WhisperLiveKit:本地同步实时语音转文字

WhisperLiveKit:本地同步实时语音转文字

用户11563501
发布于 2026-06-23 10:41:54
发布于 2026-06-23 10:41:54
实时语音转文字一直是个难题。现有方案要么依赖云服务(数据安全问题),要么直接用 Whisper 处理音频片段,(但其并非为完整语句设计,处理时会丢失上下文,经常切断单词,效果很差)。
最近发现不错的本地实时语音转文字的项目WhisperLiveKit,它使用了最前沿的同步语音技术,支持智能缓冲和增量处理,从根本上解决问题。
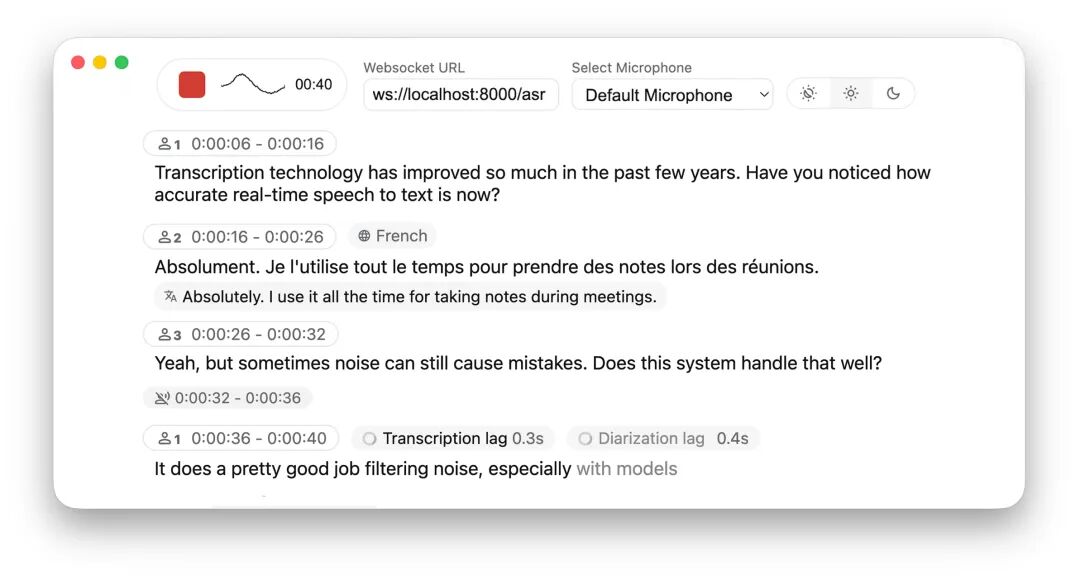
比如:Simul-Whisper 和 SimulStreaming ,专门解决实时转录的低延迟问题。NLLB 翻译模型能处理 200 种语言的同步翻译。Streaming Sortformer 负责实时说话人识别。
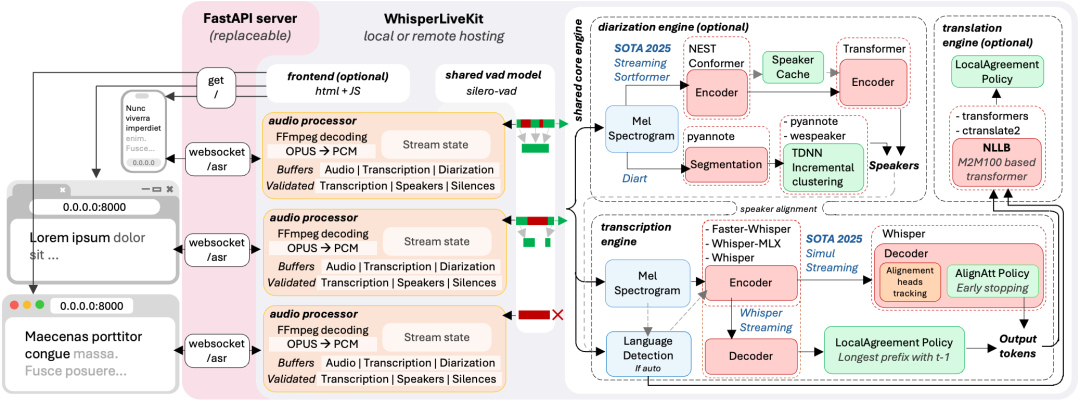
架构图
同时,架构设计考虑了并发。后端支持多用户同时使用,通过语音活动检测在没人说话时降低资源消耗。
安装和使用
安装:
pip install whisperlivekit启动服务器:
whisperlivekit-server --model base --language en打开浏览器访问 http://localhost:8000 就能用。
支持不同大小的模型(tiny 到 large-v3),可以选择语言或自动检测。需要说话人识别就加 --diarization 参数。需要翻译就用 --target-language:
whisperlivekit-server --model large-v3 --language fr --target-language da部署方式
Docker 部署支持 GPU 加速:
docker build -t wlk .
