
理解为什么AWS弹力搜索GC (年轻人和老年人)持续上升,而记忆压力不是
我试图理解我的AWS垃圾收集时间是否有问题,但我发现的所有与内存相关的问题都与内存压力有关,这似乎是OKish。
因此,当我在环境上运行负载测试时,我观察到所有GC收集时间指标都在不断上升,例如:
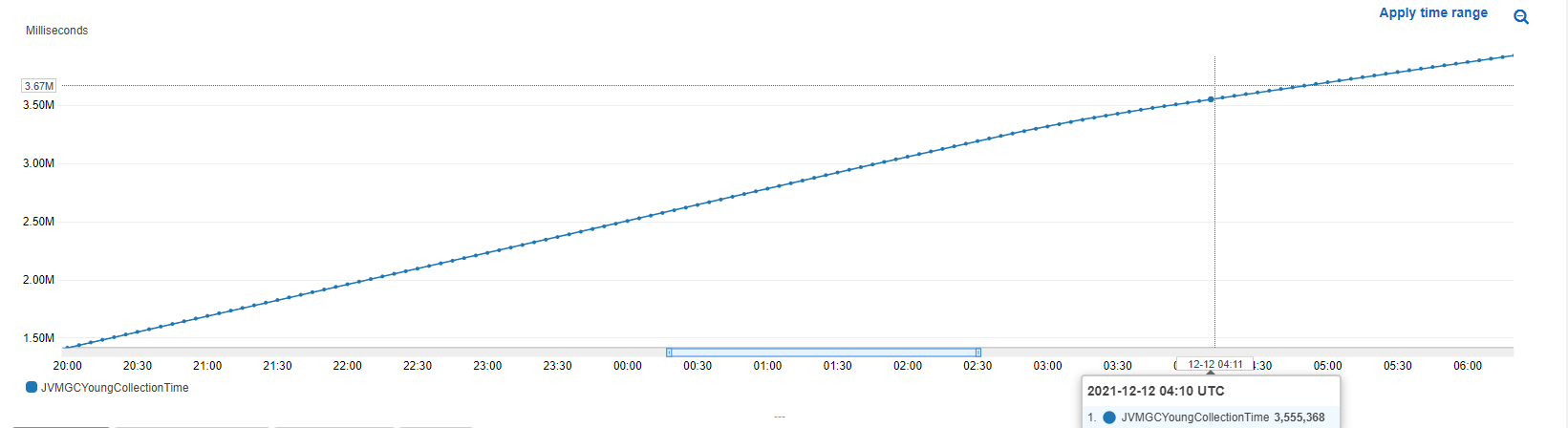
但是当我看记忆压力时,我发现我并没有超过75%的分数(而是接近.)根据文件将触发一个并发的标记&扫描。

因此,我担心,一旦我增加更多的负载或运行一个更长的测试,我可能会看到真正的问题,将对我的环境产生影响。我在这里有什么问题吗?当我不能接受内存转储和看到正在发生的事情时,我应该如何接近上升的GC时间?
回答 2
Stack Overflow用户
发布于 2021-12-21 11:56:39
我向AWS技术支持发送了一个查询,与任何直观的行为相反,Elasticsearch中的Young和Old和count的值是累积的。这意味着该值不断增加,并且在节点删除或节点重新启动之前不会降至0。
Stack Overflow用户
发布于 2021-12-16 14:14:17
顶部的图表报告聚合GC收集时间,这是从GarbageCollectorMXBean获得的。它继续增加,因为每一个年轻一代的收集增加了。在下面的图表中,你可以看到很多年轻一代的收藏正在发生。
在任何web应用程序(这就是OpenSearch集群)中都需要年轻一代的集合:您不断地发出请求(查询或更新),而这些请求会产生垃圾。
我建议查看主要的收集统计数据。在我使用OpenSearch的经验中,当您执行大量更新时(可能是合并索引的结果),就会发生这种情况。但是,除非您不断地更新集群,否则它们应该很少出现。
如果您确实经历了内存压力,唯一真正的解决方案是移动到更大的节点大小。添加节点可能不会有帮助,因为索引在节点之间被分割。
https://stackoverflow.com/questions/70376475
复制相似问题
腾讯云开发者
