极简 MLP 字符级语言模型 —— 训练、推理与部署
原创
极简 MLP 字符级语言模型 —— 训练、推理与部署
原创
他们说下雨了
发布于 2026-06-25 17:48:31
发布于 2026-06-25 17:48:31
一个 从零开始训练 的极简多层感知机(MLP)字符级语言模型,并附带了 OpenAI 兼容的 HTTP 接口,用于演示深度学习的基本流程。代码使用纯 NumPy 实现前向与反向传播,纯学习用。
1. 训练策略
- 大模型通常只训练一次(预训练),之后微调,以保留通用能力,防止灾难性遗忘。
- 本示例为 小样本教学演示,采用多轮迭代(多个 epoch)使模型充分收敛,展示完整的梯度下降过程。
2. 字符编码与向量化
- 使用 字符级分词:每个字符作为一个独立的 token。
- 编码方式:one-hot 编码,输入维度为
seq_len * vocab_size,直观但稀疏。 - 实际大模型通常采用 子词分词(BPE/WordPiece) 和 嵌入层(Embedding),以降低维度并捕捉语义。
3. Web 框架选型
- 使用 Flask 实现简易的 OpenAI 兼容接口,依赖少,适合快速演示。
- 若需生产级特性(如自动文档、异步支持),可替换为 FastAPI。
4. 执行效果
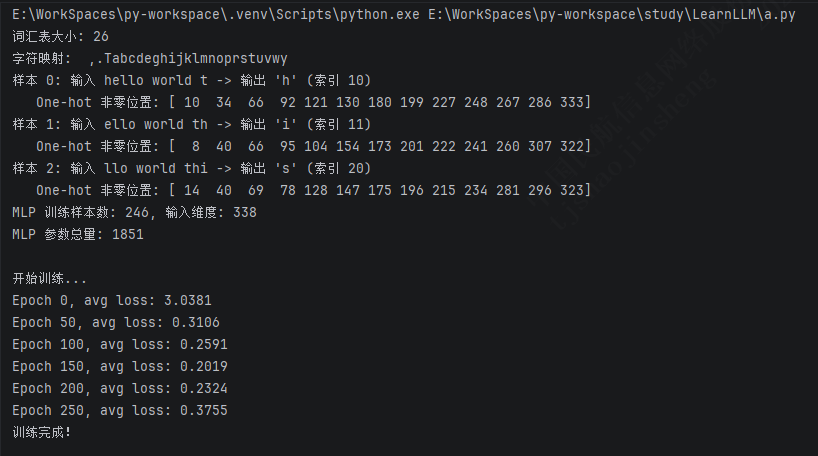
python代码如下:
import numpy as np
import matplotlib.pyplot as plt # 绘图库
from flask import Flask, request, jsonify
# ------------------------------
# 极简 MLP 模型
# ------------------------------
class TinyMLP:
def __init__(self, input_size, hidden_size, output_size):
self.input_size = input_size
self.hidden_size = hidden_size
self.output_size = output_size
# Xavier 均匀初始化
limit1 = np.sqrt(6.0 / (input_size + hidden_size))
self.W1 = np.random.uniform(-limit1, limit1, (input_size, hidden_size))
self.b1 = np.zeros(hidden_size)
limit2 = np.sqrt(6.0 / (hidden_size + output_size))
self.W2 = np.random.uniform(-limit2, limit2, (hidden_size, output_size))
self.b2 = np.zeros(output_size)
total_params = (input_size * hidden_size) + hidden_size + (hidden_size * output_size) + output_size
print(f"MLP 参数总量: {total_params}")
# 说明:前向传播 —— 本模型为两层全连接网络(输入→隐藏→输出)
# 隐藏层使用 tanh 激活函数,输出层为线性(logits)。
# 因此,这是一个“浅层”MLP(1个隐藏层),用于演示基本的反向传播。
def forward(self, x):
h = np.tanh(x @ self.W1 + self.b1) # 隐藏层:线性变换 + tanh 激活
logits = h @ self.W2 + self.b2 # 输出层:线性变换(无激活,后续 softmax)
return logits, h
# 说明:计算交叉熵损失及所有参数的梯度(通过链式法则)
# - 先通过 forward 获得 logits 和隐藏层输出 h
# - 计算 softmax 概率,并得到损失
# - 反向传播:从输出层梯度 dlogits 开始,依次计算 dW2、db2,
# 再回传至隐藏层 dh,经过 tanh 导数 (1 - h^2),最后计算 dW1、db1。
# 所有梯度均为解析梯度,适用于批量样本(batch 维度处理)。
def compute_loss_and_grad(self, x, y_true):
batch = x.shape[0]
logits, h = self.forward(x)
# softmax 数值稳定版本
exp_logits = np.exp(logits - np.max(logits, axis=1, keepdims=True))
probs = exp_logits / np.sum(exp_logits, axis=1, keepdims=True)
loss = -np.mean(np.log(probs[np.arange(batch), y_true] + 1e-8))
# 输出层梯度(softmax 交叉熵的梯度简化形式)
dlogits = probs.copy()
dlogits[np.arange(batch), y_true] -= 1.0
dlogits /= batch
# 输出层权重和偏置的梯度
dW2 = h.T @ dlogits
db2 = np.sum(dlogits, axis=0)
# 回传至隐藏层
dh = dlogits @ self.W2.T
dh = dh * (1 - h**2) # tanh 的导数
# 隐藏层权重和偏置的梯度
dW1 = x.T @ dh
