Qwen-Image-Flash 揭示蒸馏的真正胜负手不在损失函数

Qwen-Image-Flash 揭示蒸馏的真正胜负手不在损失函数

唐国梁Tommy
发布于 2026-06-25 21:45:48
发布于 2026-06-25 21:45:48
过去两年,几乎所有"图像生成加速"的论文都在卷同一件事:设计更精妙的蒸馏目标函数。轨迹对齐、一致性训练、对抗蒸馏、分布匹配……损失函数越写越复杂,仿佛只要公式足够漂亮,多步教师的能力就能自动灌进少步学生的脑子里。

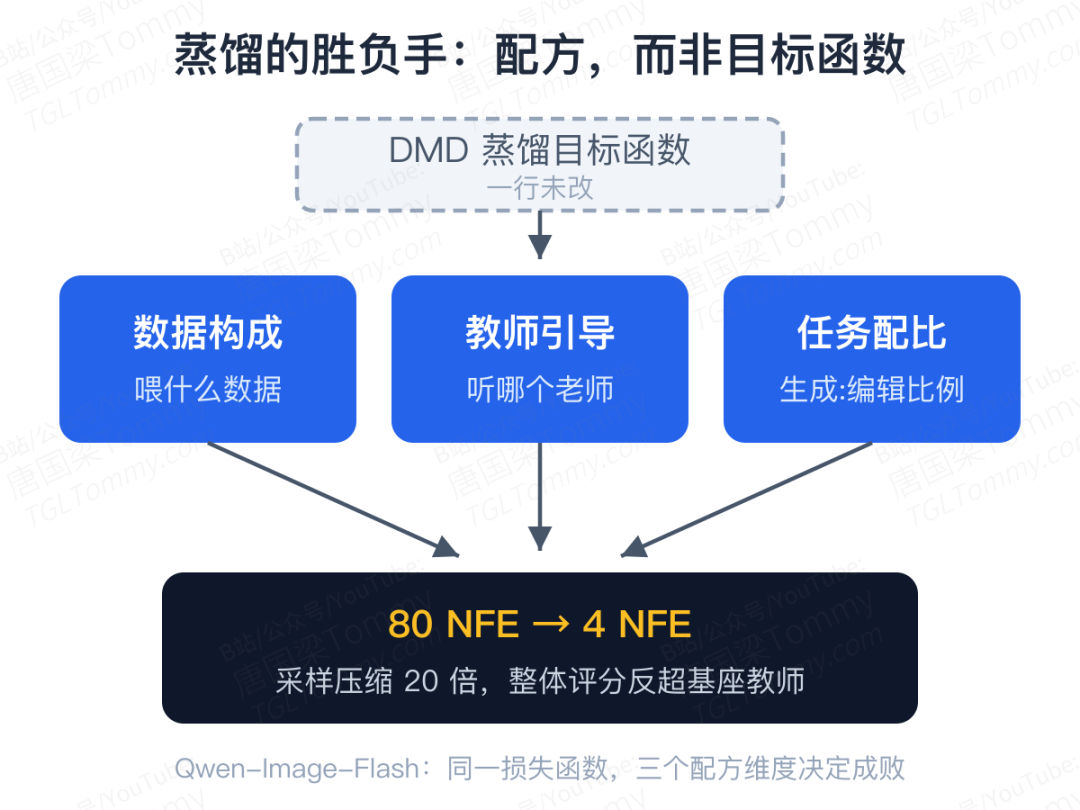
Qwen 团队的新论文 Qwen-Image-Flash 泼了一盆冷水:他们把目前最主流的 DMD(分布匹配蒸馏)目标原封不动地拿来用,一行损失函数都没改,只调整了三个常被当作"工程细节"的训练配方——喂什么数据、听哪个老师、生成与编辑怎么配比——就把 Qwen-Image-2.0 从 80 步压缩到 4 步,整体评分反而超过了 80 步的基座教师。
论文标题里的 "Beyond Objective Design" 就是宣言:蒸馏的胜负手,不在目标函数,而在它周围那一整套训练流程。

