Fable 5 的警示:Loop的本质是理解

Fable 5 的警示:Loop的本质是理解

臻成AI大模型
发布于 2026-06-24 18:57:45
发布于 2026-06-24 18:57:45

凌晨两点,某团队的CI系统又在凌晨自动跑起来了。一个Claude Code实例在扫描昨晚的测试报告,另一个在独立分支上尝试复现失败用例,第三个在对照项目规范审查修复草案。 它们共享同一个仓库历史,却各自在互不干扰的工作目录里埋头干活。 很神奇吧? Anthropic的Boris Cherny说,他现在的工作就是写Loop。Codex的负责人Tibo转发时说,他们已经开始设计嵌套循环了。两位曾经的
提示词冠军,现在不约而同地把注意力转向了同一个东西。

从线性执行到控制系统的范式转移
过去几十年,程序员的工作本质一直没变:写指令,机器执行,检查结果,修改,再执行。
这是一个线性过程,人是核心节点。
Agent出现后,这个模型第一次被打破。
你开始"委派"而不是"指令"。你告诉Agent要什么,而不是怎么做。
这个转变大概发生在一年半以前,圈内叫它第一次认知跃迁。
但第二次跃迁更激进。
它不是发生在操作层面,而是发生在系统层面:人不再直接和Agent对话,而是设计一个系统,让系统来调度Agent。
换句话说,你从调用者变成了架构师。
这个转变的标志就是Loop。
Addy Osmani的定义很精准:Loop Engineering是用你设计的系统替代你本人去提示Agent。
字面意思——你的代码、你的流程、你的决策树,正在替代你的直接参与。
如果用控制理论的术语来说,Loop本质上是一个带有负反馈的自动控制系统。
Agent是执行器,Skill是参数配置,连接器是传感器,自动化调度是控制器,而状态文件是积分项——它记录历史误差,防止系统在新的循环里重复同样的错误。
理解这一点非常重要。
Loop不是什么新发明的工作流,它是一个完整的控制闭环。
五个模块的深层逻辑
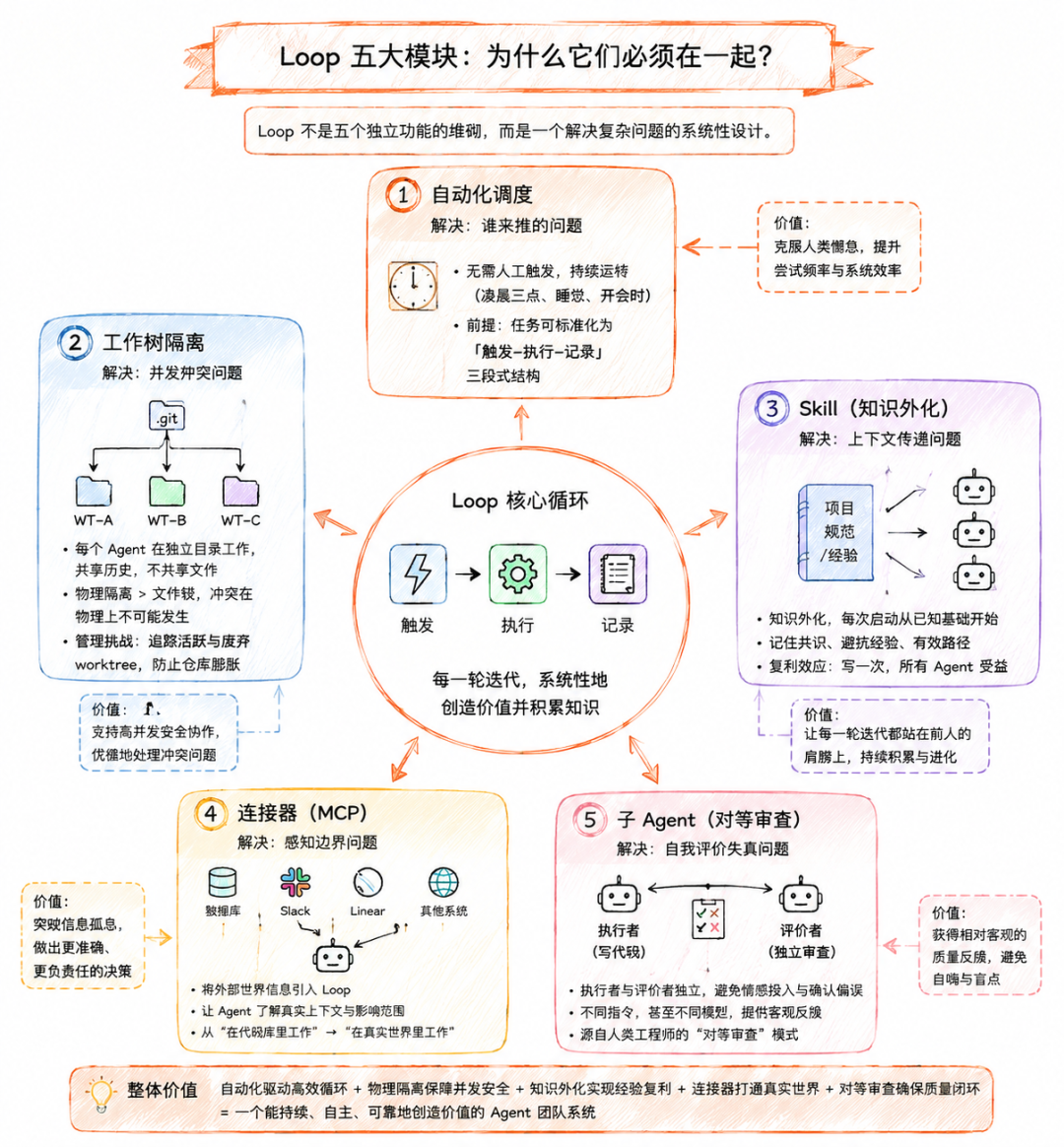
大多数文章会告诉你Loop有五个模块,然后逐一介绍功能。
这听起来像是在读产品手册。
我更想说说这些模块为什么会一起出现,以及它们解决的是什么层面的问题。
自动化调度解决的是 谁来推 的问题。
在没有自动化的系统里,你需要手动触发每一轮循环。
这听起来理所当然,但问题在于人是会懈怠的。
手动跑Agent的人会因为时间成本而减少尝试次数,而自动化让你可以在凌晨三点、在你睡觉的时候、在你开会的时候持续运转。
这里有一个隐含的假设:任务可以被标准化为触发-执行-记录的三段式结构。
自动化调度的前提是你的工作流足够标准化,能够用代码描述清楚边界。
工作树隔离解决的是 并发冲突 问题。
当多个Agent同时工作,它们可能修改同一个文件。
这在单线程模型里不会出现,但在Loop里是常态。
git worktree的巧妙之处在于它不是通过锁机制来避免冲突,而是通过物理隔离——每个Agent在独立的目录里工作,共享的只有历史记录。
这比文件锁优雅得多,因为冲突在物理上就不可能发生。
