派生表 → LATERAL JOIN,12 秒变 0.2 秒

派生表 → LATERAL JOIN,12 秒变 0.2 秒

PawSQL
发布于 2026-06-17 20:47:17
发布于 2026-06-17 20:47:17
一条 SQL 从 12 秒到 0.2 秒,我只改了一个关键字
今天给你分享一个我们在生产环境里踩过无数坑才摸透的SQL优化真实案例——问题出在滥用派生表(Derived Table),结果一张看似无害的子查询,让整个查询变成了全表扫描的噩梦。而 PawSQL 的一条重写规则,直接把性能从12秒拉到0.2秒。
先看一个真实到扎心的场景:
-- 查询每个用户最近3条订单
SELECT u.*, t.order_id, t.created_at
FROM users u,
(
SELECT *,
ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY created_at DESC) AS rn
FROM orders
) t
WHERE u.id = t.user_id
AND t.rn <= 3;100 万订单、10 万用户,这条 SQL 跑了12.3 秒。为什么?因为派生表先对orders全表计算了窗口函数,生成一个百万级的临时结果集,然后再和users关联过滤。绝大多数计算都是浪费的—— 你只需要每个用户的 3 条记录,却先算了所有用户的所有记录!
而我们把它改写成下面这样:
SELECT u.*, t.order_id, t.created_at
FROM users u,
LATERAL (
SELECT order_id, created_at
FROM orders
WHERE user_id = u.id
ORDER BY created_at DESC
LIMIT 3
) t;执行时间骤降到0.2 秒,性能提升61 倍!
这就是 PawSQL的派生表转换为Lateral表关联(DerivedTable2LateralJoin) 算法干的事:自动识别低效派生表,智能转换为 LATERAL JOIN + 下推条件 + LIMIT。
今天,我就带你深入解析这条重写优化的算法逻辑,并给出两个可以直接抄作业的优化案例。
为什么派生表经常成为性能杀手?
先看执行流程对比,一眼看懂差距:
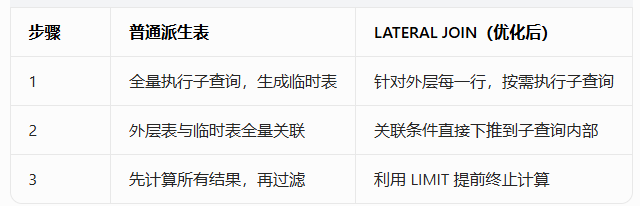
普通派生表是 "先做满汉全席,再挑 3 道菜吃";LATERAL JOIN 是 "你想吃 3 道菜,我就只做这 3 道菜"。
但手动改写 LATERAL JOIN 有两个致命痛点:
- 语法支持不均:MySQL 8.0、PostgreSQL、Oracle 支持,但老版本或某些数据库不支持
- 改写容易出错:窗口函数里的PARTITION BY、ORDER BY、LIMIT转换要严格等价,稍有不慎结果就错了。
PawSQL 的这条规则,就是帮你安全、自动地完成这个转换,让你不用再死磕 SQL 语法细节。
场景一:窗口函数 + 分页(90% 的 Top-N 查询都能这么改)
原始低效 SQL(你的代码里可能到处都是)
SELECT *
FROM (
SELECT *,
ROW_NUMBER() OVER (PARTITION BY dept_id ORDER BY salary DESC) AS rn
FROM employee
) t
WHERE t.rn <= 3;PawSQL 自动改写为
SELECT d.dept_name, t.*
FROM department d,
LATERAL (
SELECT *
FROM employee
WHERE dept_id = d.id
ORDER BY salary DESC
LIMIT 3
) t;算法核心逻辑
- 精准匹配模式:
- 派生表内只有一个窗口函数,且是
ROW_NUMBER()或RANK() - 窗口函数的
PARTITION BY字段完全等于外层关联字段 - 外层对窗口函数别名的过滤只能是
=、<或<=,且右值是常量或参数 - 窗口函数列不能出现在外层的
SELECT列表中(防止列丢失)
- 派生表内只有一个窗口函数,且是
- 智能推导 LIMIT:
rn <= 3 → LIMIT 3rn < 3 → LIMIT 2rn = 1 → LIMIT 1rn = 2 → LIMIT 1 OFFSET 1完美支持参数化:rn = ? → LIMIT ?-1, 1
适用场景
- "每个分组的前 N 条记录"(Top-N per group)
- "每个用户的最近几条日志 / 订单 / 消息"
- 配合分页接口,如
rn BETWEEN ? AND ?
