Elasticsearch DiskBBQ 向量搜索 过滤速度提升 3–5 倍

Elasticsearch DiskBBQ 向量搜索 过滤速度提升 3–5 倍

点火三周
发布于 2026-05-20 15:13:30
发布于 2026-05-20 15:13:30
Elasticsearch DiskBBQ 向量搜索 过滤速度提升 3–5 倍
从向量搜索到强大的 REST API,Elasticsearch 为开发者提供了最全面的搜索工具包。欢迎访问 Elasticsearch Labs 仓库 中的示例 notebook,尝试新功能。您也可以立即开始 免费试用 或在本地 运行 Elasticsearch。
Elasticsearch 9.4 使具有严格过滤条件的 DiskBBQ 向量搜索 速度提升了 3–5 倍。DiskBBQ 是 Elasticsearch 新推出的基于分区的索引。它通过尽可能让向量索引与底层系统友好配合,力求在成本和性能之间取得最佳平衡。虽然 DiskBBQ 在处理宽泛过滤时表现良好,但在严格过滤条件下却不太理想。在我们持续追求简洁、快速、高效的向量索引的过程中,我们调整了应用过滤的方式,并显著降低了延迟。
分区索引过滤的难点
对于分区索引,所有搜索分两个阶段进行:
- • 找到最近的质心。
- • 在最近质心的簇内找到所有最近的向量。
对于 DiskBBQ,质心会经过量化,并可能在自己的结构中被索引。簇的内容(从现在起我们称为倒排列表)经过精心布局,以加快向量评分速度。倒排记录按 32 个为一组存储,每组按文档 ID 排序。文档 ID 使用增量编码来最小化磁盘占用,同时解码开销较低。向量值也采用块编码,将维度与量化修正值分开,以利用我们利用优化后的内核最大化单指令多数据流(SIMD)吞吐量。
1
2
3
4
5
6
向量簇(倒排列表)布局
| 元数据 |
| doc_deltas[32] | vec_quant[32] | vec_quant_corrections[32] |
| doc_deltas[32] | vec_quant[32] | vec_quant_corrections[32] |
| ... |
| doc_deltas[T] | vec_quant[T] | vec_quant_corrections[T] | (T <= 32)
一旦我们处理某个倒排列表,其布局已针对快速评分和过滤进行了优化。例如,如果提供了索引排序,匹配过滤条件的向量块会存储在一起,并在列表内一起评分。这允许一次连续评分多个向量块,充分利用底层 CPU 的吞吐能力。
也就是说,在我们实际检查文档 ID 之前,我们并不知道某个簇是否匹配给定的过滤条件。一旦确认,我们就能确保只对相关的向量进行评分。在严格过滤的场景中,我们检查一个质心后,可能会发现其中没有向量匹配过滤条件。为弥补这一问题,我们会持续评分和探索质心,直到获得一组有代表性的已评分向量。
这意味着对于严格过滤条件,存在大量无效工作:我们评分质心却不知道它们是否有匹配过滤条件的向量;准备对倒排列表进行评分,却发现所有块都不相关。这些无用的计算累积起来包括:
- • 不必要的质心评分。
- • 加载一个已经被过滤掉的倒排列表(因为它靠近查询向量)。
- • 解码并检查列表中的文档 ID,最后发现没有匹配项。
- • 继续搜索,可能又碰到另一个完全被过滤掉的质心,直到访问足够多的质心以达到期望的召回率。
下面是旧流程的示例:检查所有质心,查看哪些匹配,然后转向包含匹配向量的质心。重复此过程。

视频展示二维 DiskBBQ 分区搜索。首先展示没有过滤条件下找到最近质心和向量的过程。然后展示相同的搜索过程,但某些质心被过滤掉。这突出了被过滤的质心搜索中存在的无用工作。
视频展示二维 DiskBBQ 分区搜索。首先展示没有过滤条件下找到最近质心和向量的过程。然后展示相同的搜索过程,但某些质心被过滤掉。这突出了被过滤的质心搜索中存在的无用工作。
如何快速找到正确的质心找到正确的质心?
