Python ORM及sqlalchemy学习总结(上)

Python ORM及sqlalchemy学习总结(上)

Wangzy
发布于 2026-06-22 18:19:38
发布于 2026-06-22 18:19:38
#sqlalchemy
01
—
Python和数据库交互方式介绍
Python程序中与关系型数据库交互,主要有ORM、原生SQL和Pandas三种方案,它们各自适用不同场景,且存在其他补充方案。以下是详细分析和对比:
1、ORM(对象关系映射)
代表库:SQLAlchemy(flask_sqlalchemy,tornado_sqlalchemy等)、Django ORM、Peewee。
适用场景:
- 业务逻辑复杂的应用:适合Web应用(如Django/Flask项目),将数据库表映射为Python类,简化CRUD操作。
- 快速开发与维护:自动生成SQL,避免手写错误;支持事务、连接池、数据迁移(Alembic)。
- 跨数据库兼容:如SQLAlchemy支持多种数据库(PostgreSQL/MySQL/SQLite),切换时无需重写SQL。
- 关系操作:处理一对多、多对多等关联查询时更直观(如user.addresses)。
局限性:
- 复杂查询性能可能低于原生SQL;
- 深度优化需理解ORM生成的SQL,可能需回退到原生SQL。
2、原生SQL(通过DB-API驱动)
- 代表库: psycopg2 (PostgreSQL)、mysql-connector (MySQL)、sqlite3
适用场景:
- 高性能复杂查询:需精细控制SQL时(如窗口函数、复杂JOIN、存储过程调用)。
- 数据库特性依赖:使用特定数据库的高级功能(如PostGIS空间计算)。
- 存量SQL迁移:复用已有SQL脚本或DBA提供的优化SQL。
- 大数据批量操作:结合COPY命令(PostgreSQL)或LOAD DATA(MySQL)高速导入导出。
局限性:
- 手动处理连接/事务,易出错;
- SQL注入风险(需用参数化查询);
- 可移植性差(数据库切换需重写SQL)。
3、Pandas
代表方法: pandas.read_sql(), df.to_sql()
适用场景:
- 数据分析与处理:将查询结果加载为DataFrame,进行清洗、统计、可视化(配合Matplotlib/Seaborn)。
- 批处理/ETL:对查询结果执行复杂转换(如分组聚合、时间序列分析),再写回数据库。
- 探索性工作:在Jupyter中交互式分析数据库内容。
局限性:
- 内存限制(大数据需分块处理);
- 不适合高频小操作(每次操作需连接/序列化);
- to_sql()写入性能较低(可启用method="multi"或批量提交优化)。_
4、其他交互方案
a) SQL表达式语言(如SQLAlchemy Core)
定位:介于ORM和原生SQL之间,以Python代码构建SQL抽象。
场景:需动态生成SQL(如条件过滤)、避免SQL注入,同时保留对SQL结构的控制权。
from sqlalchemy import select, table
users = table('users')
query = select(users).where(users.c.id > 100)b) 异步驱动(如asyncpg、aiomysql)
场景:异步框架(FastAPI、Tornado)中非阻塞访问数据库,提升并发性能。
c) 查询构建器(如Pypika)
场景:无需ORM重量级功能,但希望以链式调用生成SQL(类似Knex.js)。
d) 数据库抽象层(如SQLAlchemy Engine)
场景:统一管理连接池、方言适配,作为底层驱动供ORM/Pandas使用。
02
—
ORM(对象关系映射)
1、什么是 ORM?