db1 = np.sum(dh, axis=0)
return loss, dW1, db1, dW2, db2
# 说明:使用梯度下降(SGD)更新参数,lr 为学习率。
# 每次更新都采用负梯度方向,使损失下降。
def update(self, dW1, db1, dW2, db2, lr=0.1):
self.W1 -= lr * dW1
self.b1 -= lr * db1
self.W2 -= lr * dW2
self.b2 -= lr * db2
# ------------------------------
# 1. 准备字符级数据集
# ------------------------------
text = (
"hello world this is a tiny language model. "
"The problem seemed impossible, but we solved it together. "
"we love training small models on cpu. "
"you can chat with me. tell me a joke. "
"once upon a time there was a little ai. "
"it learned to talk and it was very happy. "
)
# 构建字符映射
# 将文本中所有不重复的字符提取出来并排序,形成词汇表
# 例如,假设 text = "hello world",则 chars 可能为 [' ', 'd', 'e', 'h', 'l', 'o', 'r', 'w'](排序后)
# 每个字符被赋予一个唯一的整数索引,例如 'h' -> 0, 'e' -> 1, 'l' -> 2, ...
chars = sorted(list(set(text)))
vocab_size = len(chars) # 词汇表大小,即所有可能字符的个数
char2idx = {ch: i for i, ch in enumerate(chars)} # 字符到索引的映射字典
idx2char = {i: ch for i, ch in enumerate(chars)} # 索引到字符的映射字典(反向映射)
# 可以打印前几个映射查看(但未启用,避免干扰输出)
# print("字符映射示例:", {ch: idx for idx, ch in enumerate(list(char2idx.items())[:5])})
print(f"词汇表大小: {vocab_size}")
print(f"字符映射: {''.join(chars)}")
# ------------------------------
# 构造 MLP 训练样本(字符级分词 + one-hot 编码)
# ------------------------------
seq_len_mlp = 13 # 上下文窗口大小(即输入序列长度),相当于每次使用前 13 个字符预测下一个字符
x_mlp, y_mlp = [], [] # x_mlp 存储输入向量,y_mlp 存储目标字符索引
# 遍历整个文本,生成训练样本
for i in range(len(text) - seq_len_mlp):
# 取长度为 seq_len_mlp 的字符序列作为输入
seq = text[i:i + seq_len_mlp]
# 创建 one-hot 向量:维度 = 序列长度 × 词汇表大小
# 每个位置用 vocab_size 维的 one-hot 表示该位置的字符
one_hot = np.zeros(seq_len_mlp * vocab_size)
# 对输入序列中的每个字符进行 one-hot 编码
for pos, ch in enumerate(seq):
idx = char2idx[ch] # 将字符映射为索引
one_hot[pos * vocab_size + idx] = 1.0 # 在对应位置置 1(独热)
# 目标输出为下一个字符的索引
target_idx = char2idx[text[i + seq_len_mlp]]
x_mlp.append(one_hot)
y_mlp.append(target_idx)
# 打印前 3 个样本作为示例
if i < 3:
print(f"样本 {i}: 输入 {seq} -> 输出 '{text[i + seq_len_mlp]}' (索引 {y_mlp[-1]})")
nonzero = np.nonzero(one_hot)[0]
print(f" One-hot 非零位置: {nonzero}")
# 说明:文本向量化采用 one‑hot 编码,其优点在于直观、易于实现,
# 但现实中的大模型通常使用词嵌入(如 Word2Vec、BERT 的 token embedding)或
# 子词分词(BPE)等更高效、语义更丰富的方式。
x_mlp = np.array(x_mlp)
y_mlp = np.array(y_mlp)
print(f"MLP 训练样本数: {len(x_mlp)}, 输入维度: {x_mlp.shape[1]}")
# 创建模型
input_dim = seq_len_mlp * vocab_size
model = TinyMLP(input_size=input_dim, hidden_size=5, output_size=vocab_size)
# ------------------------------
# 2. 训练并记录损失
# ------------------------------
print("\n开始训练...")
