混合专家模型MOE的概述


MoE(Mixture of Experts,混合专家模型)的核心思想,可以概括为“ 术业有专攻,分而治之 ”。
简单来说,它不是用一个庞大的“通才”模型来处理所有任务,而是将问题分解,交给一个由多个“专家”子模型组成的团队,并设置一个“路由”或“门控”机制来管理和调度,最终协同得出答案,能在不显著增加计算成本的前提下,极大提升模型的容量和性能。
1
核心原理
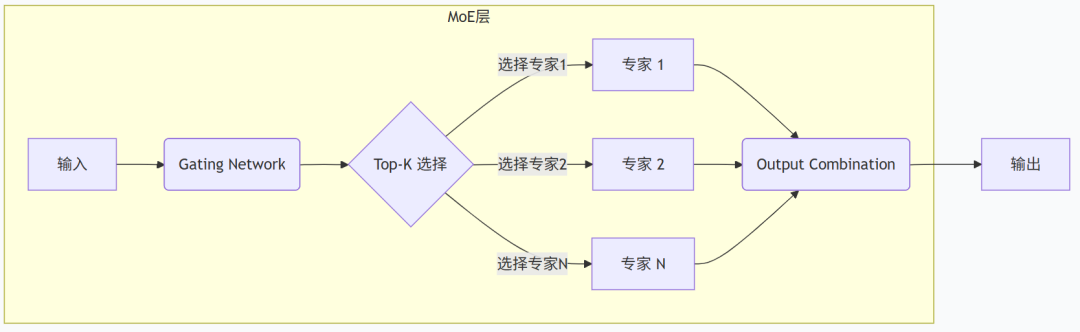
MoE架构的工作流程通常遵循一个清晰的路径,可以概括为“评估-评分-分配-处理-整合”:
- 输入评估 :当一个输入(如一个词或一个图像块)进入MoE层时, 门控网络首先分析这个输入,识别它的主要特征。
- 专家评分 :门控网络会为每一个“专家”模型打分,评估哪个或哪些专家最适合处理当前输入。
- 选择专家 :根据评分,只选择得分最高的Top-K个专家(K通常很小,如1或2)来处理这个输入,确保计算的稀疏性,即每次只有一小部分专家被激活。
- 任务处理 :被选中的专家独立处理分配给它的数据,每个专家专注于自己最擅长的领域。
- 结果整合 :门控网络将所有激活专家的输出进行加权组合,形成最终的预测结果。
2
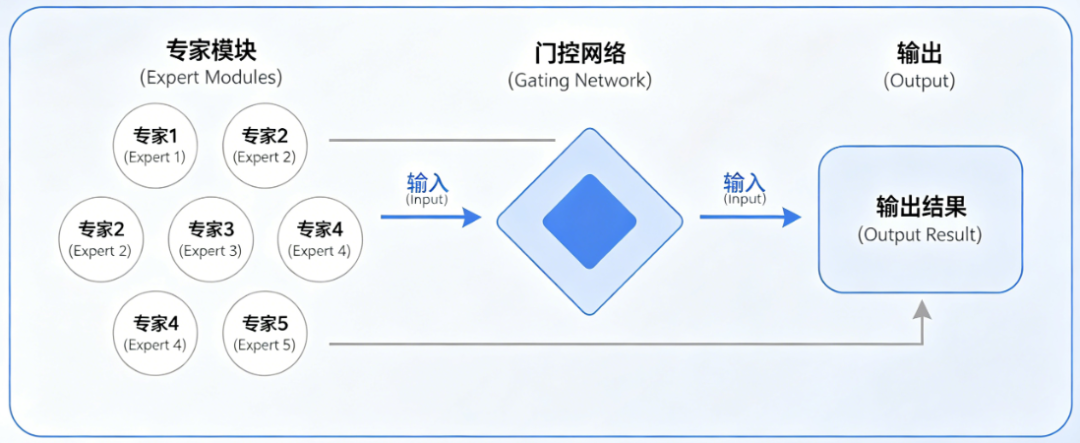
MoE 的两大核心组件
MoE架构主要由以下两个关键部分组成:
- 专家网络 :多个独立的、功能专一的子模型,在语言模型中,每个专家通常是一个小型的 前馈网络(FFN) 。通过训练,不同专家可以各自擅长不同的领域,比如一个精通数学推理,另一个擅长语法结构。
- 门控网络 :MoE架构的核心“大脑”,是一个轻量级的网络。它负责学习如何根据输入特征,动态地将任务分配给最合适的专家,通过计算每个专家的匹配分数,并激活得分最高的Top-K个专家来工作。
3
优劣势
MoE架构之所以能成为大模型的主流选择,主要得益于其独特的优势,但同时也面临着一些工程上的挑战:
优势一:计算效率与成本优势
- 稀疏激活 :每次推理只激活一小部分专家。例如,一个总参数量350亿的模型,运行时可能只激活30亿参数,其计算成本与30亿参数的模型相当,但知识储备却是350亿级别的。
- 易于扩展 :增加总参数主要靠增加专家数量,而计算量增长很少,为构建万亿级参数模型提供了可行路径。
优势二:性能与专业度提升
- 专家专业化 :通过分工,每个专家可以在特定任务上达到更高精度,从而提升整体模型能力。
- 训练更快 :在相同的计算预算下,MoE模型通常能比稠密模型更快地达到相同的性能水平。
主要挑战与当前解法
- 训练不稳定 :门控网络的学习和专家的协同容易出现波动。为此,DeepSeek等模型引入了细粒度专家划分和共享专家机制来优化。
- 负载不均衡 :少数专家可能被过度使用,导致资源浪费。当前主流解法是引入 辅助损失函数来鼓励路由器均匀分配任务。
- 显存需求高 :推理时虽只激活部分专家,但加载模型需要将所有专家的参数都加载到显存中,对硬件要求高。
- 通信瓶颈 :当专家分布在多张GPU上时,任务分发和结果汇总会产生巨大的通信开销,依赖高速互联技术(如NVLink)来解决。
4
变体
MoE架构已在多个前沿领域得到广泛应用,并衍生出多种创新变体:
- 主流大语言模型 :业界顶尖模型如 Mixtral 8x7B 、 DeepSeek-V3/R1 、 Grok-1 等都采用了MoE架构。DeepSeek通过 细粒度专家划分 和 共享专家隔离 等优化,有效缓解了传统MoE中知识混杂与知识冗余的问题。
