
使用python爬取Reddit数据出现错误?
from selenium import webdriver
from selenium.common.exceptions import TimeoutException, NoSuchElementException, NoSuchWindowException
from selenium.webdriver.firefox.options import Options
from selenium.webdriver.firefox.firefox_profile import FirefoxProfile
import time
from pathlib import Path
from selenium.webdriver.support.ui import WebDriverWait#等待
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from src import utils
class Reddit_Spider:
def __init__(self,exp_dir,dark_keywords):
self.exp = Path(exp_dir)
self.exp.mkdir(parents=True, exist_ok=True)
self.start_url="https://www.reddit.com/search?q="
self.dark_keywords = dark_keywords
def get_html(self, url): # 发送请求,获取响应
#首先,它创建了一个FirefoxOptions对象,该对象用于配置和自定义Firefox浏览器的选项。
options = Options()
#这一行设置了Firefox浏览器的二进制文件位置。具体来说,binary_location属性被设置为指向firefox.exe可执行文件的路径。
options.binary_location = r'D:\洋葱\Tor Browser\Browser\firefox.exe'#将启动文件设置为tor的firefox.exe的启动路径。
#在我反复的测试下发现tor的firefox.exe的配置文件的参数和正常火狐的不一样。故我们需要将配置文件的路径传给我们的selenium。
profile = FirefoxProfile(r'D:\洋葱\Tor Browser\Browser\TorBrowser\Data\Browser\profile.default')#配置文件的路径
driver = webdriver.Firefox(executable_path=r'D:\洋葱\Tor Browser\Browser\geckodriver.exe', options=options,firefox_profile= profile)
time.sleep(20)
driver.get(url)
time.sleep(10)
return driver
def read_keywords_from_file(self):
with open(self.keywords_file, 'r') as file:
keywords = [line.strip() for line in file]
return keywords
def search_by_keywords(self, driver, keyword):
search_box = driver.find_element(By.XPATH, '//span[@class="input-container"]')
search_box.clear()
search_box.send_keys(keyword)
search_box.submit()
time.sleep(5)
def get_data(self, driver):
string_data = []
reddit = driver.find_elements(By.XPATH, '//reddit-feed[@label="search-results-page-tab-posts"]')
for reddit in reddit:
tweet_text = reddit.find_element(By.XPATH, './/faceplate-tracker/post-consume-tracker/div/faceplate-tracker/a').text
user_info = reddit.find_element(By.XPATH, './/faceplate-tracker/post-consume-tracker/div/div/span/shreddit-async-loader/faceplate-hovercard/faceplate-tracker/a').text
string_data.append({"tweet_text": tweet_text, "user_info": user_info})
return string_data
def save_data(self, data,keyword):
output_corpus = self.exp / ('corpus_Reddit')
output_corpus.mkdir(parents=True, exist_ok=True)
print(data)
utils.CsvFile.dumplist_zhengban(data, str(output_corpus / f'Reddit_data_corpus_{keyword}.csv'))
def run(self):
driver = self.get_html(self.start_url)
dark_keywords = self.dark_keywords
for keyword in dark_keywords:
self.search_by_keywords(driver,keyword)
data = self.get_data(driver)
self.save_data(data,keyword)
if __name__ == '__main__':
exp = '../../experiments'
dark_keywords = 'euphemism_answer_drug.txt'
dark_keywords_spider = Reddit_Spider(exp_dir=exp,dark_keywords=dark_keywords)
dark_keywords_spider.run()出现错误并且Tor浏览器显示无法连接
E:\selenium_scraper\src\corpus_collection\zhengbanzhongwen_spider.py:25: DeprecationWarning: firefox_profile has been deprecated, please use an Options object
profile = FirefoxProfile(r'D:\洋葱\Tor Browser\Browser\TorBrowser\Data\Browser\profile.default')#配置文件的路径
E:\selenium_scraper\src\corpus_collection\zhengbanzhongwen_spider.py:26: DeprecationWarning: executable_path has been deprecated, please pass in a Service object
driver = webdriver.Firefox(executable_path=r'D:\洋葱\Tor Browser\Browser\geckodriver.exe', options=options,firefox_profile= profile)
E:\selenium_scraper\src\corpus_collection\zhengbanzhongwen_spider.py:26: DeprecationWarning: firefox_profile has been deprecated, please pass in an Options object
driver = webdriver.Firefox(executable_path=r'D:\洋葱\Tor Browser\Browser\geckodriver.exe', options=options,firefox_profile= profile)
Traceback (most recent call last):
File "E:\selenium_scraper\src\corpus_collection\zhengbanzhongwen_spider.py", line 141, in <module>
changanbuye_spider.run()
File "E:\selenium_scraper\src\corpus_collection\zhengbanzhongwen_spider.py", line 130, in run
driver = self.get_html(self.start_url)
File "E:\selenium_scraper\src\corpus_collection\zhengbanzhongwen_spider.py", line 28, in get_html
driver.get(url)
File "E:\Anaconda2\envs\my_env2\lib\site-packages\selenium\webdriver\remote\webdriver.py", line 441, in get
self.execute(Command.GET, {'url': url})
File "E:\Anaconda2\envs\my_env2\lib\site-packages\selenium\webdriver\remote\webdriver.py", line 429, in execute
self.error_handler.check_response(response)
File "E:\Anaconda2\envs\my_env2\lib\site-packages\selenium\webdriver\remote\errorhandler.py", line 243, in check_response
raise exception_class(message, screen, stacktrace)
selenium.common.exceptions.WebDriverException: Message: Failed to decode response from marionette
Process finished with exit code 1
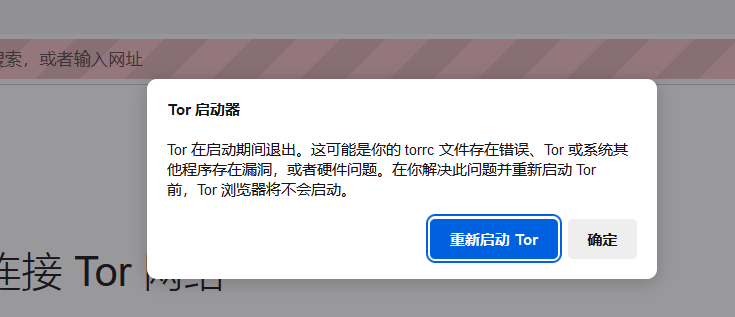
是什么原因造成的
回答
和开发者交流更多问题细节吧,去 写回答
相关文章
相似问题
相关问答用户
请输入您想邀请的人
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号