华为910B4八卡服务器部署deepseek v4 flash记录

华为910B4八卡服务器部署deepseek v4 flash记录

用户12553134
发布于 2026-06-22 20:21:22
发布于 2026-06-22 20:21:22
花了两天时间终于在成功在华为910B4八卡服务器部署deepseek v4 flash。
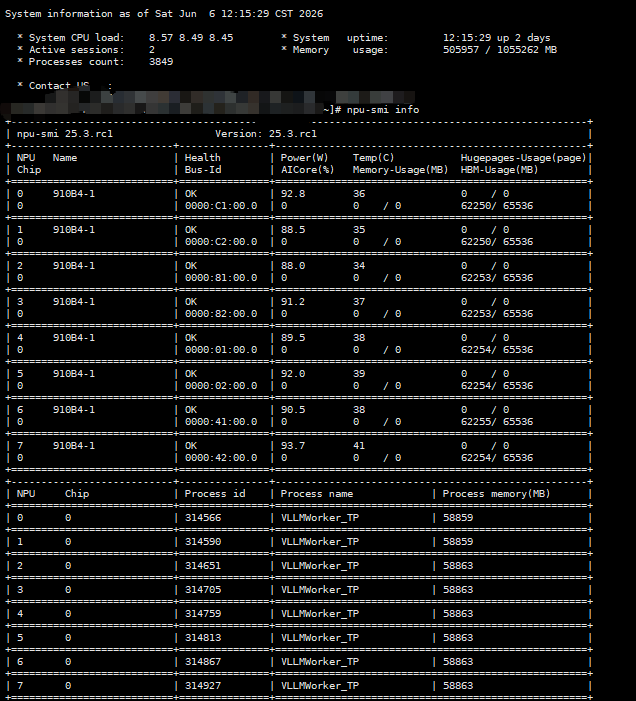
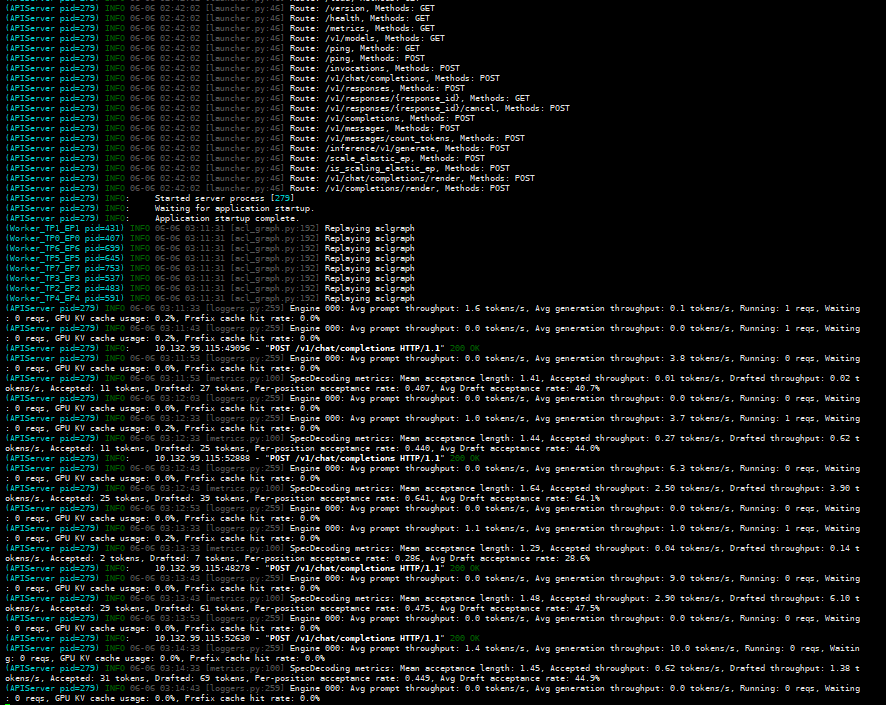

将镜像文件,权重文件rsync到另外四台服务器测试,也都成功拉起服务。
详细脚本如下
cd /data/docker
docker load -i vllm-ascend-deepseekv4.tar
docker run -it -d \
--name vllm-ascend-ds \
--net=host \
--shm-size=50g \
--privileged \
--device /dev/davinci0 \
--device /dev/davinci1 \
--device /dev/davinci2 \
--device /dev/davinci3 \
--device /dev/davinci4 \
--device /dev/davinci5 \
--device /dev/davinci6 \
--device /dev/davinci7 \
--device /dev/davinci_manager \
--device /dev/devmm_svm \
--device /dev/hisi_hdc \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /usr/local/Ascend/driver/tools/hccn_tool:/usr/local/Ascend/driver/tools/hccn_tool \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /usr/local/Ascend/driver/lib64/:/usr/local/Ascend/driver/lib64/ \
-v /usr/local/Ascend/driver/version.info:/usr/local/Ascend/driver/version.info \
-v /etc/ascend_install.info:/etc/ascend_install.info \
-v /etc/hccn.conf:/etc/hccn.conf \
-v /data/weights/DeepSeek-V4-Flash-w8a8-mtp:/models \
quay.io/ascend/vllm-ascend:deepseekv4 \
bash
docker exec -it vllm-ascend-ds bash
#!/usr/bin/bash
export LD_PRELOAD=/usr/lib/aarch64-linux-gnu/libjemalloc.so.2:$LD_PRELOAD
export OMP_PROC_BIND=false
export OMP_NUM_THREADS=8
export PYTORCH_NPU_ALLOC_CONF=expandable_segments:True
export ACL_OP_INIT_MODE=1
export VLLM_ASCEND_ENABLE_FLASHCOMM1=1
export USE_MULTI_GROUPS_KV_CACHE=1
export TASK_QUEUE_ENABLE=1
export HCCL_OP_EXPANSION_MODE="AIV"
export HCCL_BUFFSIZE=512
export USE_MULTI_BLOCK_POOL=1
sysctl -w vm.swappiness=0
sysctl -w kernel.numa_balancing=0
sysctl kernel.sched_migration_cost_ns=50000
vllm serve /models \
--safetensors-load-strategy 'prefetch' \
--max-model-len 135168 \
--max-num-batched-tokens 4096 \
--served-model-name ds \
--gpu-memory-utilization 0.92 \
--max-num-seqs 16 \
--data-parallel-size 1 \
--tensor-parallel-size 8 \
--enable-expert-parallel \
--quantization ascend \
--port 7000 \
--block-size 128 \
--enable-chunked-prefill \
--enable-prefix-caching \
--tokenizer-mode deepseek_v4 \
--tool-call-parser deepseek_v4 \
--enable-auto-tool-choice \
--reasoning-parser deepseek_v4 \
--async-scheduling \
--additional-config '{"enable_cpu_binding":true,"multistream_overlap_shared_expert":false}' \
--compilation-config '{"cudagraph_mode":"FULL_DECODE_ONLY","cudagraph_capture_sizes":[2,4,6,8,10,12,14,16,18,20,22,24,32,36,40]}' \
--model-loader-extra-config '{"enable_multithread_load":true,"num_threads":16}' \
--speculative-config '{"num_speculative_tokens": 1,"method": "mtp"}'
curl http://localhost:7001/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "ds",
"messages": [
{"role": "user", "content": "请用数字1到10回答我,每个数字一行"}
],
"max_tokens": 100
}'
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-06,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号