ORM(Object-Relational Mapping,对象关系映射)是一种编程技术,用于在面向对象语言(如 Python)和关系型数据库(如 MySQL、PostgreSQL)之间建立映射关系。它的核心思想是:
- 将数据库中的表映射为 Python类(Class)
- 将表中的列(字段)映射为类的属性
- 将表中的行(数据记录)映射为类的实例对象
- 将 SQL 操作(如增删改查)封装为类的方法
使用ORM(对象关系映射)相比直接编写SQL,能显著减少重复代码,可以大大提高开发效率,并减少SQL注入的风险。
关于减少重复代码,通过如下对比例子,就能看出ORM的的优势。
a、直接使用SQL(条件拼接易出错)
def get_user_by_email(email):
sql = "SELECT * FROM users WHERE email = %s" # 需手动保证字段名正确
cursor.execute(sql, (email,))
return cursor.fetchone()
# 分页查询需重写SQL
def get_users(page=1, per_page=10):
offset = (page-1) * per_page
sql = f"SELECT * FROM users LIMIT {per_page} OFFSET {offset}" # 易出现SQL注入风险
cursor.execute(sql)
return cursor.fetchall()b、使用ORM(复用查询方法)
`` # 查询逻辑通过模型类复用
`` user = User.query.filter_by(email="alice@example.com").first() # 自动映射字段
``
`` # 分页查询使用统一接口
`` users = User.query.paginate(page=1, per_page=10) # 无需重写LIMIT/OFFSET逻辑2、sql注入介绍
上面提到使用ORM可以减少sql注入的风险,所以这个章节顺便也介绍下什么是sql注入。
SQL 注入是一种非常常见且危险的 Web 安全漏洞。它发生在攻击者能够将恶意的 SQL 代码“注入”或“插入”到应用程序原本要发送给数据库的查询语句中。其核心原因在于应用程序对用户输入的数据没有进行充分、安全的验证、过滤或转义,就直接将这些数据拼接到了 SQL 查询语句中执行。
举个典型的登录场景的例子:
一个平台用户,在登录表单中输入用户名 (`username`) 和密码 (`password`),应用程序后台代码(比如 PHP、Python、Java 等)可能会这样构建 SQL 查询:`SELECT * FROM users WHERE username='输入的用户名' AND password='输入的密码';`
攻击者不会输入正常的用户名和密码。例如,在用户名输入框中,他输入:`' OR 1=1 --`
那么最终传到应用的sql语句就变成了如下:
`` SELECT * FROM users WHERE username='' OR 1=1 -- ' AND password = 'anything';熟悉sql语法的同学应该都知道,如上语句实际在数据库中执行的语句就变成了如下:
`` SELECT * FROM users WHERE username='' OR 1=1;应用程序的逻辑通常是:如果查询返回了至少一行记录,就认为登录成功。攻击者利用这个漏洞,即使不知道任何真实的用户名和密码,也能成功登录。
如上就是sql注入的一个典型例子,黑客可以在sql中再注入其他的语句,比如查询其他的任意表的数据,删除表数据,如果数据库用户权限控制不好的话,甚至可以做删库的动作。
03
—
SQLAlchemy
笔者在工作中主要以web应用开发为主,用的python框架主要是flask和tornado。
所以用到的ORM方案基本都是sqlalchemy(包含同步和异步),少量场景用pandas。本文主要介绍同步方式的sqlalchemy使用,后续再总结sqlalchemy异步的学习总结。接下来就该sqlalchemy出场了,ORM在python语言中最具代表性的库就是sqlalchemy。`sqlalchemy`、`flask_sqlalchemy`和`tornado_sqlalchemy`三个常用库均依赖 SQLAlchemy 的核心 ORM 功能。
1、SQLAlchemy设计理念
根据SQLAlchemy的中文社区文档(https://sqlalchemy.org.cn/philosophy.html)介绍的理念如下:
SQL 数据库的行为越不像对象集合,规模和性能就越重要;对象集合的行为越不像表和行,抽象就越重要。SQLAlchemy 旨在兼顾这两种原则。
SQLAlchemy 将数据库视为关系代数引擎,而不仅仅是表的集合。行不仅可以从表中选择,还可以从连接和其他选择语句中选择;这些单元中的任何一个都可以组合成更大的结构。SQLAlchemy 的表达式语言在其核心基础上构建了这一概念。
SQLAlchemy 最著名的是其对象关系映射器 (ORM),这是一个可选组件,它提供了数据映射器模式,其中类可以以开放式的、多种方式映射到数据库——允许对象模型和数据库模式从一开始就以清晰解耦的方式进行开发。
SQLAlchemy 解决这些问题的总体方法与大多数其他 SQL / ORM 工具完全不同,它植根于一种所谓的互补性导向方法;所有过程不是将 SQL 和对象关系细节隐藏在自动化的墙后,而是完全暴露在一系列可组合的、透明的工具中。该库承担了自动化冗余任务的工作,而开发人员仍然可以控制数据库的组织方式以及 SQL 的构造方式。
SQLAlchemy 的主要目标是改变您对数据库和 SQL 的思考方式!
