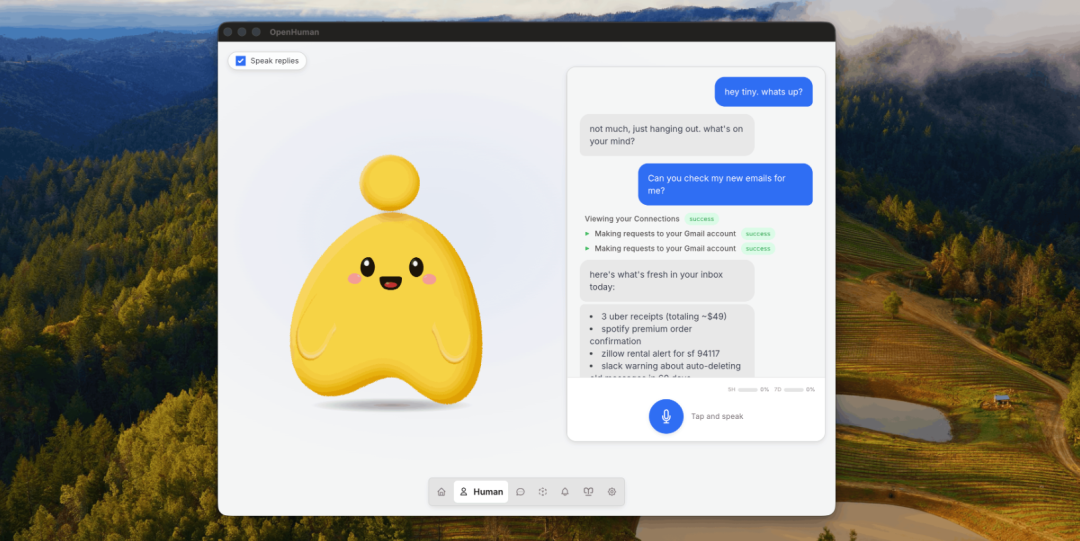
它的目标很直接:让AI在几分钟之内了解你的全部工作与生活上下文,然后变成一个真正懂你的「数字分身」。
这个项目由 Tiny Humans AI 团队开发,目前狂揽 10.8k+ Star,一天就涨千星,登顶过 GitHub Trending 榜单当日第一,而且近期连续稳定在 Trending 日榜 TOP10。
核心理念
OpenHuman的核心理念:Context in minutes, not weeks。这个想法受到前特斯拉 AI 总监 Andrej Karpathy 的启发。
Karpathy 去年公开了自己的「LLM Wiki」工作流——把所有笔记、文档、项目信息整理成结构化 Markdown 文件,存放在 Obsidian 中,让AI持续索引和理解。
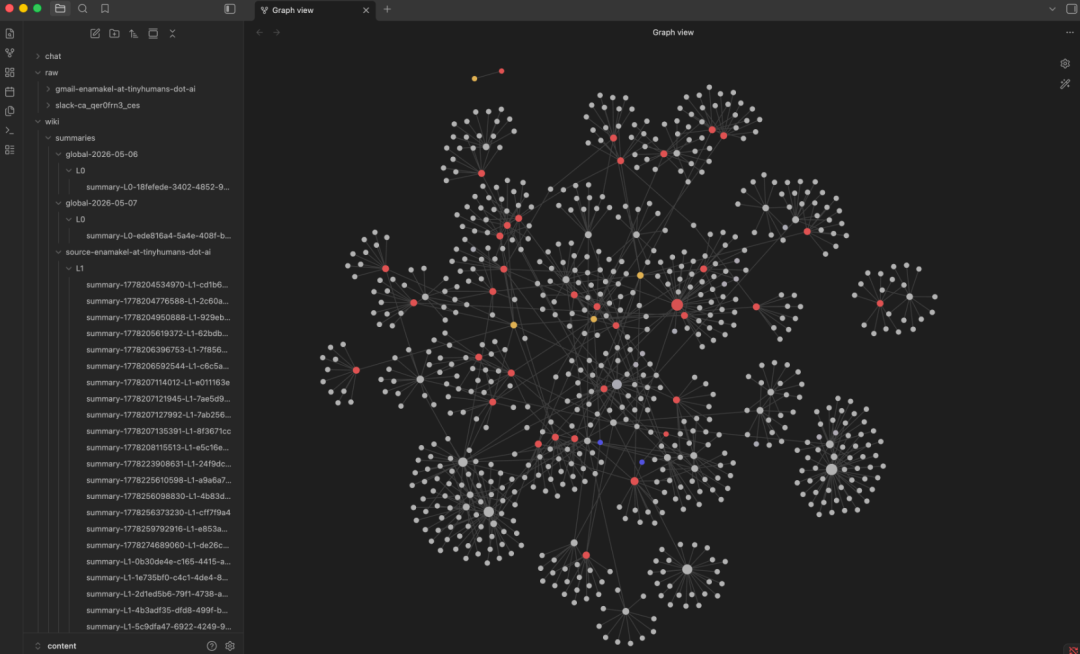
他管这个叫「LLM as OS」——大模型是数字生活的操作系统,知识库就是硬盘。这套工作流后来在技术圈引发广泛讨论,但问题是,这套操作全手工。你得自己整理Markdown、自己分类、自己更新,一天不维护,知识库就馊了……
OpenHuman 干的事,就是把 Karpathy 这套手工活,变成了全自动流水线。
总结成一个三步链路就是:连接→抓取→记忆树。
第一步:一键连接。 目前 OpenHuman 支持 118+ 第三方服务,每个连接都是一键 OAuth 授权,不需要你跑去每个平台手动生成 API Key。
第二步:自动抓取。 连接完之后,核心引擎每 20 分钟自动轮询所有已连接的账户。新邮件、日程变更、代码提交、文档更新……全拉到本地。你不用写任何prompt或轮询脚本,Agent自己知道什么时候该刷新。
第三步:压缩进记忆树。 抓来的数据经过清洗和压缩,切成不超过 3000 个 Token 的 Markdown 片段,按主题、时间线、关联对象做评分和层级摘要,最终折叠成一棵记忆树。
这棵树的本体是一个本地 SQLite 数据库。但同一份数据,还会同步生成.md文件,落盘成一个兼容 Obsidian 的本地知识库,你可以直接用 Obsidian 打开、浏览、编辑Agent的"记忆"。
一次同步跑完,直接对你工作生活的了如指掌。没有训练期,没有磨合期,第一天上班就能干活。
六大核心能力
1、记忆树 + Obsidian Wiki
这是 OpenHuman 的灵魂。它不是简单的把数据存下来,而是构建了一个层次化的知识图谱:
- • 数据被切分成 ≤3k token 的 Markdown chunk
- • 每个 chunk 有相关性评分
- • 分层摘要树结构,存在本地 SQLite
- • 同步生成 Obsidian vault,你随时可以查看和编辑 Agent 的"记忆"
这意味着你拥有完全的数据主权。Agent记住的一切,你都能看见、能改、能删。官方文档的总结很到位:「你无法信任一段你无法阅读的记忆」。
2、118+ 第三方集成 + Auto-fetch