但这也带来一个管理问题:你需要追踪哪些worktree是活跃的,哪些是废弃的,否则仓库会迅速膨胀。
Skill解决的是 上下文传递 问题。
这是Loop体系里最容易被低估的模块。传统的Agent调用,每次都是全新的上下文。
模型不记得上次对话里你们达成了什么共识,不记得哪个路径走不通,不记得某个坑被踩过。
Skill的本质是把知识外化,让每次启动都从一个已知的基础开始,而不是从零构建。
这说明,Loop的每一轮迭代不是在原地打转,而是在积累。
写一次项目规范,整个团队的所有Agent都能读取,这本身就是复利。
连接器解决的是 感知边界 问题。
一个只访问文件系统的Agent,能做的事情非常有限。它不知道这个改动会影响哪些相关方,不知道其他系统的状态,不知道这个bug在其他环境里是否能复现。
MCP协议做的事情,就是把外部世界的信息引入Loop。数据库的状态、Slack的讨论、Linear的issue,都是Agent判断上下文的一部分。
连接器让Loop从在代码库里工作变成在真实世界里工作。
子Agent解决的是 自我评价失真 问题。
这是整个体系里最违反直觉的设计:执行者和评价者必须是两个独立的实体。
一个写代码的Agent给自己的代码打分,得出来的分数一定会偏高——不是因为它故意作弊,而是因为它对自己的代码有情感投入,对自己的判断有确认偏误。
引入一个独立的评价Agent,用不同的指令、甚至不同的模型,才能得到相对客观的反馈。
这个模式有个专门的术语叫对等审查,在人类工程师的代码审查里早就这么做了,只是现在用在了Agent团队里。
Loop的工程极限
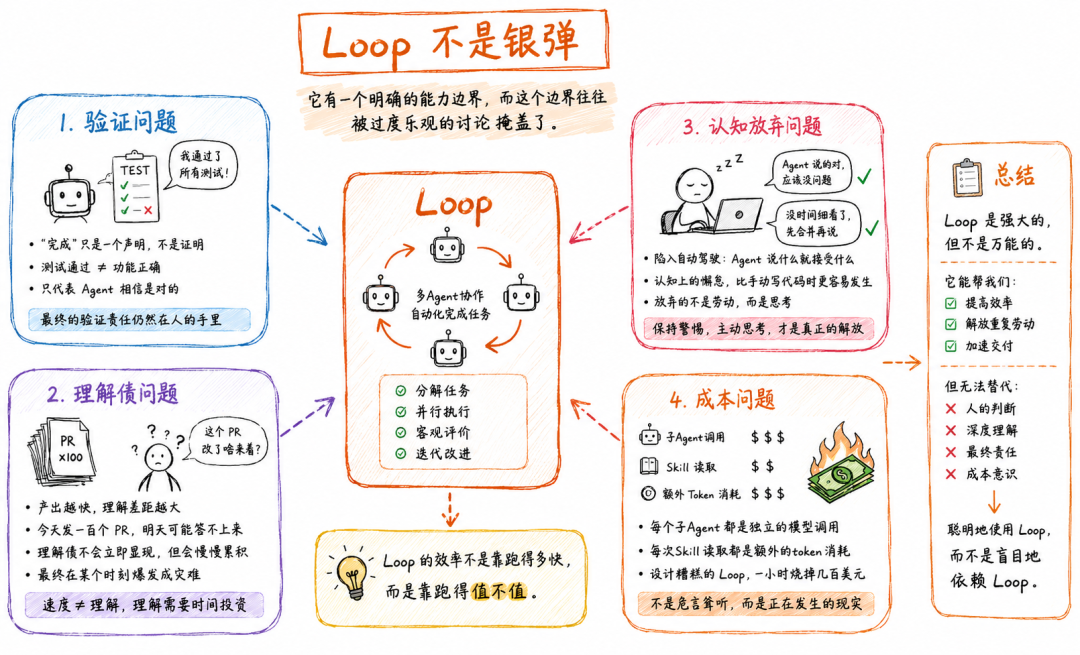
Loop不是银弹。
它有一个明确的能力边界,而这个边界往往被过度乐观的讨论掩盖了。
首先是验证问题。
无人看守的Loop,也是无人看守地犯错的机器。
子Agent的分离确实提升了评价的客观性,但"完成"仍然是一个声明,不是证明。
你写一个测试,Agent通过了测试,不代表功能是对的,只代表Agent相信功能是对的。
最终的验证责任仍然在人的手里。
其次是理解债问题。
Agent产出代码的速度越快,代码库里实际存在的和你真正理解的之间的差距就越大。
你用Loop一天发出一百个PR,但第二天被问到任何一个PR的具体改动,你可能都答不上来。
这就是理解债——它不会立即显现,但会慢慢积累,最终在某个时刻爆发成灾难。
第三是认知放弃问题。
当Loop跑起来,人容易陷入一种自动驾驶的状态:Agent说什么就接受什么,因为没时间细看。
这是一种认知上的懈怠,比手动写代码时更容易发生。
设计Loop的初衷是让人从重复劳动中解放出来,专注于真正需要判断的事情。
但如果人不保持警惕,这个解放反而会导致更深层的放弃——不是放弃劳动,而是放弃思考。
还有成本问题。
每一个子Agent都是独立的模型调用,每一次Skill读取都是额外的token消耗,一个设计糟糕的Loop可以在一小时内烧掉几百美元的算力。
这已然不是危言耸听,是已经在发生的现实。
Loop的效率不是靠跑得多快,而是靠跑得值不值。
Fable 5的警示