2、SQLAlchemy介绍:
SQLAlchemy 由两个不同的组件组成,称为 Core 和 ORM。 Core 本身是一个功能齐全的 SQL 抽象工具包,为各种 DBAPI 实现和行为提供了一个平滑的抽象层,以及一种 SQL 表达式语言,允许通过生成式 Python 表达式来表达 SQL 语言。一个可以发出 DDL 语句以及自省现有模式的模式表示系统,以及一个允许将 Python 类型映射到数据库类型的类型系统,完善了这个系统。对象关系映射器是建立在 Core 之上的一个可选包。许多应用程序完全基于 Core 构建,使用 SQL 表达式系统来提供对数据库交互的简洁而精确的控制。
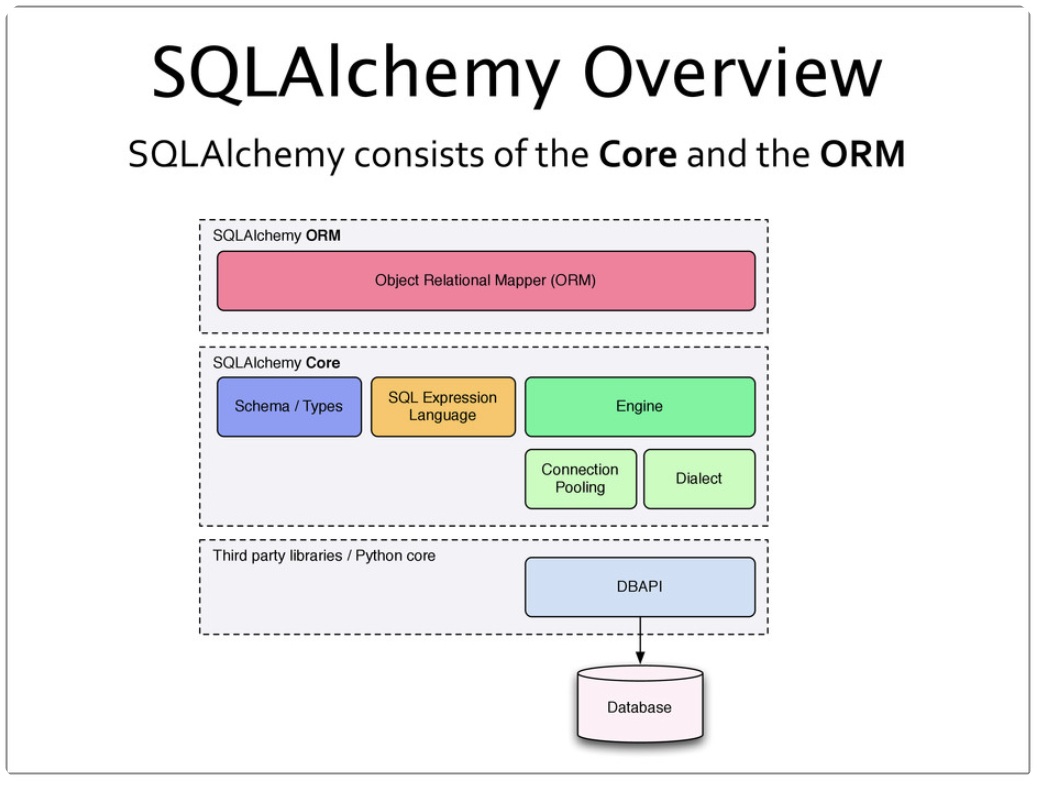


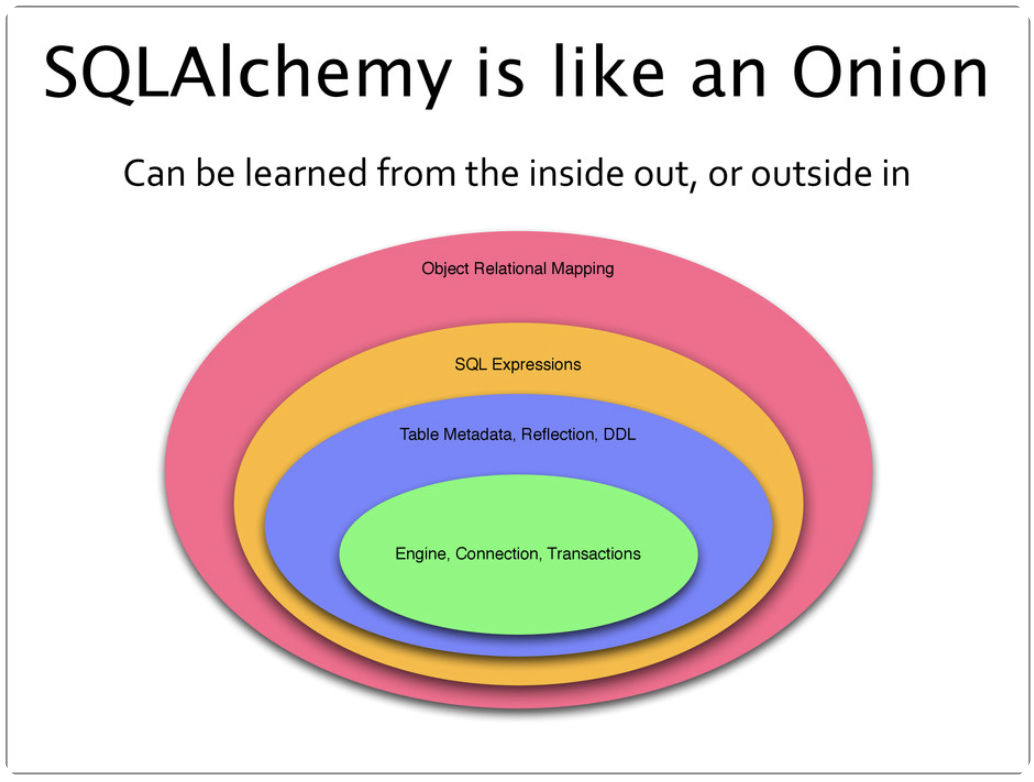
SQLAlchemy 适用用于 SQLite、Postgresql、MySQL 和 MariaDB、Oracle 和 MS-SQL 等,其中大多数支持多个 DBAPI。SQLAlchemy 支持同步和异步驱动程序,允许与 asyncio 一起使用。
3、sqlalchemy的版本介绍
a、早期版本(0.6 及之前)
代表版本:0.6(2010 年)
将数据库方言拆分为 sqlalchemy.dialects 子包,支持更灵活的驱动指定(如 postgresql+pg8000://)。
b、SQLAlchemy 1.2(2017 年)
Baked Queries 成为默认惰性加载策略:大幅减少关系加载(lazy="select")时的函数调用开销,通过预编译查询结构提升性能。
c、SQLAlchemy 1.4(2021 年)—— 2.0 的过渡基石
统一 Core 与 ORM 查询模型:允许 ORM 直接使用 Core 的 select() 构造查询,为 2.0 风格铺路。
全查询缓存:对所有 SQL 编译结果缓存,减少重复开销。
异步支持(asyncio):通过 AsyncEngine 和 AsyncSession 支持 async/await 模式。
未来模式(Future API):通过参数启用 2.0 行为:
d、SQLAlchemy 2.0(2023 年)—— 现代化重构
目标:适配 Python 3.6+、类型提示、异步及更严格的 API 设计。
ORM 查询接口革命:
废弃 Query 对象,改用 select() + Session.execute(),返回 Result。
强类型整合:
原生支持 PEP-484,ORM 声明模型可直接注解字段类型。
异步深度集成:
异步API(AsyncSession),支持全链路 async。
性能优化:
INSERT 批处理加速
反射元数据效率提升。
e、SQLAlchemy 2.1 --从官方文档来看,2.1版本已经在开发中了。

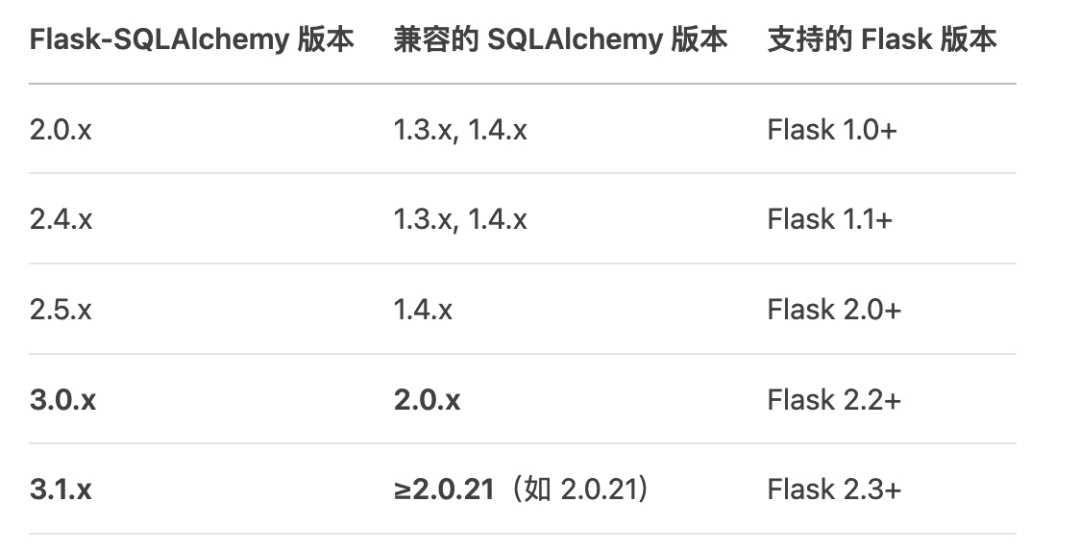
flask-sqlalchemy和sqlalchemy版本对应关系如下:
4、SQLAlchemy Engine(基于SQLAlchemy2.0版本)
Engine 是任何 SQLAlchemy 应用程序的起点。它是实际数据库及其 DBAPI 的 “基地”,通过连接池和 Dialect 传递给 SQLAlchemy 应用程序,Dialect 描述了如何与特定类型的数据库/DBAPI 组合进行通信。
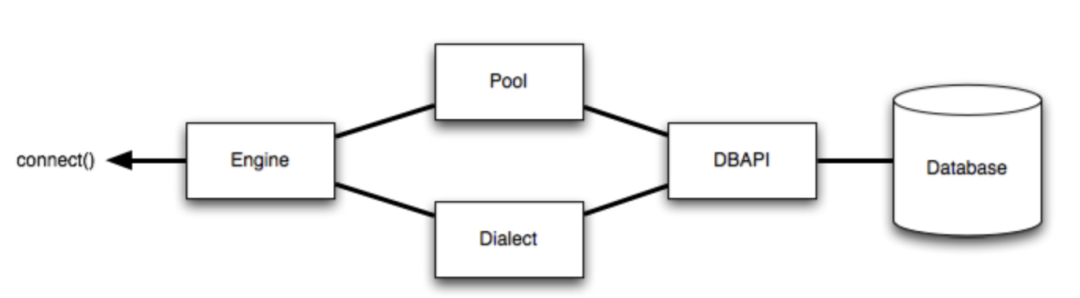
上图中所示,Engine 同时引用 Dialect 和 Pool,它们共同解释 DBAPI 的模块功能以及数据库的行为。
创建引擎只是发出一个简单的调用,createengine()
from sqlalchemy import create_engine