一个桌面 AI 助手好不好用,很大程度上取决于它能接多少服务。
OpenHuman内置了118+集成,覆盖了大多数人日常工作的核心工具栈——Gmail、Notion、GitHub、Slack、Stripe、Calendar、Drive、Linear、Jira……
关键是连接方式——一键OAuth,不需要你去每个服务里手动生成API key。Auto-fetch机制确保数据持续更新,每20分钟一轮同步,Agent的上下文永远是新鲜的。
3、TokenJuice 智能压缩
这是一个容易被忽视但极其重要的设计。每次工具调用、网页抓取结果、邮件正文、搜索结果,在送到LLM之前都会经过一层token压缩:
- • HTML 转 Markdown
- • 长 URL 缩短
- • 非 ASCII 字符清理
- • 冗余信息剥离
而且它用了三层规则叠加,内置默认规则、用户自定义规则、项目级规则,全以JSON文件存储,改了不用重新编译。
4、桌面吉祥物
OpenHuman 的 Agent 有一个桌面形象——它会说话、会对环境做出反应、甚至会加入你的Meet会议作为一个真实的参会者。你可以让它替你参加会议、记笔记、回答问题。
5、模型路由
不同任务用不同模型,不需要你手动切换。
OpenHuman 内置了模型路由机制,每个任务会自动分配到合适的LLM——推理任务用强模型,简单任务用快模型,视觉任务用视觉模型。
还支持通过Ollama在本地跑模型,对隐私要求高的工作负载可以完全在设备端完成。
6、内置工具集
不需要装插件就能用:
- • Web搜索和网页抓取
- • 完整的编程工具集(文件系统、git、lint、test、grep)
- • 原生语音(STT输入,ElevenLabs TTS输出,吉祥物唇形同步)
- • Google Meet实时参会
所有这些工具都已内置,无需用户额外安装。
OpenHuman vs 其他Agent框架
让我们来看看OpenHuman和其他主流Agent框架的对比:
Claude Cowork | OpenClaw | Hermes Agent | OpenHuman | |
|---|---|---|---|---|
开源 | 🚫 专有 | ✅ MIT | ✅ MIT | ✅ GNU |
启动简单 | ✅ 桌面+CLI | ⚠️ 终端优先 | ⚠️ 终端优先 | ✅ 清爽 UI,几分钟内可用 |
成本 | ⚠️ 订阅+附加组件 | ⚠️ 自带模型 | ⚠️ 自带模型 | ✅ 一次订阅 + TokenJuice |
记忆 | ✅ 聊天范围 | ⚠️ 插件依赖 | ✅ 自学 | 🚀 记忆树 + Obsidian |
集成 | ⚠️ 连接较少 | ⚠️ 自带 | ⚠️ 自带 | 🚀 通过 OAuth 的 118+ |
自动获取 | 🚫 无 | 🚫 无 | 🚫 无 | ✅ 每 20 分钟同步 |
API 混乱 | 🚫 多个密钥 | 🚫 自带 | 🚫 多方提供 | ✅ 只需一个账户 |
模型路由 | 🚫 单一模型 | ⚠️ 手动 | ⚠️ 手动 | ✅ 内置 |