- VLA模型 :在处理自动驾驶、机器人等需要同步处理视觉、语言、动作的复杂任务时,MoE的“分而治之”理念能实现高效融合。例如, ForceVLA 模型就引入了力感知MoE模块,让机器人能更好地适应细微的接触力变化。
- 多模态任务 :在需要处理文本、图像、语音等多种模态的任务中,MoE能为不同模态分配不同的专家进行并行处理,实现高效协同。
前沿变体
- 稀疏MoE :最常见的形式,通过Top-K路由确保稀疏激活。
- 软MoE :不进行硬性分配,而是让所有专家以不同权重共同处理所有输入。
- 分层MoE :构建多级路由体系,先选择专家组,再在组内选择具体专家,适合超大规模部署。
5
主流MOE模型概述
- Mixtral 8x7B :稀疏 MoE的先驱,将 8 个“专家”塞进一个模型里,但每个词只会请最厉害的两位专家来干活。
- DeepSeek-V3 :主打极致性价比,用创新的架构优化了MoE的经典难题。
- Grok-1 :追求规模极致,通过超大参数规模探索AI的性能边界。
- Qwen 系列 (Qwen2.5-Max / Qwen3-Next) :均衡的多面手,通过不断迭代架构,在性能、稀疏度和推理效率间寻求最佳平衡。
- 其他值得关注的模型 :包括NVIDIA的 Nemotron-4 340B 、微软的 Phi-3.5-MoE 等,在特定领域也各有千秋。
6
模型横向对比
特性 | Mixtral 8x7B | DeepSeek-V3 | Grok-1 | Qwen 系列 (2.5-Max/3-Next) |
|---|---|---|---|---|
发布机构 | Mistral AI | 深度求索 (DeepSeek) | xAI (马斯克) | 阿里巴巴 |
架构关键词 | 稀疏MoE | DeepSeekMoE (细粒度专家+共享专家) | 超大参数MoE | 高稀疏度MoE + 混合注意力 |
总参数量 | 467亿 | 6710亿 | 3140亿 (Grok-1) / 9050亿 (Grok-2) | 800亿 (Qwen3-Next) |
激活参数量 | 约130亿 | 约370亿 | 约860亿 (Grok-1) / 1360亿 (Grok-2) | 约30亿 |
上下文长度 | 32K | 128K | 128K (Grok-2) | 256K+ |
独特创新 | 首个真正成功的开源MoE | 细粒度专家 + 共享专家隔离 + 无辅助损失负载均衡 | 极致参数规模,整合X平台实时数据 | 混合注意力机制 + 多Token预测 (MTP) |
开源情况 | 完全开源 (Apache 2.0) | 完全开源 | 早期版本开源 (Grok-1) | 部分开源 (如Qwen3-Next) |
各模型解析
Mixtral 8x7B:稀疏MoE的实践先驱
Mixtral 8x7B的成功在于验证了MoE架构的实用价值,让业界看到了在有限算力下扩展模型规模的可能性。
工作机制 :模型的每一层都由8个“专家”(小型前馈网络)和一个“路由器”(门控网络)组成,对于每个输入的词元,路由器会动态选择最合适的2个专家来处理,最后将两者的输出融合。
优势 :
- 计算高效 :47B的总参数,推理时只激活约13B,计算量相当于13B的密集模型,但性能远超后者。
- 开源友好 :采用宽松的 Apache 2.0 许可,极大地降低了开发者应用和商业化的门槛。
