
TPOT和Dask-分布式,当2连接到调度程序时,只使用一台工作机器?
问题描述
我刚开始使用TPOT运行dask-distributed (虽然在一台机器上对TPOT相当熟悉)。我试图设置两台工作机器(不同的计算机)来处理我的TPOT运行,但是实际上只有一个工作人员在做任何事情,即使这两台机器都连接到调度程序。
步骤已采取/复制 Windows 10,Python3.7.9,TPOT==0.11.7,scikit=1.0.2,dask==2022.2.0,distributed==2022.2.0,numpy==1.21.4,pandas==1.2.5
在我的主计算机上启动一个Powershell窗口,该窗口也将运行脚本(我确信命令提示符也会这样做)。运行命令dask-scheduler
- I的
- ,打开第二个Powershell窗口并运行命令
dask-worker tcp://127.0.0.1:8786。这将主计算机连接到调度程序(作为工作人员在localhost上运行)。
- I在我的第二台计算机上打开一个Powershell窗口并运行命令
dask-worker tcp://172.16.1.113:8786。这将第二台计算机连接到调度程序.
。
当我引用http://localhost:8787/status或调度程序的Powershell窗口时,我可以看到连接到的工作人员及其资源:
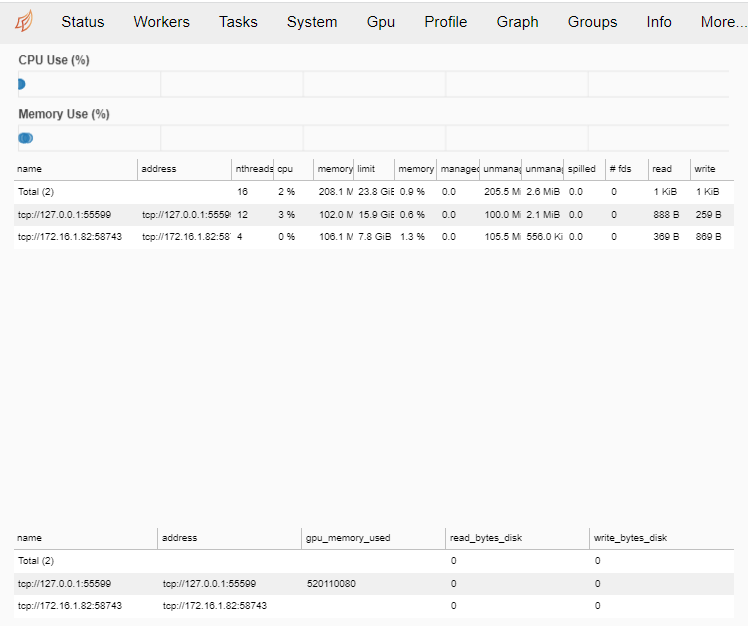
现在,我想运行一个TPOT会话与达斯克。我在下面创建了一个用于调试的最小工作示例代码。此数据集与我的用例数据集的形状非常相似,因此出现了维度/权重失衡:
from dask.distributed import Client, Worker
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split, TimeSeriesSplit
from tpot import TPOTClassifier
# ------------------------------------------------------------------------------------------------ #
# START WORKER/CLIENT IN SCRIPT? #
# ------------------------------------------------------------------------------------------------ #
# client = Client("tcp://172.16.1.113:8786")
# worker = Worker("tcp://172.16.1.113:8786")
# # NOTE: I start a woker in a second command prompt instead as doing it here dones't work.
# ------------------------------------------------------------------------------------------------ #
# MAKE CLASSIFICATION DATASET #
# ------------------------------------------------------------------------------------------------ #
X, y = make_classification(n_samples=100000,
n_features=538,
n_informative=200,
n_classes=3,
weights={0:0.996983388,
1:0.001515257,
2:0.001501355,
},
random_state=42,
)
# ------------------------------------------------------------------------------------------------ #
# TRAIN TEST SPLIT #
# ------------------------------------------------------------------------------------------------ #
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.15,
)
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)
# ------------------------------------------------------------------------------------------------ #
# CREATE THE TPOT CLASSIFIER #
# ------------------------------------------------------------------------------------------------ #
tpot = TPOTClassifier(generations=100,
population_size=40,
offspring_size=None,
mutation_rate=0.9,
crossover_rate=0.1,
scoring='balanced_accuracy',
cv=TimeSeriesSplit(n_splits=3), # Using time series split here
subsample=1.0,
# n_jobs=-1,
max_time_mins=None,
max_eval_time_mins=10, # 5
random_state=None,
# config_dict=classifier_config_dict,
template=None,
warm_start=False,
memory=None,
use_dask=True,
periodic_checkpoint_folder=None,
early_stop=2,
verbosity=2,
disable_update_check=False)
results = tpot.fit(X_train, y_train)
print(tpot.score(X_test, y_test))
tpot.export('tpot_pipeline.py')
# Now check http://localhost:8787/status and resources on both worker machines当我运行这个脚本(在主机器上)时,主机器启动并开始使用它应该使用的所有资源:
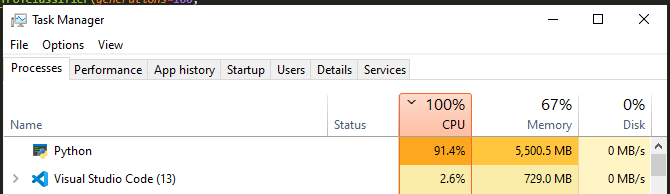
...HOWEVER,第二台机器根本没有被碰过。我没有它的屏幕截图,但CPU和内存在这个过程中根本没有使用。
POSSIBILITIES
- 会不会是内存问题?我的主机有16 8Gb的内存,第二台有8GB。我看到在启动脚本时,主计算机上至少使用了5Gb。也许它超出了第二台机器的极限,因此根本没有被使用?
- ,是不是我没有像上面描述的那样正确地设置它们?注意,我在任何地方都没有使用
Client(),但是当我尝试在脚本中(而不是在主计算机上使用单独的dask-workerPowershell窗口)时,只有第二台机器在工作。因此,我认为这不是内存问题,我只是没有配置properly. - I'm --没有显式地在TPOT中设置
n_jobs,或者在设置工作人员时设置n_procs/n_threads_per_proc(或任何参数)?我认为这将意味着它应该使用所有可用的资源,这显然是它在主要的machine? - Something on上所做的?(因为我刚开始运行集群TPOT ),
回答 1
Stack Overflow用户
发布于 2022-07-20 01:52:35
原谅我!我已经想明白了。
我使用的步骤是正确的,但是我应该启用:
client = Client("tcp://172.16.1.113:8786")
剧本里的行。脚本运行几分钟后,第二台机器上的CPU/RAM就会启动。我想这是某种调度延迟:数据集的大小,但是不管怎么说,它现在正在工作!
https://stackoverflow.com/questions/73045121
复制相似问题
腾讯云开发者