蒸馏卡在哪了
先看背景。现代图像生成模型早已不只是"文生图":复杂排版的海报、密集的文字渲染、指令驱动的图像编辑,都要在一个统一模型里完成。但扩散和流匹配模型的老毛病没变——生成一张图要沿着轨迹迭代采样几十步,Qwen-Image-2.0 的标准配置是 80 次函数评估(NFE)。在交互式编辑、端侧部署这些对延迟敏感的场景里,这个成本是硬伤。
少步蒸馏是公认的解法:让一个 4 步的学生模型去模仿 80 步教师的输出分布。可是 Qwen 团队发现,把现成的蒸馏方法直接套到大规模、多场景的生产级模型上,比如文字密集的海报生成,按"常识配方"训出来的学生表现远不及预期。
问题出在哪?他们没有继续改损失函数,而是回头系统性地审了三个训练维度:数据构成、教师引导、任务配比。每一个都审出了反直觉的结论。
反直觉一:想学会写字,别只喂文字图
第一组实验最有戏剧性。团队用 Qwen3 构造了三类蒸馏提示词——风景、人像、文字密集场景,各 2 万条,然后组合出五种训练集:只用风景、只用人像、只用文字、风景加人像、三类全混。所有学生用完全相同的优化协议训练,唯一变量是数据构成。

按直觉,想让学生学会渲染文字,当然该喂文字密集的数据。结果恰恰相反:纯文字数据训出的学生是五组里最差的——连在文字渲染这个"本职项目"上,都输给了从没见过文字数据的风景组和人像组。
更打脸的是"大杂烩"组:三类数据全混、训练集最大,成绩依然比不过单类数据的最优组。把文字数据掺进混合集,反而拖低了文字渲染的得分。