engine = create_engine("postgresql+psycopg2://scott:tiger@localhost:5432/mydatabase")上面的引擎创建了一个针对 PostgreSQL 定制的 Dialect 对象,以及一个 Pool 对象,该对象将在首次收到连接请求时在 localhost:5432 建立 DBAPI 连接。请注意,Engine 及其底层 Pool 在调用 Engine.connect() 或 Engine.begin() 方法之前,不会 建立第一个实际的 DBAPI 连接。ORM Session 对象等其他 SQLAlchemy Engine 依赖对象在首次需要数据库连接时也可能调用这些方法中的任何一种。通过这种方式,可以说 Engine 和 Pool 具有延迟初始化行为。
Engine 一旦创建,可以直接用于与数据库交互,也可以传递给 Session 对象以使用 ORM。本节介绍配置 Engine 的详细信息。下一节 使用引擎和连接 将详细介绍 Engine 和类似对象的用法 API,通常用于非 ORM 应用程序。
SQLAlchemy 包含许多用于各种后端的Dialect实现。最常见数据库的 Dialect 包含在 SQLAlchemy 中;少数其他数据库的 Dialect 需要额外安装单独的 dialect。
5、SQLAlchemy Connection(基于SQLAlchemy2.0版本)
当使用 SQLAlchemy ORM 时,通常不会访问使用Connection,使用Session对象用作数据库的接口。
如果直接使用文本 SQL 语句和/或 SQL 表达式构造而构建的应用程序,而无需 ORM 的更高级别管理服务的参与,这时候就应该使用 Engine 和 Connection。
Engine 最基本的功能是提供对 Connection 的访问,然后可以调用 SQL 语句。向数据库发出文本语句如下所示
from sqlalchemy import text
with engine.connect() as connection:
result = connection.execute(text("select username from users"))
for row in result:
print("username:", row.username)上面,Engine.connect() 方法返回一个 Connection 对象,并通过在 Python 上下文管理器(例如 with: 语句)中使用它,Connection.close() 方法在块的末尾自动调用。
Connection 是实际 DBAPI 连接的代理对象。 DBAPI 连接在创建 Connection 时从连接池中检索。
返回的对象称为 CursorResult,它引用 DBAPI 游标并提供类似于 DBAPI 游标的方法来获取行。
当 CursorResult 的所有结果行(如果有)都耗尽时,DBAPI 游标将由 CursorResult 关闭。
不返回行的 CursorResult,例如 UPDATE 语句(没有任何返回行),会在构造后立即释放游标资源。
当 Connection 在 with: 块的末尾关闭时,引用的 DBAPI 连接将释放到连接池。
从数据库本身的视角来看,假设池有空间存储此连接以供下次使用,则连接池实际上不会“关闭”连接。
当连接返回到池以供重用时,池机制会在 DBAPI 连接上发出 rollback() 调用,以便删除任何事务状态或锁(这称为 返回时重置),并且连接已准备好下次使用。
6、SQLAlchemy 连接池(基于SQLAlchemy2.0版本)
由 Engine 返回的 create_engine() 函数在大多数情况下都集成了 QueuePool,并预先配置了合理的池默认值。
最常见的 QueuePool 调整参数可以直接作为关键字参数传递给 create_engine(): pool_size, max_overflow, pool_recycle 和 pool_timeout。 _
例如:
`` engine = create_engine(
`` "postgresql+psycopg2://me@localhost/mydb", pool_size=20, max_overflow=0