原生工具 | ✅ 仅代码 | ✅ 仅代码 | ✅ 仅代码 | ✅ 代码 + 搜索 + 抓取 + 语音 |
虾和马,本质还是你在教 AI。你得配 skill、写 prompt、调工作流。归根结底,你得先动,它们才动。
OpenHuman 不需要你教,连上你的 Gmail、GitHub、Slack、Notion、日历……118个服务一键接进来,每 20 分钟自动抓一遍新数据,压缩进一个Karpathy式的本地知识库。
快速上手
要开始使用OpenHuman,你可以直接访问 tinyhumans.ai/openhuman 下载,或运行以下命令在终端中进行安装:
对于 MacOS/Linux 用户:
curl -fsSL https://raw.githubusercontent.com/tinyhumansai/openhuman/main/scripts/install.sh | bash对于 Windows 用户:
irm https://raw.githubusercontent.com/tinyhumansai/openhuman/main/scripts/install.ps1 | iex安装完成后,你只需要做几件事:
- • 打开应用,完成简单的引导流程
- • 点击连接你常用的服务(Gmail、Notion、GitHub等)
- • 等待第一次同步完成(通常十几分钟)
- • 开始和你的私人AI助手对话
整个过程不需要配置文件,不需要命令行,几分钟内就能用上。
写在最后
虾马之后,OpenHuman 还能火,可能还是因为它刚好踩中了三个让开发者很头大的问题:
- • API密钥一大堆,每个平台都要单独配置
- • 各类平台数据分散难整合,上下文散落在各处
- • 上下文臃肿导致 AI 越用越卡顿,token消耗惊人
OpenHuman 一个账号搞定所有,不用反复注册、不用到处配置密钥;内置118+主流应用一键互联,自动拉取全平台数据同步进专属记忆树,全程后台静默运行、持续自主思考,最高还能节省80% token消耗与响应延迟。
而且,这三个痛点拆开是功能问题,合起来其实是还不够贴合用户真实使用习惯:之前的Agent,心思都花在"能干"上了,但在"懂你"这方面,始终差了点意思。
虾解决工具多的问题,马解决能自学的问题,但懂你的,或许还得Human来(doge)。
项目目前处于Early Beta阶段,还在快速迭代中。如果你想找一个真正懂你的私人AI助手,不妨试试看。
项目地址: https://github.com/tinyhumansai/openhuman
官方网站: https://tinyhumans.ai/openhuman
文档: https://tinyhumans.gitbook.io/openhuman/

如果本文对您有帮助,也请帮忙点个 赞👍 + 在看 哈!❤️
在看你就赞赞我!

本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-17,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号