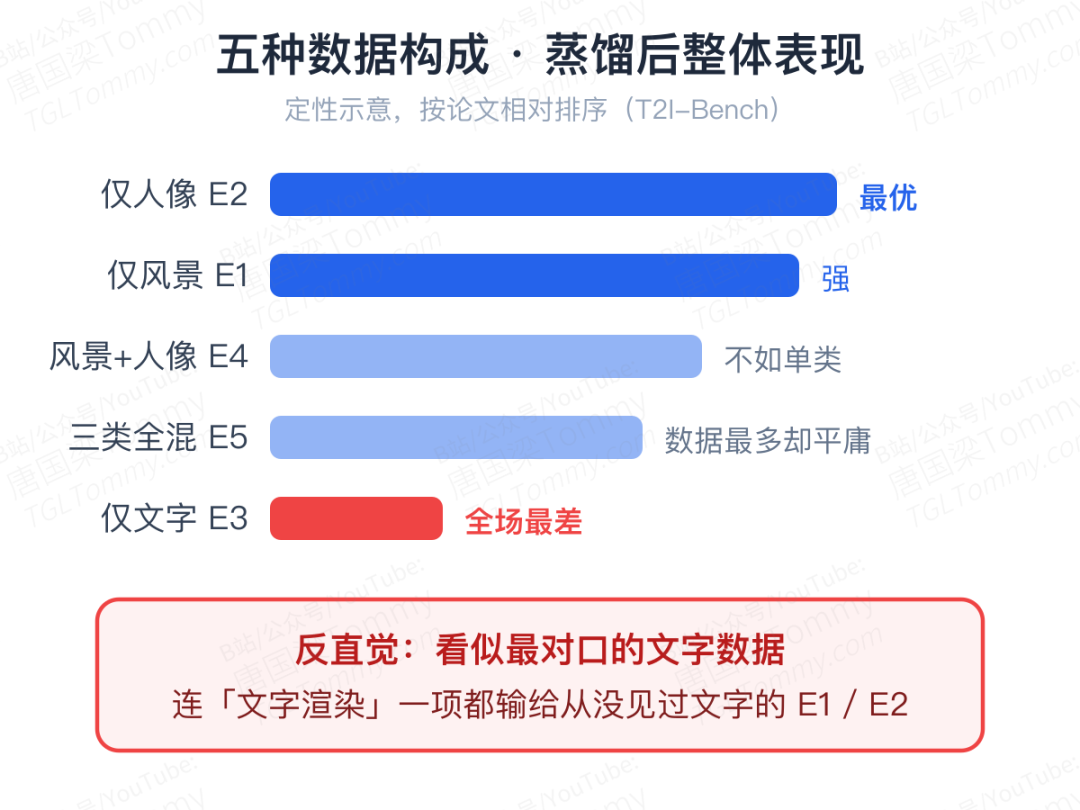
这和预训练的经验完全相反。预训练里"数据越多越杂越好"成立,是因为数据负责覆盖目标分布;而在少步蒸馏里,数据的角色变了——它是教师分布引导暴露给学生的"接口"。学生只有 4 步的轨迹自由度,容量极其有限,一份干净、连贯的单类分布反而是更顺滑的知识传输通道;强行塞进异质数据,传输过程本身就会被搅乱。
一句话总结:蒸馏数据不是覆盖面问题,是信道质量问题。
反直觉二:最强的老师,教不了 4 步的学生
第二个维度是教师选择。Qwen-Image-2.0 有经过任务特化的版本,在文字渲染等下游任务上明显强于基座模型。那直接让特化教师来带学生,岂不是更好?
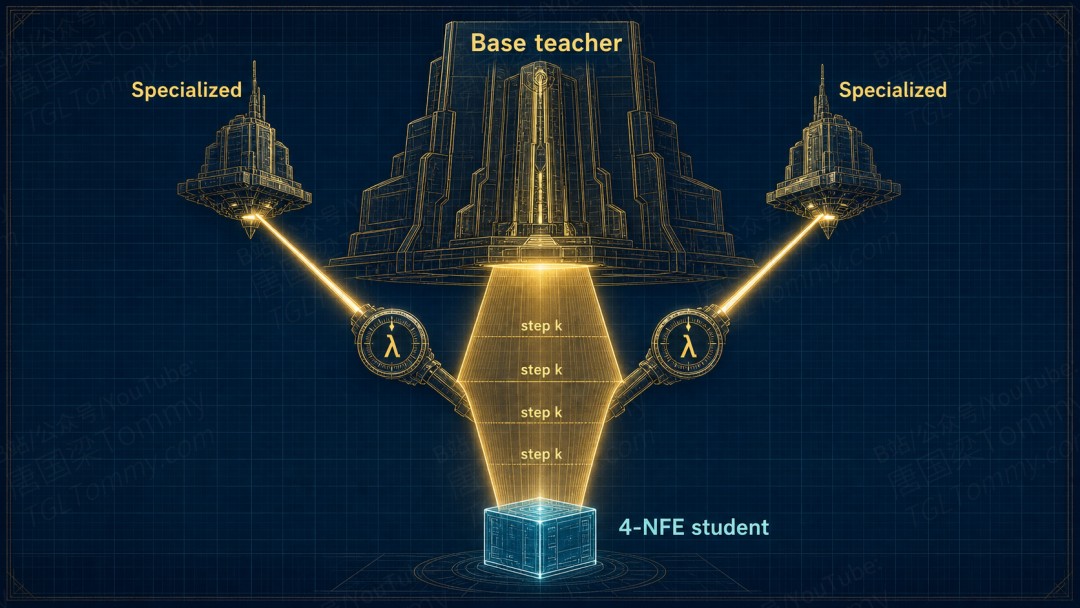
实验给出了否定答案:直接用特化教师做唯一引导,训练会逐渐失稳——前期确实有任务上的提升,但随着迭代推进,生成质量持续劣化,结构错位、保真度下降。论文的假设是:特化教师学到的分布模式更尖、更窄,与学生当前分布之间的 score 场失配被放大;多步学生还能沿着长轨迹慢慢贴近,4 步学生没有这个回旋余地,直接被带崩。
他们的解法叫逐步多教师引导(step-wise multi-teacher guidance):不再固定一位老师,而是把 DMD 里的"真实分布 score"换成多位教师的加权组合——基座教师充当稳定的分布锚点,特化教师按学生所处的蒸馏步数和任务条件,选择性地注入专长。权重随步数与条件动态分配,总和为一。

