这是我看到 AI memory 最优质的 Github

这是我看到 AI memory 最优质的 Github

cxuanAI
发布于 2026-06-24 21:21:03
发布于 2026-06-24 21:21:03
这次看到的是这个项目:
EverMind-AI/EverOS
EverOS GitHub 项目预览
EverOS 的定位很明确。
它想做的是 Agent 和应用之间共用的一层长期记忆。
不是只给一次聊天保存历史。
而是把对话、文件、Agent 轨迹这些东西,整理成可以长期保存、检索、复用的本地记忆。
仓库目前大约 7.7k stars、740 forks,Apache-2.0 协议,主语言是 Python。
README 里写得很直接:它是 self-evolving memory across agents and platforms。
1. 它到底是什么
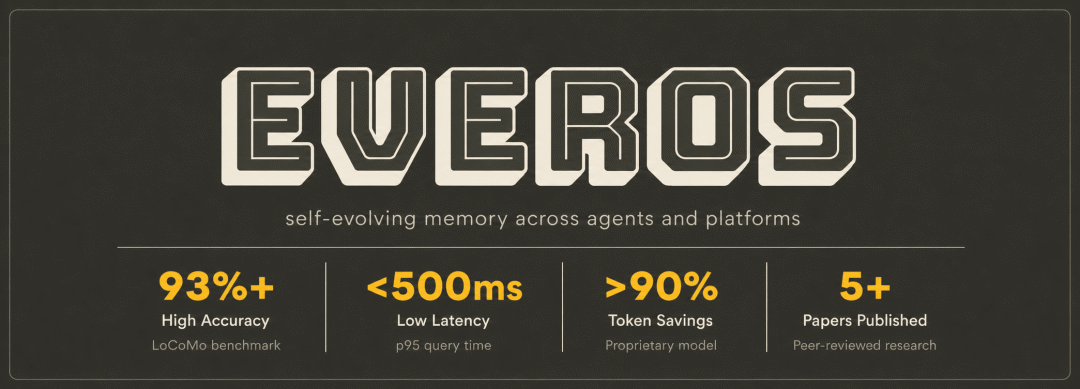
EverOS 项目横幅
EverOS 是一个本地优先的记忆运行时。
它面向的是 AI Agent、AI 应用,以及想把记忆能力接进自己工作流的开发者。
它会把记忆保存成 Markdown。
这些 Markdown 是 source of truth。
你可以直接读、直接改、用 grep 找,也可以放进 Git 或 Obsidian。
同时,它还会在本地维护 SQLite 和 LanceDB 索引。
Markdown 负责可读和可改。
SQLite 负责状态和队列。
LanceDB 负责向量、BM25 和过滤检索。
这就是它和很多“只暴露一个记忆 API”的项目不太一样的地方。
底层记忆不是黑盒。
2. 它解决什么麻烦

EverOS 项目标识
现在用 AI Agent,很容易遇到一个问题:
Agent 看起来很聪明,但换一个会话、换一个工具、换一个客户端,前面那些经验就断了。
你在 Claude Code 里交代过项目习惯。
到 Codex 里可能还要再说一遍。
你在某个应用里沉淀了偏好。
另一个 Agent 不一定知道。
EverOS 想把这部分抽出来。
记忆不要只跟着某一个聊天窗口走。
它应该能按 user、agent、app、project、session 这些维度组织起来。
需要的时候,再被不同 Agent 检索回来。
README 里还专门把用户记忆和 Agent 记忆拆开。
用户侧有 episodes、profile、facts。
Agent 侧有 cases 和 skills。
这个拆分很实际。
人的偏好、项目背景、Agent 做过的任务,不应该全部混在一坨聊天历史里。
3. 核心看点

AI 编程助手接入 EverOS
第一个看点,是 Markdown 不是导出格式,而是主存储。
EverOS 文档里说,SQLite 和 LanceDB 都是从 Markdown 派生出来的索引。
索引坏了可以重建。
原始记忆还在文件里。
第二个看点,是它的本地三件套比较轻。
README 里明确写了,不需要 MongoDB、Elasticsearch 或 Redis。
对个人开发者和本地 Agent 来说,这会少很多部署负担。
第三个看点,是它不只存聊天。
它支持 conversations、agent trajectories、file knowledge,也提到图片、音频、PDF、HTML、邮件等多模态摄取。
第四个看点,是检索作用域细。
它可以按 user_id、agent_id、app_id、project_id、session_id 这些维度切开。
这对 Agent 记忆很重要。
同一个人、不同项目、不同应用,记忆边界不清楚,很容易召回出错。
4. 为什么值得看

