
模块在Python中找不到“pdf2image”错误
模块在Python中找不到“pdf2image”错误
提问于 2021-07-12 21:03:04
我正在做一个项目,从一堆扫描的PDF文档中提取文本。我正在跟踪这个教程。首先步骤之一是导入模块。我在导入'pdf2image‘时遇到了一些麻烦。对于上下文,我在VS代码的Python终端中使用了一个名为"textExtractor“的Conda环境。我通过运行"Conda“来检查是否安装了pdf2image,并且它看起来已经安装了。但是,当我运行python脚本时,我会收到一个错误消息:
(textExtractor) textExtractor 回溯(最近一次调用):文件"c:/Users/mhiebing/Documents/GitHub_Repos/MonthlyStatsExtract/PDF_to_Image.py",第1行,从pdf2image导入convert_from_path,convert_from_bytes ModuleNotFoundError:没有名为“pdf2image”的模块
下面是显示pdf2image和错误的屏幕截图:
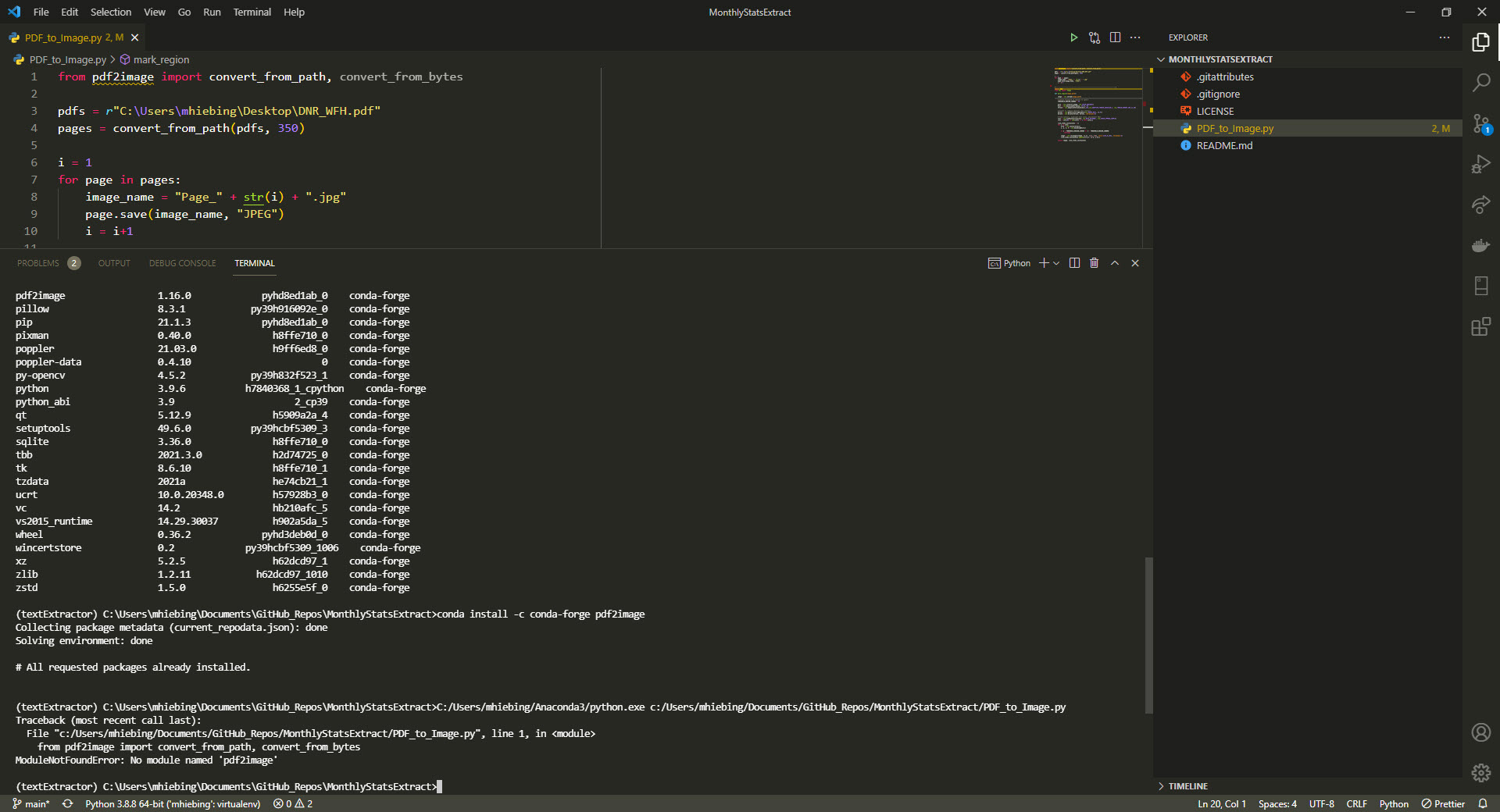
知道出什么问题了吗?
