
执行计划中估计的极高行数
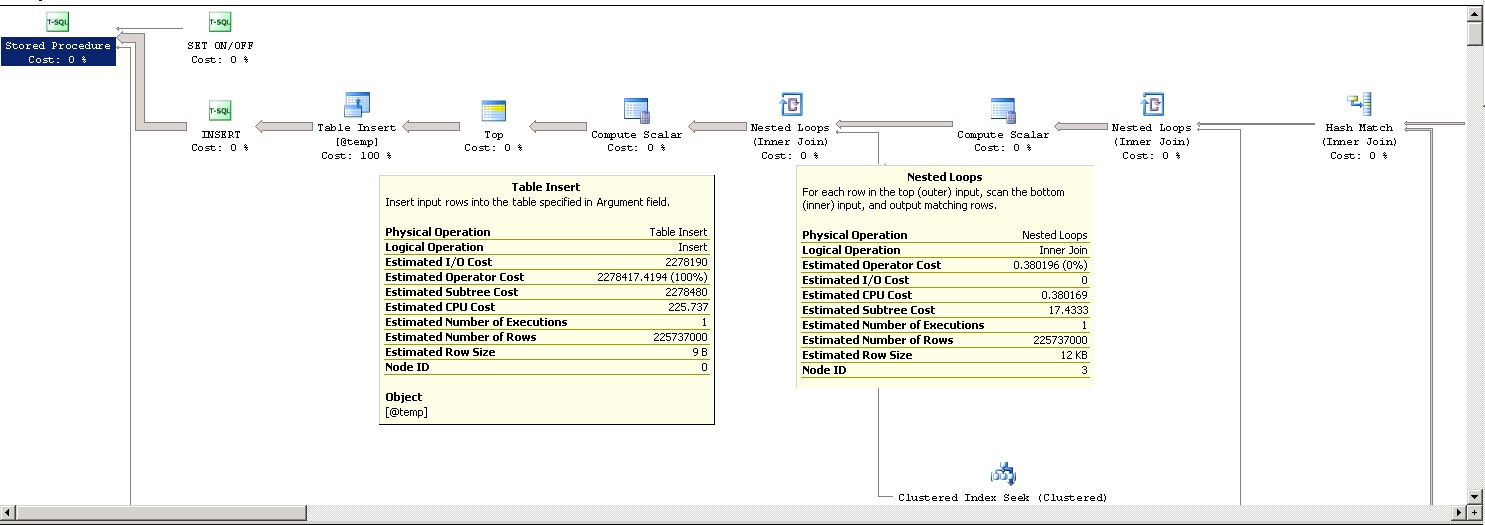
我有一个存储过程,在生产过程中运行速度比在阶段运行慢10倍。我看了一下执行计划,我注意到的第一件事是表插入(进入表变量@temp)的成本在生产中是100%,在阶段中是2%。
估计生产中的行数显示了近2亿行!但在分期方面只有33人左右。
虽然产品DB运行在Server 2008 R2上,而暂存是Server 2012,但我认为这种差异不会导致这样的问题。
造成如此巨大差异的原因是什么?
更新
增加了执行计划。如您所见,大量的估计行出现在嵌套的循环(内部联接)中,但它所做的只是对另一个表进行聚集索引查找。
UPDATED2
包含plan.xml的计划XML的链接
和Sentry计划资源管理器视图(显示估计计数)
回答 4
Stack Overflow用户
发布于 2015-07-09 19:49:47
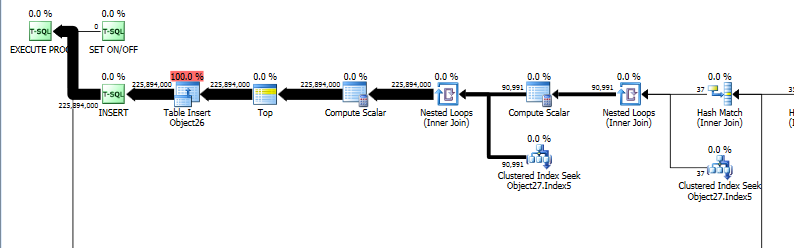
在我看来这是个窃听器。
有一个估计的90,991.1行进入嵌套循环。
正在查找的表的基数是24,826。
如果没有列的统计信息,并且使用相等运算符,这意味着SQL无法知道列的密度,因此它使用10 %的固定值。
90,991.1 * 24,826 * 10% = 225,894,504.86,它非常接近您估计的行225,894,000
但是执行计划显示,每个搜索只估计1行。不是从上面的24,826。
所以这些数字加起来就不一样了。我假设它从最初的10%的球场估计开始,然后调整到1,因为存在一个唯一的约束,而没有对其他分支进行补偿调整。
我看到该查找是在调用标量UDF [dbo].[TryConvertGuid] I能够在Server 2005上再现类似的行为,在嵌套循环的内部查找唯一的索引(谓词是UDF )产生的结果是,在联接之外估计的行数远远大于通过乘以估计查找行数*估计的执行数。
但是,在您的示例中,计划中问题部分左侧的操作符非常简单,并且对行数不敏感(行计数顶级运算符或insert运算符都不会改变),因此我认为这种怪癖不会对您注意到的性能问题负责。
关于另一个答案的注释中的一点,即切换到临时表有助于插入的性能,这可能是因为它允许计划的读取部分并行操作(插入到表变量将阻止此操作)。
Stack Overflow用户
发布于 2015-07-08 21:21:47
在生产数据库上运行EXEC sp_updatestats;。这将更新所有表的统计信息。如果你的统计数据搞砸了,它可能会产生更多理智的执行计划。
Stack Overflow用户
发布于 2015-07-08 21:43:44
请不要运行EXEC sp_updatestats;在大型系统上,它可能需要几个小时或几天才能完成。您可能要做的是查看正在生产中使用的查询计划。试着看看它是否有一个可以使用和不被使用的索引。尝试重新构建索引(其副作用是重新构建索引上的统计信息)。重新生成之后,查看查询计划,并注意它是否正在使用索引。也许您需要在表中添加一个索引。表有聚集索引吗?
通常情况下,自2005年以来,SQL server很好地管理自己的统计信息。唯一需要显式更新统计信息的情况是,如果您知道如果Server使用索引,则执行查询的速度会快得多,但它不会执行。您可能希望运行(每晚或每周)脚本,这些脚本自动测试每个表和每个索引,以查看索引是否需要重新整理或重建(取决于它的支离破碎程度)。这类脚本(在大型活动OLTP系统上)r可能需要很长时间才能运行,当您有一个窗口运行它时,您应该仔细考虑。这个脚本有很多版本,但我经常使用这个版本:https://msdn.microsoft.com/en-us/library/ms189858.aspx
https://stackoverflow.com/questions/31303831
复制相似问题
腾讯云开发者