epochs = 300 # 训练轮次
lr = 0.2 # 学习率
loss_history = []
# 说明:对于大规模预训练模型,通常只进行一次完整训练(即预训练),
# 之后仅进行微调,目的是保留通用能力,防止灾难性遗忘。
# 但本例为小样本教学演示,采用多次迭代(多个 epoch)使模型充分收敛,
# 以展示从零开始的训练过程。
for epoch in range(epochs):
perm = np.random.permutation(len(x_mlp))
total_loss = 0.0
for i in perm:
x_sample = x_mlp[i:i+1]
y_sample = y_mlp[i:i+1]
loss, dW1, db1, dW2, db2 = model.compute_loss_and_grad(x_sample, y_sample)
model.update(dW1, db1, dW2, db2, lr=lr)
total_loss += loss
avg_loss = total_loss / len(x_mlp)
loss_history.append(avg_loss)
if epoch % 50 == 0:
print(f"Epoch {epoch}, avg loss: {avg_loss:.4f}")
print("训练完成!")
# ------------------------------
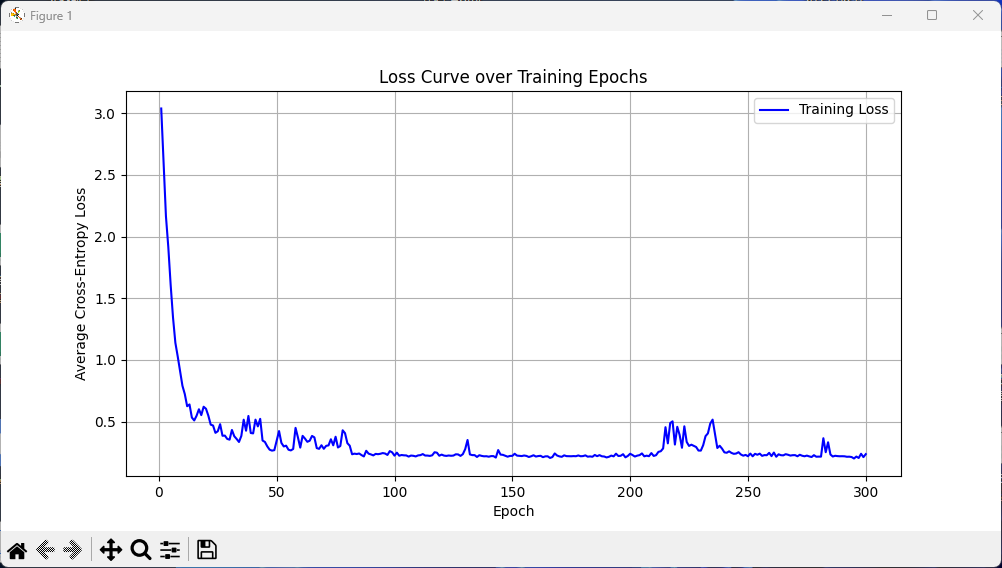
# 3. 绘制损失曲线
# ------------------------------
plt.figure(figsize=(10, 5))
plt.plot(range(1, epochs+1), loss_history, label='Training Loss', color='blue')
plt.xlabel('Epoch')
plt.ylabel('Average Cross-Entropy Loss')
plt.title('Loss Curve over Training Epochs')
plt.grid(True)
plt.legend()
plt.savefig('loss_curve.png', dpi=150)
plt.show()
# ------------------------------
# 4. 保存模型权重及元信息
# ------------------------------
np.savez("tiny_mlp_model.npz",
W1=model.W1, b1=model.b1, W2=model.W2, b2=model.b2,
vocab_size=vocab_size, seq_len=seq_len_mlp,
char2idx=char2idx, idx2char=idx2char)
print("模型已保存为 tiny_mlp_model.npz")
# ------------------------------
# 5. 推理函数与测试
# ------------------------------
def load_model_for_inference(npz_path):
"""
从 .npz 文件加载训练好的模型参数和元数据。
返回一个预测函数,该函数接受提示词和生成参数,返回生成的文本。
"""
# ---------- 模型加载 ----------
# 从 npz 文件中读取所有权重和配置信息
data = np.load(npz_path, allow_pickle=True)
W1 = data['W1'] # 输入层→隐藏层权重
b1 = data['b1'] # 隐藏层偏置
W2 = data['W2'] # 隐藏层→输出层权重
b2 = data['b2'] # 输出层偏置
vocab_size = int(data['vocab_size']) # 词汇表大小
seq_len = int(data['seq_len']) # 上下文长度(训练时固定为13)
char2idx = data['char2idx'].item() # 字符→索引映射字典
idx2char = data['idx2char'].item() # 索引→字符映射字典
# ---------- 预测函数 ----------
def predict(prompt, max_new_tokens=30, temperature=0.7):
"""
根据给定的提示词生成后续文本。
参数:
prompt (str): 输入的起始文本。
max_new_tokens (int): 最多生成的新字符数。
temperature (float): 控制采样随机性(>1 更随机,<1 更确定)。
返回:
str: 生成的完整文本(包含原始 prompt)。
"""
generated = list(prompt) # 将提示词转为字符列表,作为生成上下文
for _ in range(max_new_tokens):
# ---- 1. 准备上下文(取最后 seq_len 个字符,若不足则用首字符填充) ----
context = generated[-seq_len:] if len(generated) >= seq_len else generated
if len(context) < seq_len:
context = [context[0]] * (seq_len - len(context)) + context
# ---- 2. 将上下文编码为 one-hot 向量 ----
# 向量长度 = seq_len * vocab_size,每个位置对应一个字符的 one-hot
x_vec = np.zeros(seq_len * vocab_size)
for pos, ch in enumerate(context):
idx = char2idx.get(ch, 0) # 若字符未知,默认映射为 0(通常为空格)
x_vec[pos * vocab_size + idx] = 1.0
x_input = x_vec.reshape(1, -1) # 形状 (1, seq_len * vocab_size)
# ---- 3. 前向传播:计算隐藏层和输出 logits ----
h = np.tanh(x_input @ W1 + b1) # 隐藏层:线性变换 + tanh 激活
logits = h @ W2 + b2 # 输出层:线性变换(未加 softmax)
# ---- 4. 温度缩放 + softmax 得到概率分布 ----
# 除以温度调整分布的尖锐程度,避免概率全集中在最大 logit 上
probs = np.exp(logits[0] / temperature)
probs /= probs.sum()
# ---- 5. 按概率采样下一个字符 ----
next_char_idx = np.random.choice(vocab_size, p=probs)
next_char = idx2char[next_char_idx]
# ---- 6. 将生成的字符加入上下文 ----
generated.append(next_char)
# ---- 7. 简单停止条件:若生成句号且已生成一定长度,则提前结束 ----
if next_char == '.' and len(generated) > len(prompt) + 5:
break
return ''.join(generated) # 将字符列表拼接为最终字符串
return predict # 返回预测函数,供后续调用
# ---------- 实际测试 ----------
# 加载模型(从保存的 npz 文件恢复权重和元数据)
predict_fn = load_model_for_inference("tiny_mlp_model.npz")
# 指定提示词,并生成最多 20 个新字符
test_prompt = "hello"
generated_text = predict_fn(test_prompt, max_new_tokens=20)
# 输出结果
print(f"\n测试生成: prompt='{test_prompt}' -> {generated_text}")
# ------------------------------
# 6. 启动 HTTP 服务
# ------------------------------
# 说明:此处使用 Flask 框架搭建简易的 OpenAI 兼容接口(/v1/chat/completions)。
# 如希望改用 FastAPI,只需替换装饰器和返回格式,但 Flask 足以满足演示需求。
# 实际生产环境可选用 FastAPI 以获得自动文档和异步支持。
app = Flask(__name__)
@app.route("/v1/chat/completions", methods=["POST"])
def chat_completions():
data = request.get_json()
if not data or "messages" not in data:
return jsonify({"error": "invalid request"}), 400
user_msg = None
for m in reversed(data["messages"]):
if m["role"] == "user":
user_msg = m["content"]
break
if not user_msg:
user_msg = "hello"
generated = predict_fn(user_msg, max_new_tokens=50, temperature=0.8)
response = {
"choices": [{
"message": {"role": "assistant", "content": generated},
"index": 0
}]
}
return jsonify(response)
@app.route("/health", methods=["GET"])
def health():
return "ok"
if __name__ == "__main__":
print("\n启动 HTTP 服务: http://0.0.0.0:8080")
print("API 端点: POST /v1/chat/completions")
# app.run(host="0.0.0.0", port=8080, threaded=True)原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号