- 社区繁荣 :作为开源先驱,拥有庞大的社区支持和丰富的微调、部署教程。
劣势 :
- 知识混杂与冗余 :较少的专家数量可能导致单个专家被迫学习多种知识,降低了专业化程度,这是经典MoE的通病。
- 专家负载不均衡 :容易出现少数专家被频繁调用而多数专家闲置的“赢家通吃”现象,造成参数浪费和训练困难。
DeepSeek-V3:用极致创新打造高性价比标杆
DeepSeek-V3通过一系列架构创新,有效解决了传统MoE的痛点,在极低的成本下实现了顶尖的性能,为行业提供了极具性价比的选择。
核心创新 :
- 细粒度专家分割 :将专家切得更细碎,更精细地学习不同知识,缓解了“知识混杂”问题。
- 共享专家隔离 :设置专门的“共享专家”处理通用知识,避免冗余存储,解决了“知识冗余”。
- 无辅助损失负载均衡 :创新性地通过引入偏置项来动态平衡专家负载,避免因强制均衡而损害模型性能。
优势 :
- 极致性价比 :总参数量高达671B,但每次推理只激活约37B参数。训练成本仅 约557万美元 ,性能却足以媲美GPT-4等顶尖闭源模型。
- 性能强劲 :在许多基准测试中,是开源模型的性能天花板。
劣势 :
- 部署门槛较高 :虽然激活参数量少,但加载整个671B的模型对 显存(VRAM) 要求依然很高。
Grok 系列:追求规模极致与实时数据整合
Grok系列的核心理念是通过极致的参数规模来探索性能边界。
工作机制 :与Mixtral类似,每层包含8个专家,每个词元激活其中2个专家来处理,Grok-1的激活参数量约86B,而Grok-2更是高达136B。
优势 :
- 知识储备庞大 :海量参数为模型提供了巨大的知识容量。
- 实时数据整合 :深度整合了X平台(原Twitter)的实时信息,在回答涉及最新事件的问题时具备独特优势。
- 长上下文支持 :Grok-2系列支持高达 128K 的上下文长度,能处理更长的文档和对话。
劣势 :
- 部署成本高昂 :需要顶级多卡GPU服务器才能运行。
- 推理速度偏慢 :激活的参数量大,导致推理延迟高于DeepSeek-V3和Mixtral等模型。
Qwen 系列:持续迭代的均衡派
Qwen系列是典型的均衡型选手,通过不断架构创新,在性能、推理效率和部署友好度之间取得了极佳的平衡。
核心创新 :
- 高稀疏度MoE结构 :总参数量达80B,每次推理只激活约3B参数。相比Qwen3-MoE的128总专家/8激活,Qwen3-Next扩展到 512总专家/10激活+1共享专家 。这种高稀疏度带来极高的参数效率,是Qwen实现高性能与低成本推理的关键。
- 混合注意力机制 :结合了线性注意力的高效和标准注意力的强召回能力,在长上下文任务中吞吐量可提升 10倍以上 。
- 多Token预测 (MTP) :同时预测多个未来词元,不仅提升了推理速度,还增强了模型的规划能力。
优势 :
- 推理成本极低 :以30亿激活参数实现接近更大模型的性能,让复杂模型在消费级GPU上运行成为可能。
- 性能卓越 :Qwen2.5-Max和Qwen3-Next在多项基准测试中均超越或比肩DeepSeek-V3和GPT-4o等顶尖模型。
劣势 :
- 开源策略不一 :部分最前沿版本(如Qwen2.5-Max)并未完全开源,这给开发者带来了一些不确定性。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-10,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号