回答 1
Stack Overflow用户
回答已采纳
发布于 2021-07-13 02:33:56
您选择的python解释器不是textExtractor,而是mhiebing。
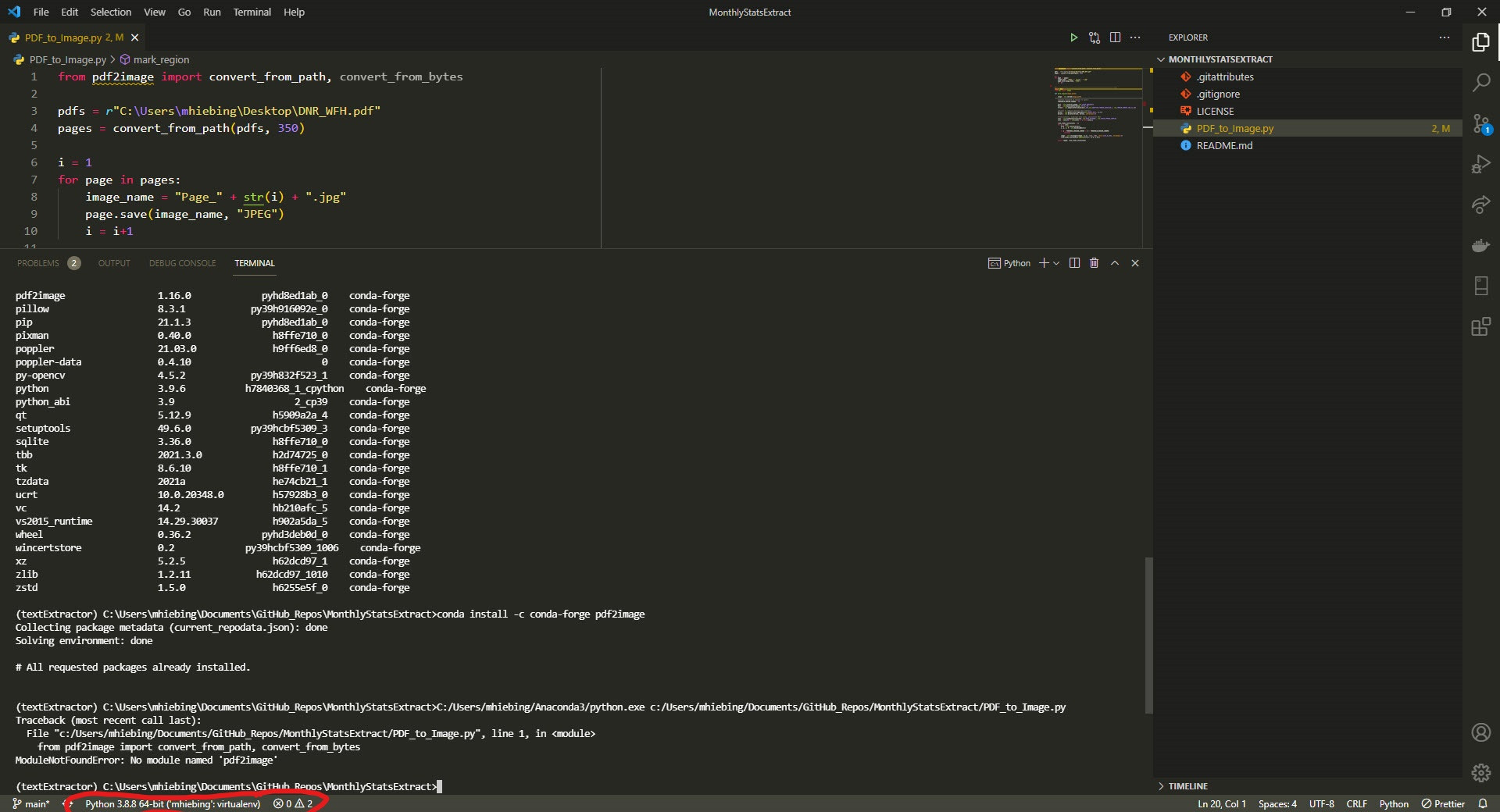
您可以单击解释器的状态栏来切换解释器。您可以参考官方文件获得更多详细信息。
看起来您需要输入命令来运行该文件,因此不建议这样做。您可以单击右上角的绿色三角形按钮或F5来调试它。如果你这样做,你可以找到真实的环境,你正在采取。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/68353849
复制相关文章
相似问题
腾讯云开发者