最简单的解决方案是跳过那些不包含有效向量的质心。但我们不希望为所有可能的过滤字段和值索引额外信息。用户可以提供各种复杂或简单的过滤条件。这是 Elasticsearch 的优势之一,我们不想削弱这一点。
取而代之的是,我们仅存储 doc_id -> centroid_ord 的映射关系。这让我们能够即时查看所有文档及其所属的质心。这样我们就可以按文档顺序遍历任何给定的过滤条件,快速确定相关的质心。当然,遍历每个文档以检查它是否通过过滤条件并不是免费的。只有当每簇中匹配过滤条件的文档平均数达到 1.25 时,我们才采用这种预取逻辑。是的,这是一个“魔法数字”,但它是基于经验得出的。假设过滤条件是随机的,我们在每个质心中验证至少一个匹配的向量,同时留有一些开销。未来我们可能会优化这个数值,但初步实验发现这个数对大多数用户来说是最佳的。

二维簇搜索示意图,展示新算法只访问那些与给定过滤条件匹配的质心。
二维簇搜索示意图,展示新算法只访问那些与给定过滤条件匹配的质心。
这是新方式:检测到是严格过滤条件后,直接跳到被过滤后的质心。
基准测试,基准测试,再基准测试
下面是一个包含随机过滤条件的宏观基准测试。过滤选择性被刻意设为极端值,以展示对极度严格过滤条件的显著改进。我们看到几乎有一个数量级的提升。以前,当过滤条件变得非常严格时,会出现一个糟糕的拐点。而现在延迟保持稳定,实际上随着过滤条件变得更严格,延迟还会改善。
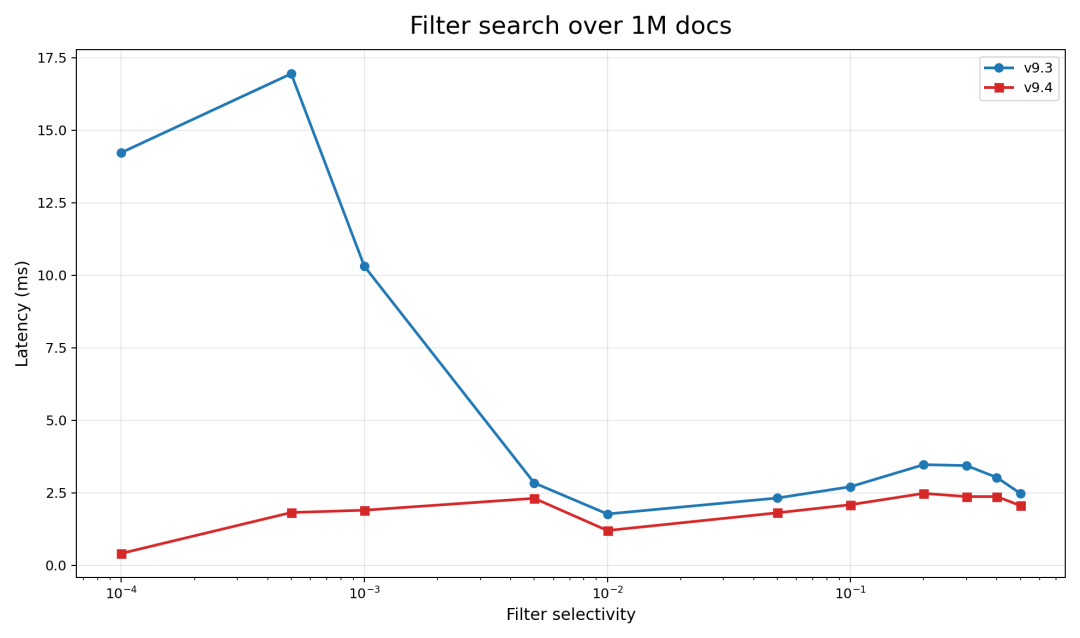