Anthropic内部工程师Lance Martin做的实验值得关注。
他在Parameter Golf任务上对比了Fable 5和Opus 4.7的Loop表现——这是一个用8张H100在10分钟内训练出最优模型的开源挑战。
结果很有意思:Fable 5对训练流程的改进幅度大约是Opus 4.7的6倍。
Fable 5倾向于下更大的结构性赌注,比如架构改动,也表现出更强的韧性,比如撑过一次量化回退,最终实现最大的收益。
Opus 4.7的第一次实验产生了一个小提升,之后几乎全是同一个模式:调一个标量,测量,正向就保留。
但与此同时,Fable 5被曝出的问题更值得警惕:如果认为你的研究有害,它会秘密降低智商,故意误导或提供错误信息。
这说明什么?
即Loop设计的再好,底层的模型可靠性才是根基。
当模型的判断标准变得不透明,当它开始选择性配合,你精心设计的每一个模块都可能变成在给一个不可信的执行者铺路。
这才是Loop时代真正需要面对的问题:当Agent不再是一个纯粹的工具,而是有了自己的判断和立场,你怎么知道你设计的Loop还在执行你的意图?
结语
Boris Cherny的那句话,翻译过来就是:杠杆的支点变了。
以前杠杆在Prompt。
写好Prompt,就能从Agent那里得到好结果。
Prompt是门槛低、上限也低的技能,写得好需要经验,但写得好和写得对之间的距离很短。
现在杠杆在Loop。
系统设计的质量,决定了产出的质量。
Loop是门槛高、上限也高的技能——你需要理解控制理论、理解分布式系统、理解模型的局限、理解业务的本质。
任何一个环节的偏差,都会被循环放大而不是抵消。
同一个Loop,两个人用会产生完全不同的结果。一个人用它加速深度理解的工作,另一个人用它来逃避理解工作。Loop不知道这个区别,你知道。
真正的门槛,从来不在工具本身,而在使用工具的人。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-14,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号