`` )所有 SQLAlchemy 池实现的共同点是它们都没有“预先创建”连接 - 所有实现都等到首次使用时才创建连接。 在那时,如果没有对更多连接的额外并发检出请求,则不会创建额外的连接。 这就是为什么 create_engine() 默认使用大小为 5 的 QueuePool 而无需考虑应用程序是否真的需要排队 5 个连接是完全可以的 - 只有当应用程序实际并发使用 5 个连接时,池才会增长到该大小,在这种情况下,使用小池是完全合适的默认行为。
注意:QueuePool 类与 asyncio 不兼容。 当使用 create_async_engine 创建 AsyncEngine 实例时,将使用 AsyncAdaptedQueuePool 类,该类使用 asyncio 兼容的队列实现。
`pool_reset_on_return`参数: “返回时重置”行为,当连接返回到池时,它将调用 DBAPI 连接的 rollback() 方法。 这是为了从连接中删除任何现有的事务状态,这不仅包括未提交的数据,还包括表和行锁。 对于大多数 DBAPI,调用 rollback() 的成本很低,如果 DBAPI 已经完成事务,则该方法应该是空操作。
`` non_acid_engine = create_engine(
`` "mysql://scott:tiger@host/db",
`` pool_reset_on_return=None,
`` isolation_level="AUTOCOMMIT",
`` )`pool_pre_ping` 参数:连接池测试ping处理。在每次连接池检出开始时在 SQL 连接上发出测试语句,以测试数据库连接是否仍然可用。 该实现是特定于方言的,并且使用 DBAPI 特定的 ping 方法,或者使用简单的 SQL 语句(如“SELECT 1”),以便测试连接的可用性。
`` engine = create_engine("mysql+pymysql://user:pw@host/db", pool_pre_ping=True)该方法为连接检出过程增加了一点开销,但是否则是完全消除由于陈旧的池连接引起的数据库错误的最简单和最可靠的方法。 调用应用程序无需担心组织操作以便能够从从池中检出的陈旧连接中恢复。
7、SQLAlchemy session(基于SQLAlchemy2.0版本)
a、打开和关闭session
Session 可以单独构造,也可以使用 sessionmaker 类构造。它通常预先传递一个 Engine 作为连接源。
`` from sqlalchemy import create_engine
`` from sqlalchemy.orm import Session
``
`` # an Engine, which the Session will use for connection
`` # resources
`` engine = create_engine("postgresql+psycopg2://scott:tiger@localhost/")
``
`` # create session and add objects
`` with Session(engine) as session:
`` session.add(some_object)
`` session.add(some_other_object)
`` session.commit()在上面的例子中,Session 使用与特定数据库 URL 关联的 Engine 实例化。然后在 Python 上下文管理器(即 with: 语句)中使用它,以便在代码块结束时自动关闭;这等效于调用 Session.close() 方法。
调用 Session.commit() 是可选的,仅当我们在 Session 中完成的工作包括要持久化到数据库的新数据时才需要。如果我们仅发出 SELECT 调用,而不需要写入任何更改,则调用 Session.commit() 是不必要的。
