SGLang发布迷你版:5千行代码实现LLM推理核心

SGLang发布迷你版:5千行代码实现LLM推理核心

用户11563501
发布于 2026-06-23 11:04:40
发布于 2026-06-23 11:04:40

SGLang架构图
SGLang团队刚刚发布了mini-SGLang,将原本30万行的代码库压缩到仅5000行。这个版本保留了所有核心优化技术,包括重叠调度、FlashAttention-3、基数缓存等,性能在在线服务场景下与完整版几乎相同。
为什么需要迷你版
许多开发者希望了解现代大语言模型推理的内部工作原理,但直接阅读30万行的生产代码几乎不可能。mini-SGLang就是为了解决这个问题而生,包含了所有核心优化,代码量足够小,可以在一个周末内读完。
核心功能完整保留
- 重叠调度技术
- FlashAttention-3和FlashInfer内核
- 基数缓存和分块预填充
- 张量并行
- JIT CUDA内核
- OpenAI兼容API
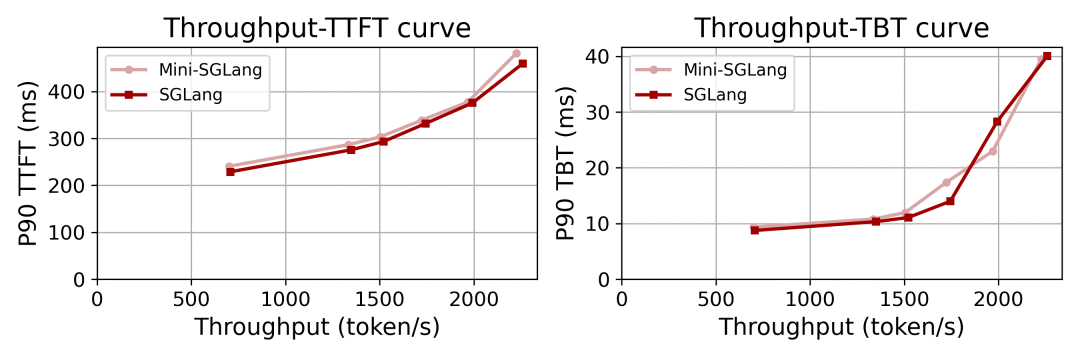
性能对比图
在Qwen3-32B模型、4张H200显卡的实际工作负载测试中,mini-SGLang展现了与完整版相近的性能表现。
定位明确:学习与实验
有网友询问mini-SGLang是否支持GGUF格式服务,开发团队明确表示,这个版本主要是为了教学和实验目的,不建议用于生产环境或需要完整后端扩展的场景。对于GGUF等生产级需求,建议使用完整的SGLang。
另一个关注点是低比特量化支持。目前mini-SGLang主要专注于展示核心推理优化,对于8比特以下的量化格式支持尚未明确。
技术细节
mini-SGLang是目前唯一支持在线/离线服务、流式传输和重叠调度的最小化推理项目。有开发者指出,这种设计甚至为将来将核心从Python迁移到其他语言提供了实验基础。
对于需要最新CUDA内核(如sm_120/Blackwell架构)和高性能NVFP4、FP8等格式支持的开发者,mini-SGLang可能还需要等待后续更新。
相关链接:
- GitHub仓库:https://github.com/sgl-project/mini-sglang
- 完整性能测试报告:https://lmsys.org/blog/2025-12-17-minisgl/
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-20,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号