折线图,标题为“对 100 万文档的过滤搜索”,比较两个版本,延迟值在 log 尺度下相对于过滤选择性绘制。
折线图,标题为“对 100 万文档的过滤搜索”,比较两个版本,延迟值在 log 尺度下相对于过滤选择性绘制。
另一个验证是我们每晚使用 so-vector 和 rally 运行的 benchmark 也显示了改进。您可以通过在 rally 配置中指定 vector_index_type 为 bbq_disk 来亲自尝试。
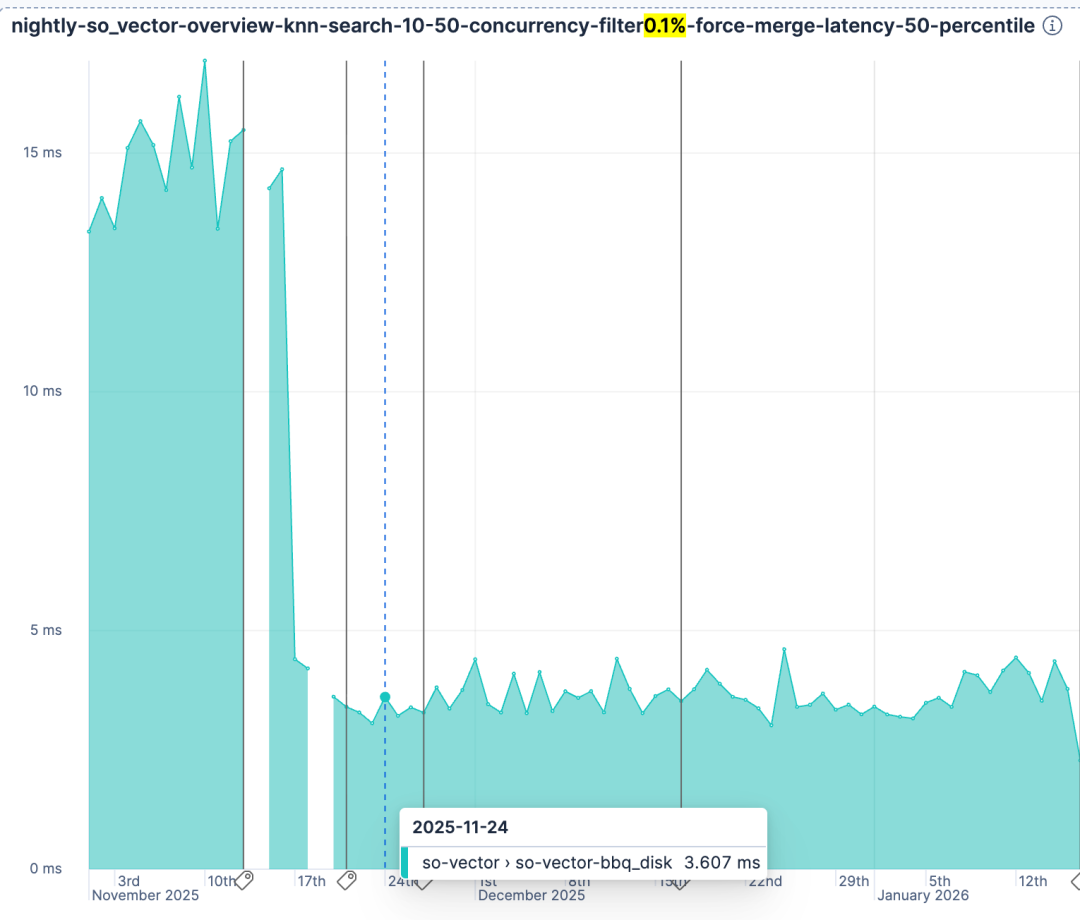
折线面积图,显示延迟随时间变化(毫秒),数值在 2025 年 11 月下旬急剧下降,工具提示标出一个数据点为 3.607 毫秒。
折线面积图,显示延迟随时间变化(毫秒),数值在 2025 年 11 月下旬急剧下降,工具提示标出一个数据点为 3.607 毫秒。
下一步是什么?
这个功能目前在 Elastic Serverless 中可用,并将包含在 Stack 9.4.0 版本中。我们并没有停止改进 Elasticsearch 中的向量搜索。这只是我们在为您提供简单、高效、实用且快速的向量搜索道路上迈出的又一步。非常感谢您使用我们编写的代码。我们 ❤️ 您。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-19,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号