效果立竿见影:训练全程稳定,而且学生真的继承了多位教师的互补能力。最终的 Qwen-Image-Flash-T2I 只用 4 步,在他们构建的 T2I-Bench 上拿到 Gemini 3.1 Pro 评分 3.56、GPT 5.5 评分 4.15,整体排名超过了 80 步的基座教师(3.41 / 4.09),仅次于 80 步的特化教师。20 倍的采样压缩,换来的不是能力打折,而是排位上升。
这个策略还有个工程上的好处:它不改原始目标函数、不加额外模块,任何在某个下游任务上强的教师都能即插即用地挂进来。
反直觉三:学编辑,反而把生成练强了
第三个维度针对统一模型的现实需求:一个模型既要文生图,又要做指令编辑,两类数据怎么配比?

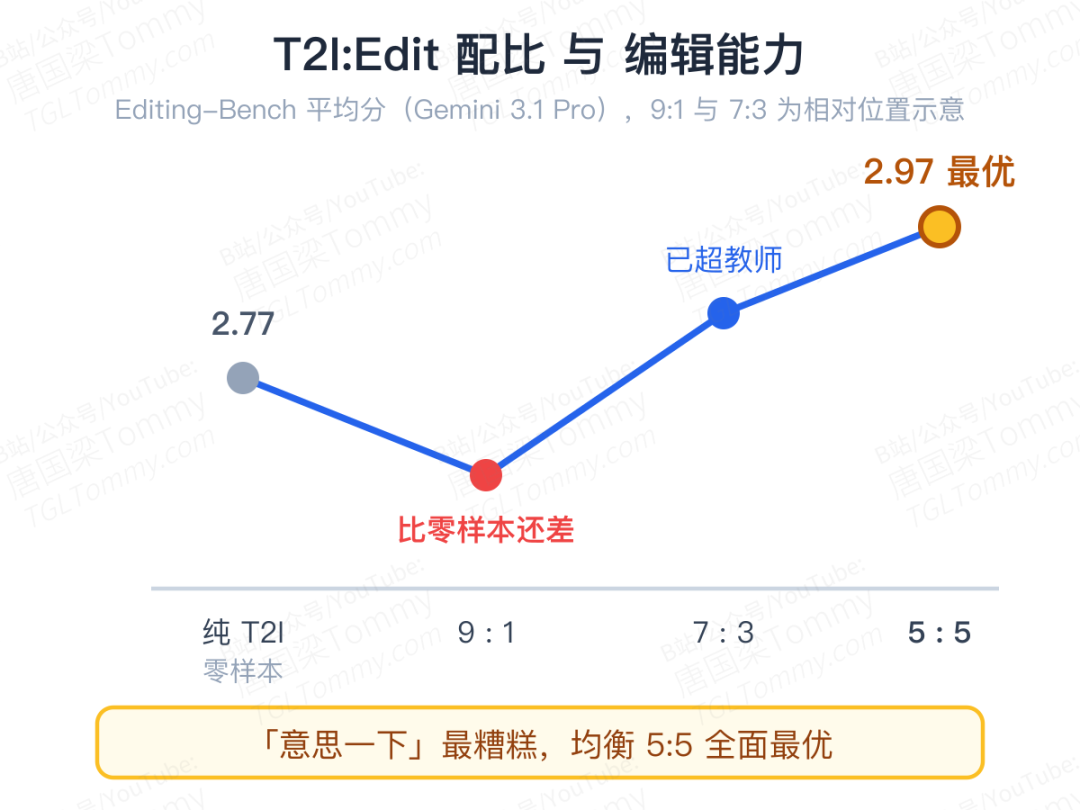
团队固定总训练预算,只调 T2I 与编辑数据的比例,试了 9:1、7:3、5:5 三档,在自建的 Editing-Bench(1500 个案例、六大编辑类别)上评测。结果再次不按常理出牌:
- 只蒸 T2I 的学生零样本也带一点编辑能力——底子来自基座模型——但残缺不全,文字编辑尤其弱;
- 9:1 这种"意思一下"的掺法最糟糕,居然比完全不加编辑数据的零样本基线还差——稀疏的编辑信号不足以形成稳定的学习梯度,反而成了噪声;
- 5:5 均衡配比全面最优,Gemini 评分从零样本的 2.77 提到 2.97,GPT 5.5 从 3.28 提到 3.41,超过或追平了任务特化教师。
最意外的是反向影响:加了编辑数据之后,所有联合蒸馏的学生在 T2I 生成上的得分都高于纯 T2I 蒸馏的基线。编辑任务要求模型理解细粒度指令、定位目标区域、保持无关内容不动——这些视觉-文本对齐能力,恰恰也是文生图的底层素质。编辑数据没有挤占生成能力,反而成了它的辅助训练信号。
这篇论文真正想说什么
把三条线索串起来,论文的中心论点很清晰:少步蒸馏是一个系统工程,目标函数只是其中一环。同样的 DMD 损失,配上不同的数据、教师与任务结构,学生表现天差地别。社区过去把绝大多数注意力放在损失函数的创新上,而真正决定生产级模型蒸馏成败的配方问题,长期被当作不值得写进论文的"调参细节"。

这也是这篇论文的价值所在:它把"调参细节"升格成了可被系统研究、有可复用结论的科学问题,并附带开出了两个针对性的评测基准(T2I-Bench 1800 例、Editing-Bench 1500 例,用 Gemini 3.1 Pro 和 GPT 5.5 做自动偏好评测)。对任何想把大模型蒸馏落地的团队,这六条 takeaway 几乎可以直接抄作业。
写在最后
这篇论文最值得带走的不是某个具体数字,而是一种姿态的转变:当所有人都在公式层面内卷时,Qwen 团队证明了把训练流程当成一等公民来研究,收益可能比再发明一个损失函数大得多。
"更多数据、更强教师、更直接的监督"这三条深度学习的朴素直觉,在少步蒸馏的世界里全部失效。学生容量有限、轨迹只有 4 步,此时教学的艺术不在于老师有多强,而在于课程表怎么排。
这听起来像教育学,但它现在是实打实的工程科学。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-06,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号