b、构建 begin / commit / rollback 代码块
对于我们将数据提交到数据库的情况,我们还可以将 Session.commit() 调用和事务的整体“构建”包含在上下文管理器中。“构建”的意思是,如果所有操作都成功,将调用 Session.commit() 方法,但如果引发任何异常,将调用 Session.rollback() 方法,以便立即回滚事务,然后再向外传播异常。在 Python 中,这最基本地使用 try: / except: / else: 代码块表示,例如
`` # verbose version of what a context manager will do
`` with Session(engine) as session:
`` session.begin()
`` try:
`` session.add(some_object)
`` session.add(some_other_object)
`` except:
`` session.rollback()
`` raise
`` else:
`` session.commit()通过使用 Session.begin() 方法返回的 SessionTransaction 对象,可以更简洁地实现上述长序列操作,该对象为相同的操作序列提供了上下文管理器接口
`` # create session and add objects
`` with Session(engine) as session:
`` with session.begin():
`` session.add(some_object)
`` session.add(some_other_object)
`` # inner context calls session.commit(), if there were no exceptions
`` # outer context calls session.close()更简洁地说,可以将两个上下文组合在一起
`` # create session and add objects
`` with Session(engine) as session, session.begin():
`` session.add(some_object)
`` session.add(some_other_object)
`` # inner context calls session.commit(), if there were no exceptions
`` # outer context calls session.close()c、使用 sessionmaker
sessionmaker 的目的是为具有固定配置的 Session 对象提供工厂。由于应用程序通常在模块范围内具有 Engine 对象,因此 sessionmaker 可以为针对此引擎构造的 Session 对象提供工厂
`` from sqlalchemy import create_engine
`` from sqlalchemy.orm import sessionmaker
``
`` # an Engine, which the Session will use for connection
`` # resources, typically in module scope
`` engine = create_engine("postgresql+psycopg2://scott:tiger@localhost/")
``
`` # a sessionmaker(), also in the same scope as the engine
`` Session = sessionmaker(engine)
``
`` # we can now construct a Session() without needing to pass the
`` # engine each time
`` with Session() as session:
`` session.add(some_object)
`` session.add(some_other_object)
`` session.commit()
`` # closes the sessionsessionmaker 类似于 Engine,作为函数级会话/连接的模块级工厂。因此,它也有自己的 sessionmaker.begin() 方法,类似于 Engine.begin(),它返回 Session 对象,并维护 begin/commit/rollback 代码块
`` from sqlalchemy import create_engine
`` from sqlalchemy.orm import sessionmaker
``
`` # an Engine, which the Session will use for connection
`` # resources
`` engine = create_engine("postgresql+psycopg2://scott:tiger@localhost/")
``
`` # a sessionmaker(), also in the same scope as the engine
`` Session = sessionmaker(engine)
``
`` # we can now construct a Session() and include begin()/commit()/rollback()
`` # at once
`` with Session.begin() as session:
`` session.add(some_object)
`` session.add(some_other_object)
`` # commits the transaction, closes the session在上面代码中,当 with: 代码块结束时,Session 将提交其事务,并且 Session 将被关闭。
当您编写应用程序时,sessionmaker 工厂的作用域应与 Engine 对象的作用域相同,该对象由 create_engine() 创建,通常在模块级或全局范围内。由于这些对象都是工厂,因此可以同时被任意数量的函数和线程使用。
8、Flask和SQLAlchemy
Flask 应用与 SQLAlchemy Session 绑定使用,包括两种实现方式:使用 Flask-SQLAlchemy 扩展和手动管理。
对于大多数 Flask 应用,推荐使用 Flask-SQLAlchemy 扩展以获得最佳开发体验。
初始化:db = SQLAlchemy(app) 自动处理应用上下文绑定。
请求生命周期:
@app.before_request:创建新的 session 并绑定到 g 对象
@app.teardown_request:自动处理提交/回滚和关闭 session_
访问 Session:通过 g.db_session 在视图函数中获取当前请求的 session_
事务管理:不需要手动 commit/rollback,异常时会自动回滚
具体代码如下:
`` from flask import Flask, g
`` from flask_sqlalchemy import SQLAlchemy
``
`` app = Flask(__name__)
`` app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///app.db'
`` app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
``
`` # 初始化扩展
`` db = SQLAlchemy(app)
``
`` # 定义模型
`` class User(db.Model):
`` id = db.Column(db.Integer, primary_key=True)