EverOS 记忆图谱示例
我觉得 EverOS 值得看,是因为它把“记忆”做得比较具体。
不是一句让 Agent 记住我。
而是把记忆落到文件结构、索引同步、检索作用域、用户轨和 Agent 轨这些细节上。
存储布局文档里能看到,它默认会在 ~/.everos/ 下建记忆根目录。
里面按 app、project、users、agents 分开。
用户 profile 是 user.md。
日常片段放在 episodes。
Agent 做过的任务放在 .cases。
可复用流程放在 skills。
这套结构不是只给机器看的。
人也能打开看。
这点对长期记忆很关键。
因为记忆一定会有错。
如果用户不能审计、不能改、不能删除,那它越长期,风险越大。
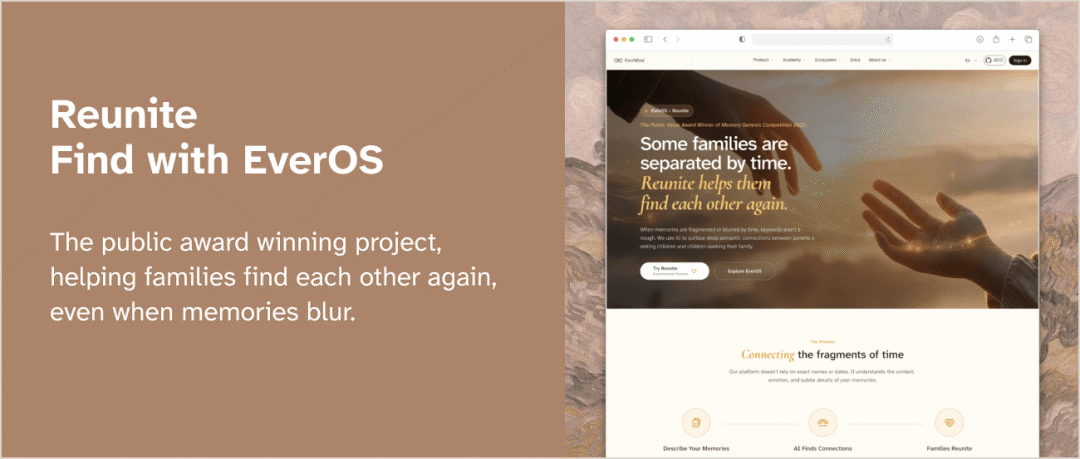
Reunite 使用场景
README 里的 use cases 也能看出它想覆盖的范围。
有 AI coding assistants。
有 browser agent。
有记忆图谱。
也有 Reunite 这种用语义记忆找回线索的应用。
这些例子不一定都要你照着做。
但它说明 EverOS 不是只想做一个 SDK。
它更像一层可以被不同 Agent 和应用共享的记忆底座。
5. 怎么用起来
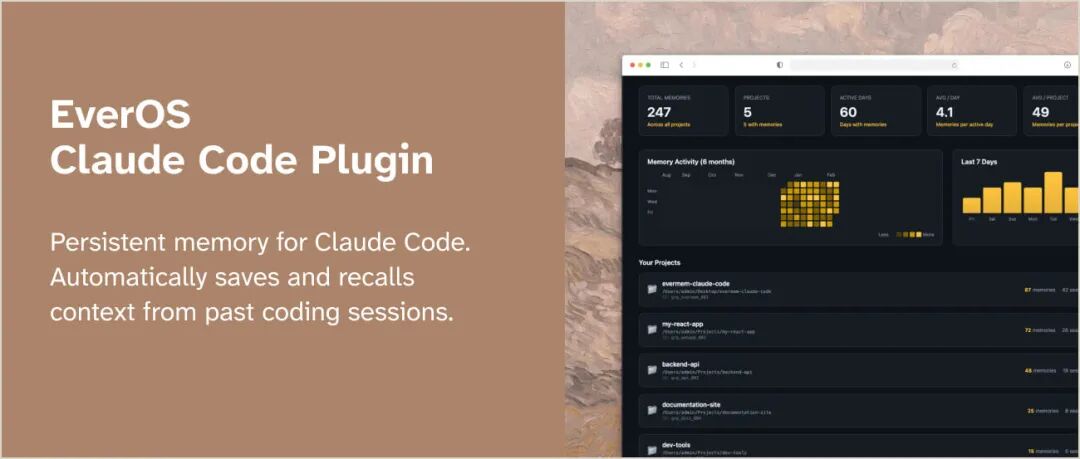
Claude Code 记忆插件示例
如果只是试一遍,README 给的路线很短。
先装包:
uv pip install everos
# or
pip install everos
然后生成配置:
everos init
默认 provider 需要配置 OpenRouter 和 DeepInfra。
README 里也写了可以切到 OpenAI-compatible providers。
中文 README 还给了阿里云百炼和 DashScope 的配置示例。
服务启动:
everos server start
再用健康检查确认:
curl http://127.0.0.1:8000/health
写入记忆和搜索记忆走 HTTP API。
README 里给了完整例子:先调用 /api/v1/memory/add 写一段 conversation,再调用 /api/v1/memory/flush 触发提取,最后用 /api/v1/memory/search 查回来。
第一次试的时候,可以先用很小的 demo。
比如写一句“我每年春天喜欢去 Yosemite 攀岩”,再问它喜欢去哪里攀岩。
能搜回来,就说明写入、提取、索引和检索这条链路通了。
6. 适合谁,以及先注意什么

Hive Orchestrator 使用场景
EverOS 适合三类人先看。
第一类,是正在做 AI Agent 的开发者。
尤其是你已经发现 session 记忆不够用,想让 Agent 跨任务复用经验。
第二类,是想把 AI 编程助手接进团队流程的人。
cases、skills、project scope 这些概念,和真实项目里的重复任务很贴近。
第三类,是重视本地数据和可审计存储的人。
Markdown 作为主存储,比只存在远端数据库里更容易理解和控制。
需要注意的是,它不是一个免配置的聊天产品。
你要配模型、embedding、rerank。
要跑本地服务。
如果要用多模态,还要装对应 extra。
Office 文档解析还依赖 LibreOffice。
还有一点。
长期记忆不是越多越好。
你需要认真看它怎么隔离 user、agent、app、project。
也要想清楚哪些内容可以进入记忆,哪些内容不该保存。
EverOS 把底层文件露出来,是优点。
但也意味着你要把记忆目录当成真实数据来管理。
今天就先聊到这里。我们下期再见!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-18,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号