场景二:分组聚合 + 外层 LIMIT(99.99% 的计算都是浪费)
原始低效 SQL
-- 查询每个用户的订单总额,只返回前10个用户
SELECT u.*, t.total
FROM users u,
(
SELECT user_id, SUM(amount) AS total
FROM orders
GROUP BY user_id
) t
WHERE u.id = t.user_id
ORDER BY u.id
LIMIT 10;问题:派生表先对orders全表分组聚合(假设有 100 万用户,就产生 100 万行),然后关联、排序、取前 10。99.99% 的聚合计算是浪费的!
PawSQL 自动改写为
SELECT u.*, t.total
FROM users u,
LATERAL (
SELECT SUM(amount) AS total
FROM orders
WHERE user_id = u.id
GROUP BY user_id
) t
ORDER BY u.id
LIMIT 10;算法核心逻辑
严格匹配条件:
- 派生表内有
GROUP BY,且GROUP BY字段包含所有外层关联字段, - 外层关联是等值条件(
=), - 派生表没有
LIMIT(否则可能破坏语义), - 智能触发阈值:只有当派生表预估行数 > 外层表预估行数,或外层查询有LIMIT时才触发改写,避免过度优化。
适用场景
- 大表分组聚合后与外层小表关联,且外层有过滤或
LIMIT - 例如:统计每个用户的累计消费、每个分类的商品数量,但只关心 Top N
为什么你的数据库优化器没做这个改写?
很多数据库(包括 MySQL 8.0 之前)的优化器不会自动将派生表转换为 LATERAL JOIN,因为:
- 需要评估两种执行计划的代价,而统计信息可能不准确;
LATERAL 语义在旧版本中不存在;- 转换涉及窗口函数删除、LIMIT 推导等复杂改写,优化器不敢轻易尝试。
PawSQL 作为外置 SQL 优化引擎,可以大胆且精细地完成这个转换,并通过严格的语义校验保证结果 100% 等价。
PawSQL 的"贴心"设计
除了上述基本转换,我们的规则还做了这些 "贴心" 设计:
- 全参数化支持:遇到 rn = ? 会生成 LIMIT ?-1, 1 ,完美保留预编译能力
- 多重安全网:严格检查窗口函数的
PARTITION BY与外层关联字段是否一致,防止结果错误 - 智能行数估算:在分组聚合场景下,只有判断内层行数大于外层行数时才触发,避免过度优化
- 自动反转谓词:处理
? = rn这种反人类写法。
性能实测(TPC-H 标准测试集)
测试环境:MySQL 8.0,100 万行 orders 表,10 万行 users 表,user_id 上有普通索引。
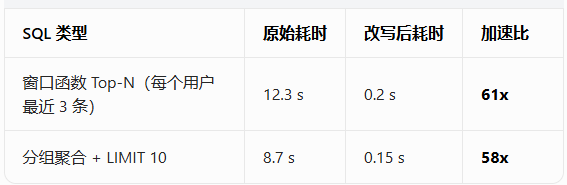
注意:实际加速比取决于数据分布和索引。如果 user_id 上有覆盖索引,LATERAL 版本几乎只扫描需要的行,性能还能再提升一个数量级!
如何 30 秒获得这个优化?
- 访问PawSQL Cloud
- 打开 SQL 审核 / 重写功能,确保规则
DerivedTable2LateralJoinRewrite已启用(默认开启) - 粘贴你的 SQL,点击 "优化",PawSQL 会输出改写后的等价 SQL 和执行计划对比
- 直接在数据库里执行改写后的 SQL,体验飞一般的感觉
当然,你也可以手动按照本文的案例模式改写,但请务必注意:
- 检查
PARTITION BY是否与关联字段完全一致 - 确认窗口函数的
ORDER BY能正确对应到ORDER BY ... LIMIT - 如果窗口函数列在外层被使用,需要额外处理
交给 PawSQL,省心又安全。
八、结语
派生表转 LATERAL JOIN,是 SQL 优化中 "性价比" 极高的手法。它能把 O (N²) 的复杂度降为 O (N * K),其中 K 是每个分组需要的记录数。
PawSQL 将这一复杂改写过程自动化、智能化,让开发者不再需要手动分析窗口函数、推导 LIMIT、下推条件。你只管写业务 SQL,优化交给我们。
目前,全球已有超过20,000 名专业数据库从业者在使用 PawSQL 的服务,支持 MySQL、PostgreSQL、Oracle、SQL Server 等20 + 种主流数据库。除了查询重写,我们还提供智能索引推荐、自动化性能验证、数据库性能巡检等一站式数据库性能优化解决方案。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-08,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号