`` username = db.Column(db.String(80), unique=True, nullable=False)
`` email = db.Column(db.String(120), unique=True, nullable=False)
``
`` def __repr__(self):
`` return f'<User {self.username}>'
``
`` # 创建数据库表(首次运行时)
`` @app.before_first_request
`` def create_tables():
`` db.create_all()
``
`` # 请求前获取 session
`` @app.before_request
`` def before_request():
`` # 将 session 绑定到 g 对象
`` g.db_session = db.session
``
`` # 请求后清理 session
`` @app.teardown_request
`` def teardown_request(exception=None):
`` # 从 g 对象获取 session
`` session = getattr(g, 'db_session', None)
``
`` if session is not None:
`` if exception is None:
`` # 请求成功时提交事务
`` session.commit()
`` else:
`` # 请求失败时回滚事务
`` session.rollback()
`` # 关闭 session
`` session.close()
``
`` # 使用示例路由
`` @app.route('/add_user/<username>/<email>')
`` def add_user(username, email):
`` try:
`` # 从 g 对象获取当前请求的 session
`` session = g.db_session
``
`` # 创建新用户
`` new_user = User(username=username, email=email)
`` session.add(new_user)
``
`` # 不需要手动 commit,teardown_request 会处理
`` return f"User {username} added successfully!"
`` except Exception as e:
`` # 不需要手动 rollback,teardown_request 会处理
`` return f"Error: {str(e)}", 500
``
`` # 查询示例
`` @app.route('/users')
`` def list_users():
`` # 从 g 对象获取当前请求的 session
`` session = g.db_session
``
`` users = session.query(User).all()
`` return '<br>'.join([str(user) for user in users])
``
`` if __name__ == '__main__':
`` app.run(debug=True)04
—
总结
以上是python ORM以及sqlalchemy的学习总结,虽然写了几年的flask代码,但是对于sqlalchemy底层逻辑一直不太了解,基于这篇文章总算对sqlalchemy的底层逻辑有了初步的认识,也希望能帮助同样的sqlalchemy不太了解的同学。
本文主要是针对sqlalchemy同步方式的介绍,以及在Flask中的应用,后续会持续整理sqlalchemy异步方式的总结,以及在tornado框架中的应用,敬请期待。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-07-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号