docker run --gpus all -p 8000:8000 --name wlk wlk生产环境可以用 Gunicorn + Uvicorn 多进程部署,配合 Nginx 做反向代理。
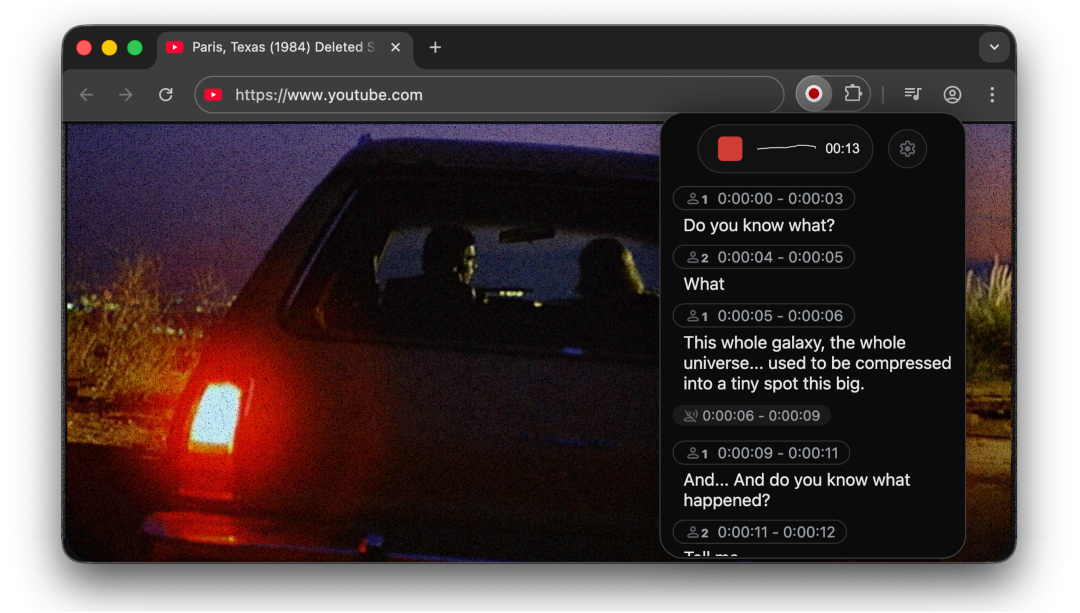
Chrome 扩展演示
还提供了 Chrome 扩展,能直接抓取网页音频转文字。看视频会议或在线课程时可以实时生成字幕。
性能和限制
项目支持 Apple Silicon 优化,以及各种可调参数。--frame-threshold 控制速度和准确性的平衡,--preload-model-count 可以预加载多个模型实例来处理并发。
但效果很依赖语言和模型选择。不同语言的表现差异较大,小语种效果可能不理想。实时转录本身就有技术限制,加上不同口音、背景噪音等因素,准确率会受影响。
小结
这个项目对于一些自部署优先的AI应用非常合适,敏感信息不用担心泄漏,并且开源免费。感兴趣的朋友可以试一试。
地址:https://github.com/QuentinFuxa/WhisperLiveKit
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-11-10,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号